 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Neural Architecture Search
Nov 18, 2019



We present an elegant framework of fine-grained neural architecture search (FGNAS), which allows to employ multiple heterogeneous operations within a single layer and can even generate compositional feature maps using several different base operations. FGNAS runs efficiently in spite of significantly large search space compared to other methods because it trains networks end-to-end by a stochastic gradient descent method. Moreover, the proposed framework allows to optimize the network under predefined resource constraints in terms of number of parameters, FLOPs and latency. FGNAS has been applied to two crucial applications in resource demanding computer vision tasks---large-scale image classification and image super-resolution---and demonstrates the state-of-the-art performance through flexible operation search and channel pruning.
Continual Learning by Asymmetric Loss Approximation with Single-Side Overestimation
Aug 08, 2019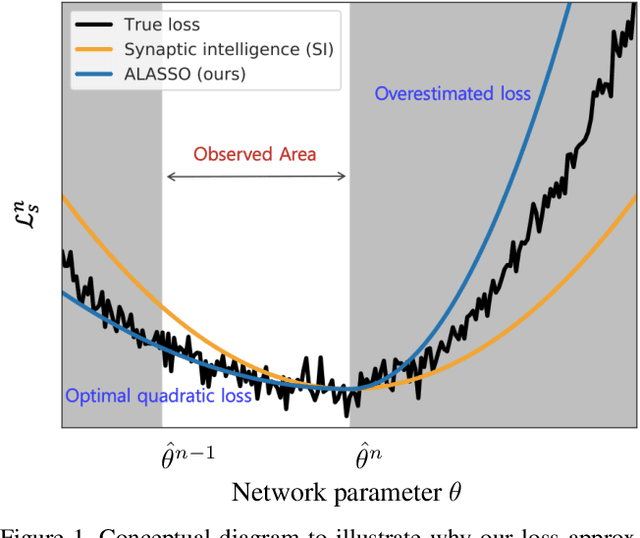



Catastrophic forgetting is a critical challenge in training deep neural networks. Although continual learning has been investigated as a countermeasure to the problem, it often suffers from requirements of additional network components and weak scalability to a large number of tasks. We propose a novel approach to continual learning by approximating a true loss function based on an asymmetric quadratic function with one of its sides overestimated. Our algorithm is motivated by the empirical observation that updates of network parameters affect target loss functions asymmetrically. In the proposed continual learning framework, we estimate an asymmetric loss function for the tasks considered in the past through a proper overestimation of its unobserved side in training new tasks, while deriving the accurate model parameter for the observed side. In contrast to existing approaches, our method is free from side effects and achieves the state-of-the-art results that are even close to the upper-bound performance on several challenging benchmark datasets.
Learning to Forget for Meta-Learning
Jun 13, 2019


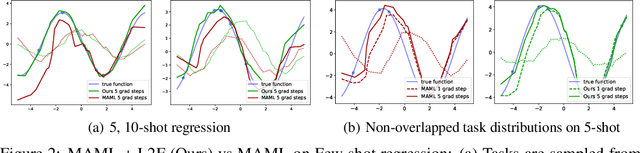
Few-shot learning is a challenging problem where the system is required to achieve generalization from only few examples. Meta-learning tackles the problem by learning prior knowledge shared across a distribution of tasks, which is then used to quickly adapt to unseen tasks. Model-agnostic meta-learning (MAML) algorithm formulates prior knowledge as a common initialization across tasks. However, forcibly sharing an initialization brings about conflicts between tasks and thus compromises the quality of the initialization. In this work, by observing that the extent of compromise differs among tasks and between layers of a neural network, we propose a new initialization idea that employs task-dependent layer-wise attenuation, which we call selective forgetting. The proposed attenuation scheme dynamically controls how much of prior knowledge each layer will exploit for a given task. The experimental results demonstrate that the proposed method mitigates the conflicts and provides outstanding performance as a result. We further show that the proposed method, named L2F, can be applied and improve other state-of-the-art MAML-based frameworks, illustrating its generalizability.