 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training and Test-Time Scaling of Generative Agent Behavior Models for Interactive Autonomous Driving
Dec 15, 2025Learning interactive motion behaviors among multiple agents is a core challenge in autonomous driving. While imitation learning models generate realistic trajectories, they often inherit biases from datasets dominated by safe demonstrations, limiting robustness in safety-critical cases. Moreover, most studies rely on open-loop evaluation, overlooking compounding errors in closed-loop execution. We address these limitations with two complementary strategies. First, we propose Group Relative Behavior Optimization (GRBO), a reinforcement learning post-training method that fine-tunes pretrained behavior models via group relative advantage maximization with human regularization. Using only 10% of the training dataset, GRBO improves safety performance by over 40% while preserving behavioral realism. Second, we introduce Warm-K, a warm-started Top-K sampling strategy that balances consistency and diversity in motion selection. Our Warm-K method-based test-time scaling enhances behavioral consistency and reactivity at test time without retraining, mitigating covariate shift and reducing performance discrepancies. Demo videos are available in the supplementary material.
Revisiting Architecture-aware Knowledge Distillation: Smaller Models and Faster Search
Jun 27, 2022



Knowledge Distillation (KD) has recently emerged as a popular method for compressing neural networks. In recent studies, generalized distillation methods that find parameters and architectures of student models at the same time have been proposed. Still, this search method requires a lot of computation to search for architectures and has the disadvantage of considering only convolutional blocks in their search space. This paper introduces a new algorithm, coined as Trust Region Aware architecture search to Distill knowledge Effectively (TRADE), that rapidly finds effective student architectures from several state-of-the-art architectures using trust region Bayesian optimization approach. Experimental results show our proposed TRADE algorithm consistently outperforms both the conventional NAS approach and pre-defined architecture under KD training.
End-to-End Lane Marker Detection via Row-wise Classification
May 06, 2020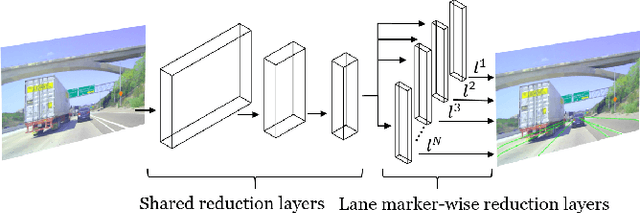
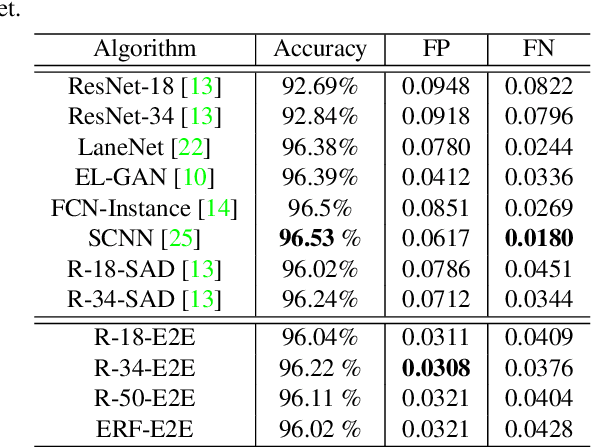
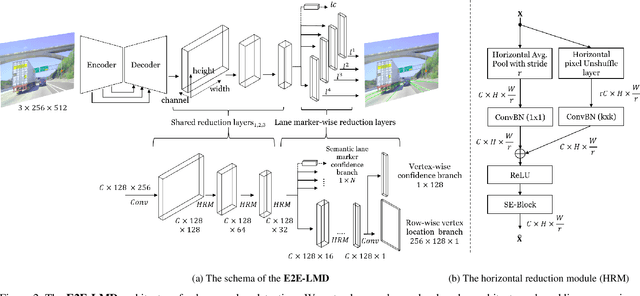
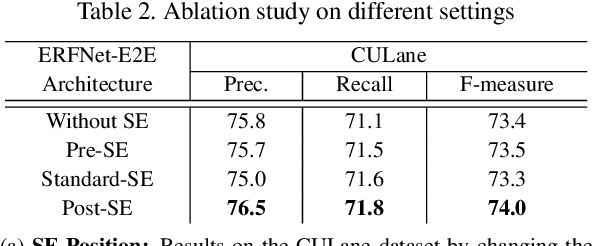
In autonomous driving, detecting reliable and accurate lane marker positions is a crucial yet challenging task. The conventional approaches for the lane marker detection problem perform a pixel-level dense prediction task followed by sophisticated post-processing that is inevitable since lane markers are typically represented by a collection of line segments without thickness. In this paper, we propose a method performing direct lane marker vertex prediction in an end-to-end manner, i.e., without any post-processing step that is required in the pixel-level dense prediction task. Specifically, we translate the lane marker detection problem into a row-wise classification task, which takes advantage of the innate shape of lane markers but, surprisingly, has not been explored well. In order to compactly extract sufficient information about lane markers which spread from the left to the right in an image, we devise a novel layer, which is utilized to successively compress horizontal components so enables an end-to-end lane marker detection system where the final lane marker positions are simply obtained via argmax operations in testing time. Experimental results demonstrate the effectiveness of the proposed method, which is on par or outperforms the state-of-the-art methods on two popular lane marker detection benchmarks, i.e., TuSimple and CULane.
Fine-Grained Neural Architecture Search
Nov 18, 2019



We present an elegant framework of fine-grained neural architecture search (FGNAS), which allows to employ multiple heterogeneous operations within a single layer and can even generate compositional feature maps using several different base operations. FGNAS runs efficiently in spite of significantly large search space compared to other methods because it trains networks end-to-end by a stochastic gradient descent method. Moreover, the proposed framework allows to optimize the network under predefined resource constraints in terms of number of parameters, FLOPs and latency. FGNAS has been applied to two crucial applications in resource demanding computer vision tasks---large-scale image classification and image super-resolution---and demonstrates the state-of-the-art performance through flexible operation search and channel pruning.