 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Fine-Tuning Diffusion Transformers via Dynamic Patch Sampling and Block Skipping
Mar 21, 2026Diffusion Transformers (DiTs) have significantly enhanced text-to-image (T2I) generation quality, enabling high-quality personalized content creation. However, fine-tuning these models requires substantial computational complexity and memory, limiting practical deployment under resource constraints. To tackle these challenges, we propose a memory-efficient fine-tuning framework called DiT-BlockSkip, integrating timestep-aware dynamic patch sampling and block skipping by precomputing residual features. Our dynamic patch sampling strategy adjusts patch sizes based on the diffusion timestep, then resizes the cropped patches to a fixed lower resolution. This approach reduces forward & backward memory usage while allowing the model to capture global structures at higher timesteps and fine-grained details at lower timesteps. The block skipping mechanism selectively fine-tunes essential transformer blocks and precomputes residual features for the skipped blocks, significantly reducing training memory. To identify vital blocks for personalization, we introduce a block selection strategy based on cross-attention masking. Evaluations demonstrate that our approach achieves competitive personalization performance qualitatively and quantitatively, while reducing memory usage substantially, moving toward on-device feasibility (e.g., smartphones, IoT devices) for large-scale diffusion transformers.
Steering Guidance for Personalized Text-to-Image Diffusion Models
Aug 01, 2025Personalizing text-to-image diffusion models is crucial for adapting the pre-trained models to specific target concepts, enabling diverse image generation. However, fine-tuning with few images introduces an inherent trade-off between aligning with the target distribution (e.g., subject fidelity) and preserving the broad knowledge of the original model (e.g., text editability). Existing sampling guidance methods, such as classifier-free guidance (CFG) and autoguidance (AG), fail to effectively guide the output toward well-balanced space: CFG restricts the adaptation to the target distribution, while AG compromises text alignment. To address these limitations, we propose personalization guidance, a simple yet effective method leveraging an unlearned weak model conditioned on a null text prompt. Moreover, our method dynamically controls the extent of unlearning in a weak model through weight interpolation between pre-trained and fine-tuned models during inference. Unlike existing guidance methods, which depend solely on guidance scales, our method explicitly steers the outputs toward a balanced latent space without additional computational overhead. Experimental results demonstrate that our proposed guidance can improve text alignment and target distribution fidelity, integrating seamlessly with various fine-tuning strategies.
Domain Agnostic Few-shot Learning for Speaker Verification
Jun 28, 2022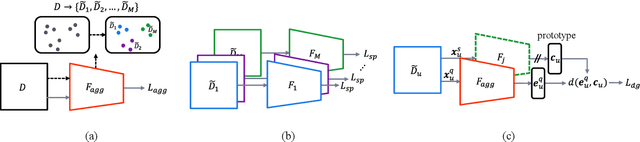
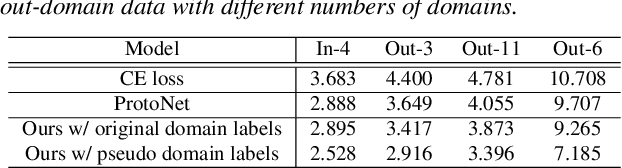
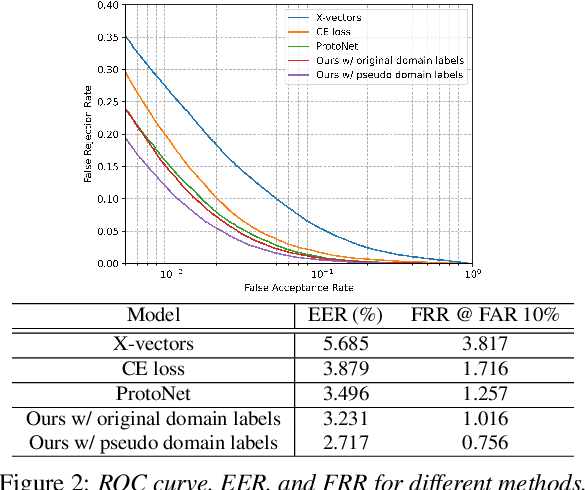
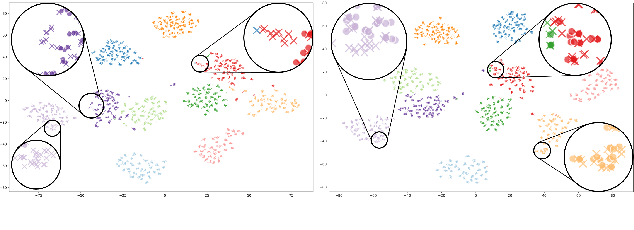
Deep learning models for verification systems often fail to generalize to new users and new environments, even though they learn highly discriminative features. To address this problem, we propose a few-shot domain generalization framework that learns to tackle distribution shift for new users and new domains. Our framework consists of domain-specific and domain-aggregation networks, which are the experts on specific and combined domains, respectively. By using these networks, we generate episodes that mimic the presence of both novel users and novel domains in the training phase to eventually produce better generalization. To save memory, we reduce the number of domain-specific networks by clustering similar domains together. Upon extensive evaluation on artificially generated noise domains, we can explicitly show generalization ability of our framework. In addition, we apply our proposed methods to the existing competitive architecture on the standard benchmark, which shows further performance improvements.
SubSpectral Normalization for Neural Audio Data Processing
Mar 25, 2021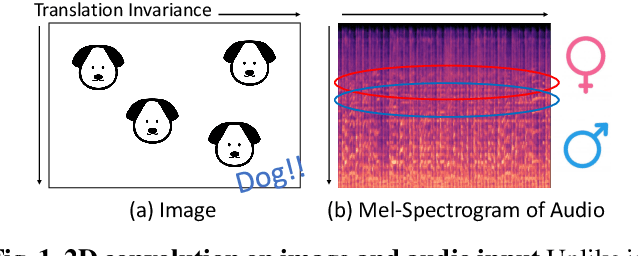

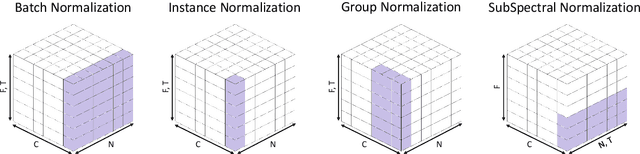
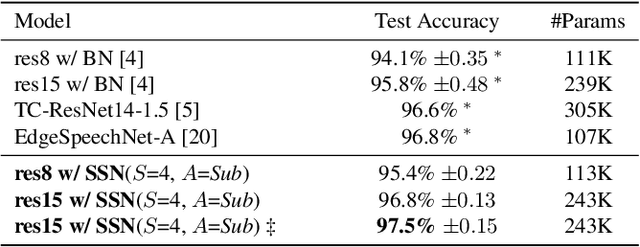
Convolutional Neural Networks are widely used in various machine learning domains. In image processing, the features can be obtained by applying 2D convolution to all spatial dimensions of the input. However, in the audio case, frequency domain input like Mel-Spectrogram has different and unique characteristics in the frequency dimension. Thus, there is a need for a method that allows the 2D convolution layer to handle the frequency dimension differently. In this work, we introduce SubSpectral Normalization (SSN), which splits the input frequency dimension into several groups (sub-bands) and performs a different normalization for each group. SSN also includes an affine transformation that can be applied to each group. Our method removes the inter-frequency deflection while the network learns a frequency-aware characteristic. In the experiments with audio data, we observed that SSN can efficiently improve the network's performance.
End-to-End Lane Marker Detection via Row-wise Classification
May 06, 2020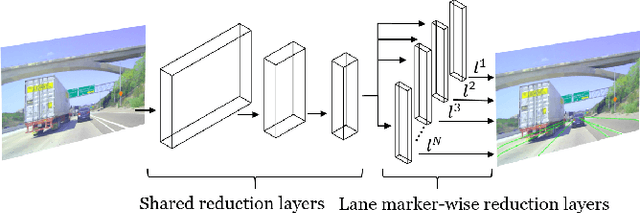
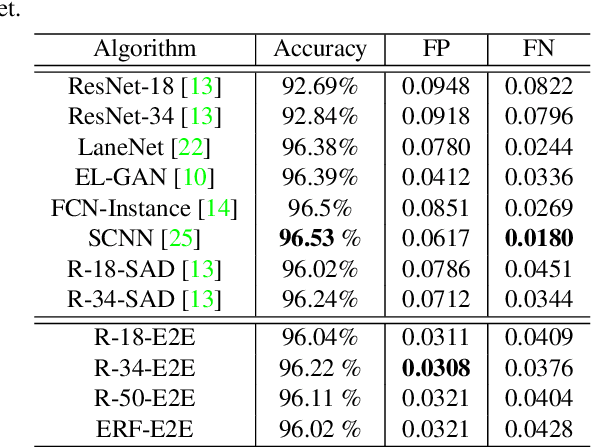
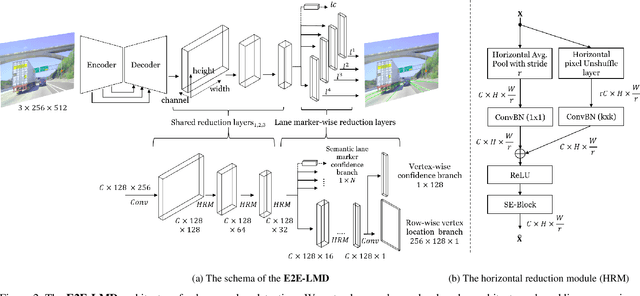
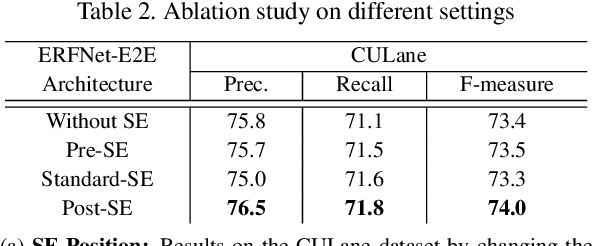
In autonomous driving, detecting reliable and accurate lane marker positions is a crucial yet challenging task. The conventional approaches for the lane marker detection problem perform a pixel-level dense prediction task followed by sophisticated post-processing that is inevitable since lane markers are typically represented by a collection of line segments without thickness. In this paper, we propose a method performing direct lane marker vertex prediction in an end-to-end manner, i.e., without any post-processing step that is required in the pixel-level dense prediction task. Specifically, we translate the lane marker detection problem into a row-wise classification task, which takes advantage of the innate shape of lane markers but, surprisingly, has not been explored well. In order to compactly extract sufficient information about lane markers which spread from the left to the right in an image, we devise a novel layer, which is utilized to successively compress horizontal components so enables an end-to-end lane marker detection system where the final lane marker positions are simply obtained via argmax operations in testing time. Experimental results demonstrate the effectiveness of the proposed method, which is on par or outperforms the state-of-the-art methods on two popular lane marker detection benchmarks, i.e., TuSimple and CULane.
Weakly Labeled Sound Event Detection Using Tri-training and Adversarial Learning
Oct 14, 2019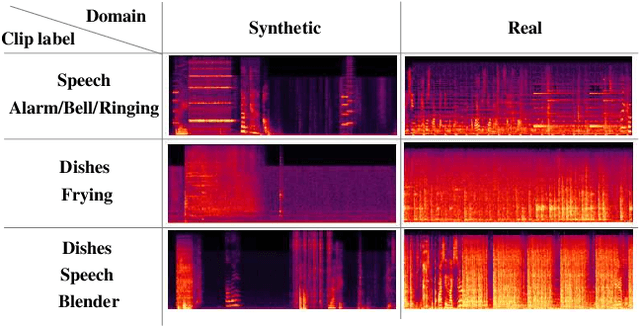
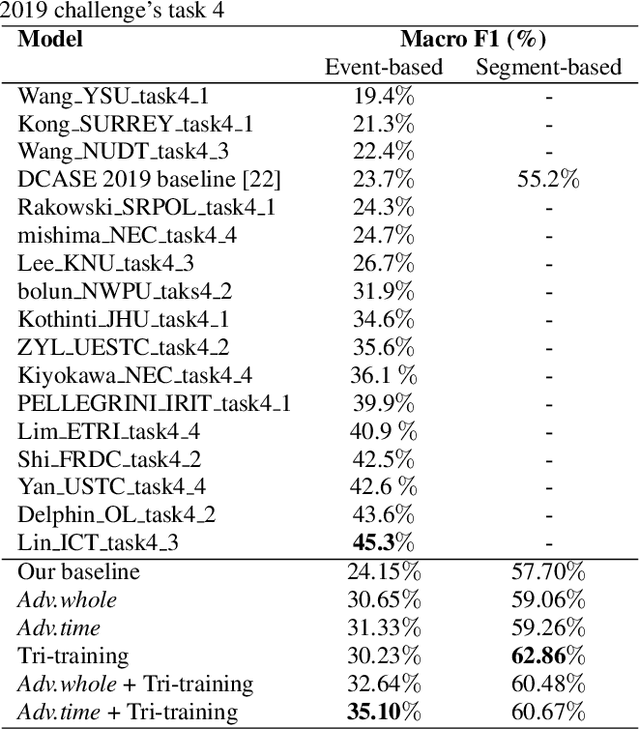
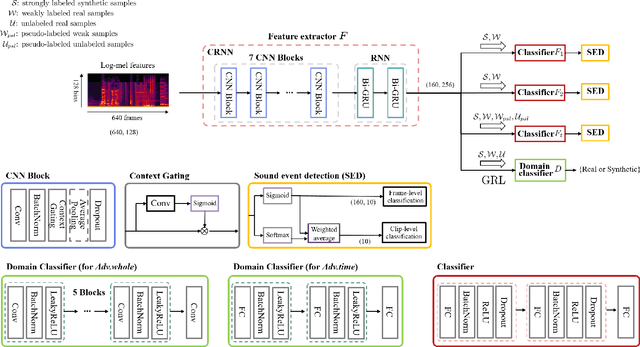
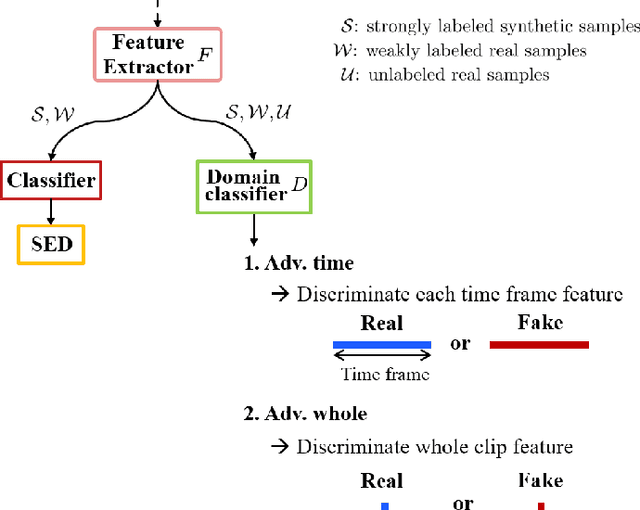
This paper considers a semi-supervised learning framework for weakly labeled polyphonic sound event detection problems for the DCASE 2019 challenge's task4 by combining both the tri-training and adversarial learning. The goal of the task4 is to detect onsets and offsets of multiple sound events in a single audio clip. The entire dataset consists of the synthetic data with a strong label (sound event labels with boundaries) and real data with weakly labeled (sound event labels) and unlabeled dataset. Given this dataset, we apply the tri-training where two different classifiers are used to obtain pseudo labels on the weakly labeled and unlabeled dataset, and the final classifier is trained using the strongly labeled dataset and weakly/unlabeled dataset with pseudo labels. Also, we apply the adversarial learning to reduce the domain gap between the real and synthetic dataset. We evaluated our learning framework using the validation set of the task4 dataset, and in the experiments, our learning framework shows a considerable performance improvement over the baseline model.
Acoustic Scene Classification Based on a Large-margin Factorized CNN
Oct 14, 2019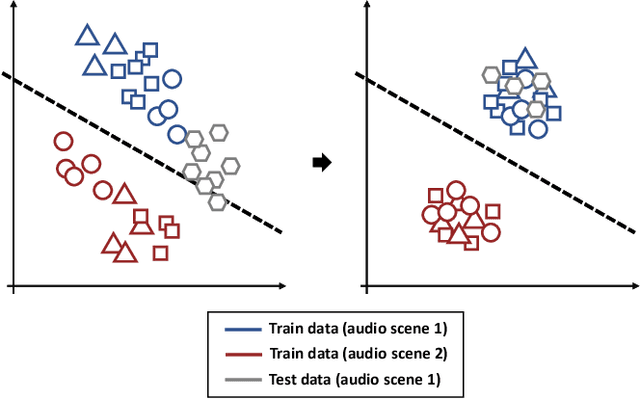
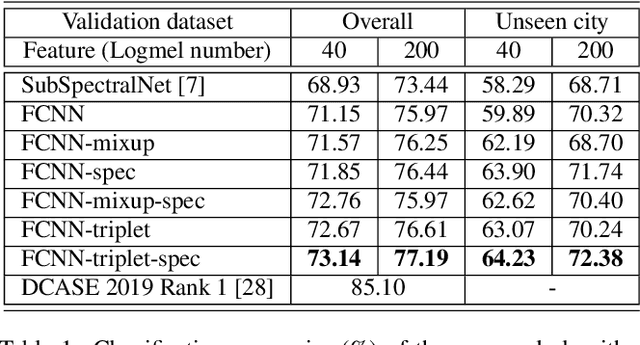
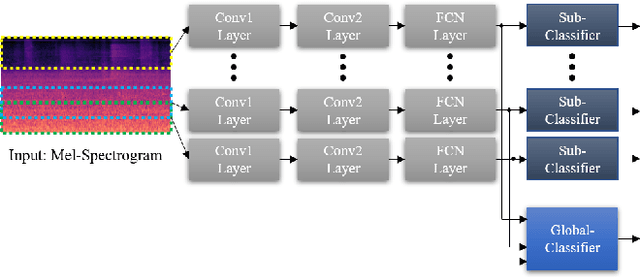
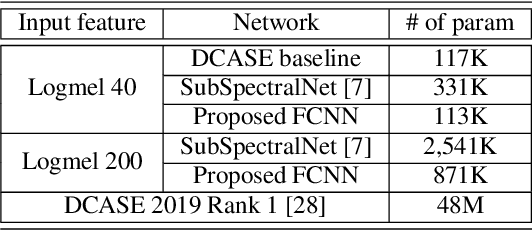
In this paper, we present an acoustic scene classification framework based on a large-margin factorized convolutional neural network (CNN). We adopt the factorized CNN to learn the patterns in the time-frequency domain by factorizing the 2D kernel into two separate 1D kernels. The factorized kernel leads to learn the main component of two patterns: the long-term ambient and short-term event sounds which are the key patterns of the audio scene classification. In training our model, we consider the loss function based on the triplet sampling such that the same audio scene samples from different environments are minimized, and simultaneously the different audio scene samples are maximized. With this loss function, the samples from the same audio scene are clustered independently of the environment, and thus we can get the classifier with better generalization ability in an unseen environment. We evaluated our audio scene classification framework using the dataset of the DCASE challenge 2019 task1A. Experimental results show that the proposed algorithm improves the performance of the baseline network and reduces the number of parameters to one third. Furthermore, the performance gain is higher on unseen data, and it shows that the proposed algorithm has better generalization ability.