 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Parameter Interference in Model Merging via Sharpness-Aware Fine-Tuning
Apr 20, 2025Large-scale deep learning models with a pretraining-finetuning paradigm have led to a surge of numerous task-specific models fine-tuned from a common pre-trained model. Recently, several research efforts have been made on merging these large models into a single multi-task model, particularly with simple arithmetic on parameters. Such merging methodology faces a central challenge: interference between model parameters fine-tuned on different tasks. Few recent works have focused on designing a new fine-tuning scheme that can lead to small parameter interference, however at the cost of the performance of each task-specific fine-tuned model and thereby limiting that of a merged model. To improve the performance of a merged model, we note that a fine-tuning scheme should aim for (1) smaller parameter interference and (2) better performance of each fine-tuned model on the corresponding task. In this work, we aim to design a new fine-tuning objective function to work towards these two goals. In the course of this process, we find such objective function to be strikingly similar to sharpness-aware minimization (SAM) objective function, which aims to achieve generalization by finding flat minima. Drawing upon our observation, we propose to fine-tune pre-trained models via sharpness-aware minimization. The experimental and theoretical results showcase the effectiveness and orthogonality of our proposed approach, improving performance upon various merging and fine-tuning methods. Our code is available at https://github.com/baiklab/SAFT-Merge.
Find A Winning Sign: Sign Is All We Need to Win the Lottery
Apr 07, 2025



The Lottery Ticket Hypothesis (LTH) posits the existence of a sparse subnetwork (a.k.a. winning ticket) that can generalize comparably to its over-parameterized counterpart when trained from scratch. The common approach to finding a winning ticket is to preserve the original strong generalization through Iterative Pruning (IP) and transfer information useful for achieving the learned generalization by applying the resulting sparse mask to an untrained network. However, existing IP methods still struggle to generalize their observations beyond ad-hoc initialization and small-scale architectures or datasets, or they bypass these challenges by applying their mask to trained weights instead of initialized ones. In this paper, we demonstrate that the parameter sign configuration plays a crucial role in conveying useful information for generalization to any randomly initialized network. Through linear mode connectivity analysis, we observe that a sparse network trained by an existing IP method can retain its basin of attraction if its parameter signs and normalization layer parameters are preserved. To take a step closer to finding a winning ticket, we alleviate the reliance on normalization layer parameters by preventing high error barriers along the linear path between the sparse network trained by our method and its counterpart with initialized normalization layer parameters. Interestingly, across various architectures and datasets, we observe that any randomly initialized network can be optimized to exhibit low error barriers along the linear path to the sparse network trained by our method by inheriting its sparsity and parameter sign information, potentially achieving performance comparable to the original. The code is available at https://github.com/JungHunOh/AWS\_ICLR2025.git
LAN: Learning to Adapt Noise for Image Denoising
Dec 14, 2024

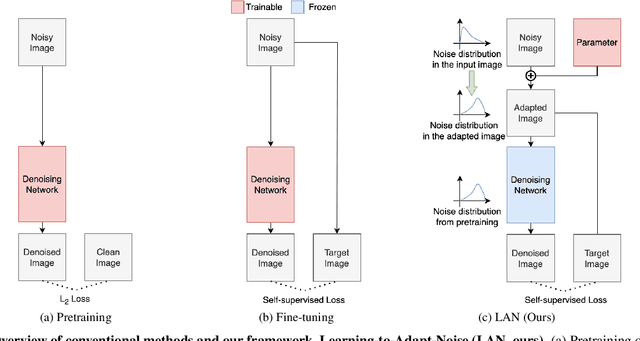

Removing noise from images, a.k.a image denoising, can be a very challenging task since the type and amount of noise can greatly vary for each image due to many factors including a camera model and capturing environments. While there have been striking improvements in image denoising with the emergence of advanced deep learning architectures and real-world datasets, recent denoising networks struggle to maintain performance on images with noise that has not been seen during training. One typical approach to address the challenge would be to adapt a denoising network to new noise distribution. Instead, in this work, we shift our focus to adapting the input noise itself, rather than adapting a network. Thus, we keep a pretrained network frozen, and adapt an input noise to capture the fine-grained deviations. As such, we propose a new denoising algorithm, dubbed Learning-to-Adapt-Noise (LAN), where a learnable noise offset is directly added to a given noisy image to bring a given input noise closer towards the noise distribution a denoising network is trained to handle. Consequently, the proposed framework exhibits performance improvement on images with unseen noise, displaying the potential of the proposed research direction. The code is available at https://github.com/chjinny/LAN
Deep Variational Bayesian Modeling of Haze Degradation Process
Dec 04, 2024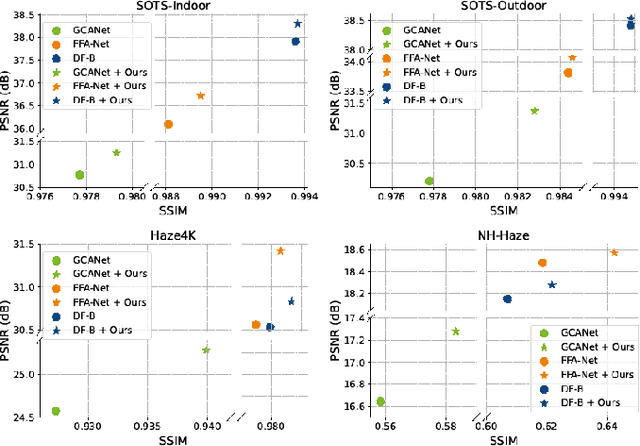
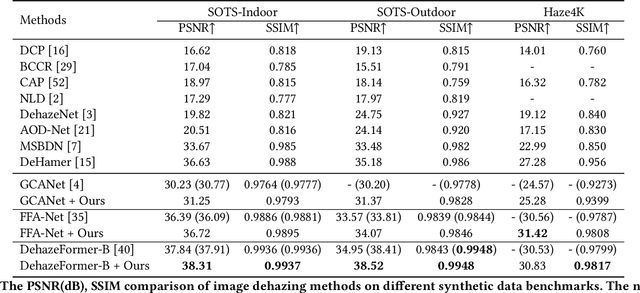
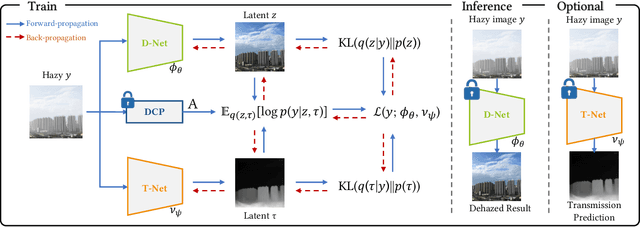
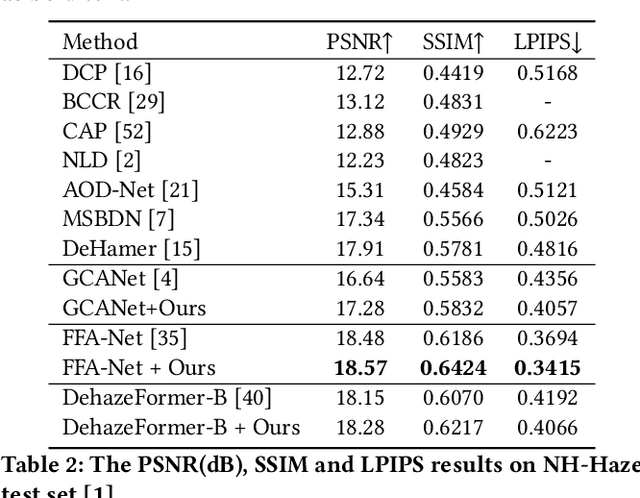
Relying on the representation power of neural networks, most recent works have often neglected several factors involved in haze degradation, such as transmission (the amount of light reaching an observer from a scene over distance) and atmospheric light. These factors are generally unknown, making dehazing problems ill-posed and creating inherent uncertainties. To account for such uncertainties and factors involved in haze degradation, we introduce a variational Bayesian framework for single image dehazing. We propose to take not only a clean image and but also transmission map as latent variables, the posterior distributions of which are parameterized by corresponding neural networks: dehazing and transmission networks, respectively. Based on a physical model for haze degradation, our variational Bayesian framework leads to a new objective function that encourages the cooperation between them, facilitating the joint training of and thereby boosting the performance of each other. In our framework, a dehazing network can estimate a clean image independently of a transmission map estimation during inference, introducing no overhead. Furthermore, our model-agnostic framework can be seamlessly incorporated with other existing dehazing networks, greatly enhancing the performance consistently across datasets and models.
* Published in CIKM 2023, 10 pages, 9 figures
CLOSER: Towards Better Representation Learning for Few-Shot Class-Incremental Learning
Oct 08, 2024Aiming to incrementally learn new classes with only few samples while preserving the knowledge of base (old) classes, few-shot class-incremental learning (FSCIL) faces several challenges, such as overfitting and catastrophic forgetting. Such a challenging problem is often tackled by fixing a feature extractor trained on base classes to reduce the adverse effects of overfitting and forgetting. Under such formulation, our primary focus is representation learning on base classes to tackle the unique challenge of FSCIL: simultaneously achieving the transferability and the discriminability of the learned representation. Building upon the recent efforts for enhancing transferability, such as promoting the spread of features, we find that trying to secure the spread of features within a more confined feature space enables the learned representation to strike a better balance between transferability and discriminability. Thus, in stark contrast to prior beliefs that the inter-class distance should be maximized, we claim that the closer different classes are, the better for FSCIL. The empirical results and analysis from the perspective of information bottleneck theory justify our simple yet seemingly counter-intuitive representation learning method, raising research questions and suggesting alternative research directions. The code is available at https://github.com/JungHunOh/CLOSER_ECCV2024.
CoAPT: Context Attribute words for Prompt Tuning
Jul 18, 2024



We propose a novel prompt tuning method called CoAPT(Context Attribute words in Prompt Tuning) for few/zero-shot image classification. The core motivation is that attributes are descriptive words with rich information about a given concept. Thus, we aim to enrich text queries of existing prompt tuning methods, improving alignment between text and image embeddings in CLIP embedding space. To do so, CoAPT integrates attribute words as additional prompts within learnable prompt tuning and can be easily incorporated into various existing prompt tuning methods. To facilitate the incorporation of attributes into text embeddings and the alignment with image embeddings, soft prompts are trained together with an additional meta-network that generates input-image-wise feature biases from the concatenated feature encodings of the image-text combined queries. Our experiments demonstrate that CoAPT leads to considerable improvements for existing baseline methods on several few/zero-shot image classification tasks, including base-to-novel generalization, cross-dataset transfer, and domain generalization. Our findings highlight the importance of combining hard and soft prompts and pave the way for future research on the interplay between text and image latent spaces in pre-trained models.
Rethinking RGB Color Representation for Image Restoration Models
Feb 05, 2024



Image restoration models are typically trained with a pixel-wise distance loss defined over the RGB color representation space, which is well known to be a source of blurry and unrealistic textures in the restored images. The reason, we believe, is that the three-channel RGB space is insufficient for supervising the restoration models. To this end, we augment the representation to hold structural information of local neighborhoods at each pixel while keeping the color information and pixel-grainedness unharmed. The result is a new representation space, dubbed augmented RGB ($a$RGB) space. Substituting the underlying representation space for the per-pixel losses facilitates the training of image restoration models, thereby improving the performance without affecting the evaluation phase. Notably, when combined with auxiliary objectives such as adversarial or perceptual losses, our $a$RGB space consistently improves overall metrics by reconstructing both color and local structures, overcoming the conventional perception-distortion trade-off.
MEIL-NeRF: Memory-Efficient Incremental Learning of Neural Radiance Fields
Dec 31, 2022



Hinged on the representation power of neural networks, neural radiance fields (NeRF) have recently emerged as one of the promising and widely applicable methods for 3D object and scene representation. However, NeRF faces challenges in practical applications, such as large-scale scenes and edge devices with a limited amount of memory, where data needs to be processed sequentially. Under such incremental learning scenarios, neural networks are known to suffer catastrophic forgetting: easily forgetting previously seen data after training with new data. We observe that previous incremental learning algorithms are limited by either low performance or memory scalability issues. As such, we develop a Memory-Efficient Incremental Learning algorithm for NeRF (MEIL-NeRF). MEIL-NeRF takes inspiration from NeRF itself in that a neural network can serve as a memory that provides the pixel RGB values, given rays as queries. Upon the motivation, our framework learns which rays to query NeRF to extract previous pixel values. The extracted pixel values are then used to train NeRF in a self-distillation manner to prevent catastrophic forgetting. As a result, MEIL-NeRF demonstrates constant memory consumption and competitive performance.
CADyQ: Content-Aware Dynamic Quantization for Image Super-Resolution
Jul 21, 2022
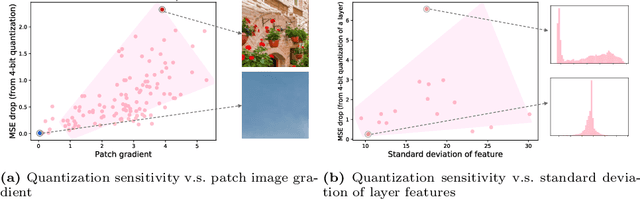
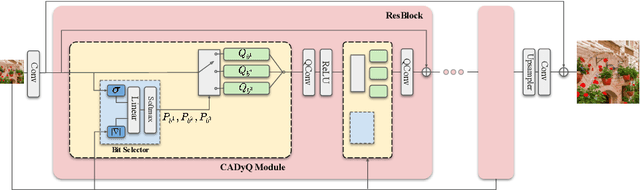
Despite breakthrough advances in image super-resolution (SR) with convolutional neural networks (CNNs), SR has yet to enjoy ubiquitous applications due to the high computational complexity of SR networks. Quantization is one of the promising approaches to solve this problem. However, existing methods fail to quantize SR models with a bit-width lower than 8 bits, suffering from severe accuracy loss due to fixed bit-width quantization applied everywhere. In this work, to achieve high average bit-reduction with less accuracy loss, we propose a novel Content-Aware Dynamic Quantization (CADyQ) method for SR networks that allocates optimal bits to local regions and layers adaptively based on the local contents of an input image. To this end, a trainable bit selector module is introduced to determine the proper bit-width and quantization level for each layer and a given local image patch. This module is governed by the quantization sensitivity that is estimated by using both the average magnitude of image gradient of the patch and the standard deviation of the input feature of the layer. The proposed quantization pipeline has been tested on various SR networks and evaluated on several standard benchmarks extensively. Significant reduction in computational complexity and the elevated restoration accuracy clearly demonstrate the effectiveness of the proposed CADyQ framework for SR. Codes are available at https://github.com/Cheeun/CADyQ.
Batch Normalization Tells You Which Filter is Important
Dec 02, 2021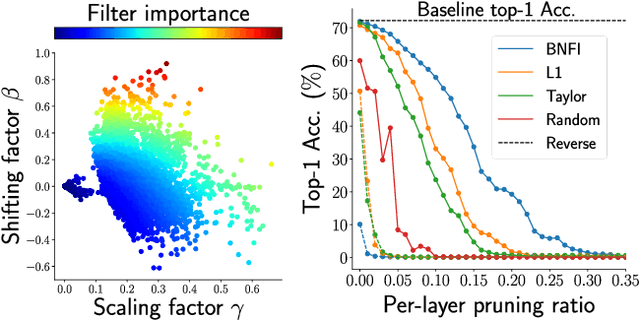
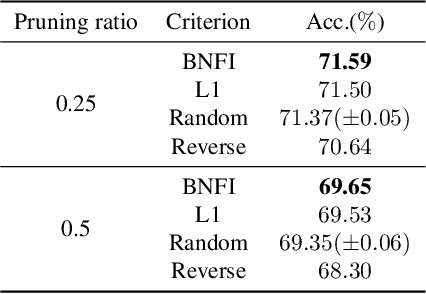
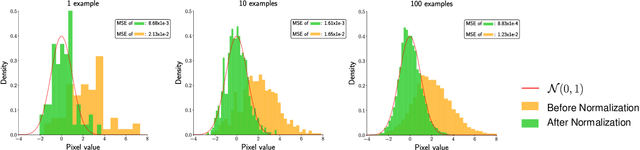
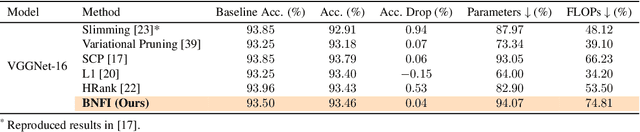
The goal of filter pruning is to search for unimportant filters to remove in order to make convolutional neural networks (CNNs) efficient without sacrificing the performance in the process. The challenge lies in finding information that can help determine how important or relevant each filter is with respect to the final output of neural networks. In this work, we share our observation that the batch normalization (BN) parameters of pre-trained CNNs can be used to estimate the feature distribution of activation outputs, without processing of training data. Upon observation, we propose a simple yet effective filter pruning method by evaluating the importance of each filter based on the BN parameters of pre-trained CNNs. The experimental results on CIFAR-10 and ImageNet demonstrate that the proposed method can achieve outstanding performance with and without fine-tuning in terms of the trade-off between the accuracy drop and the reduction in computational complexity and number of parameters of pruned networks.