 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Rethinking RGB Color Representation for Image Restoration Models
Feb 05, 2024



Image restoration models are typically trained with a pixel-wise distance loss defined over the RGB color representation space, which is well known to be a source of blurry and unrealistic textures in the restored images. The reason, we believe, is that the three-channel RGB space is insufficient for supervising the restoration models. To this end, we augment the representation to hold structural information of local neighborhoods at each pixel while keeping the color information and pixel-grainedness unharmed. The result is a new representation space, dubbed augmented RGB ($a$RGB) space. Substituting the underlying representation space for the per-pixel losses facilitates the training of image restoration models, thereby improving the performance without affecting the evaluation phase. Notably, when combined with auxiliary objectives such as adversarial or perceptual losses, our $a$RGB space consistently improves overall metrics by reconstructing both color and local structures, overcoming the conventional perception-distortion trade-off.
Extract-and-Adaptation Network for 3D Interacting Hand Mesh Recovery
Sep 05, 2023Understanding how two hands interact with each other is a key component of accurate 3D interacting hand mesh recovery. However, recent Transformer-based methods struggle to learn the interaction between two hands as they directly utilize two hand features as input tokens, which results in distant token problem. The distant token problem represents that input tokens are in heterogeneous spaces, leading Transformer to fail in capturing correlation between input tokens. Previous Transformer-based methods suffer from the problem especially when poses of two hands are very different as they project features from a backbone to separate left and right hand-dedicated features. We present EANet, extract-and-adaptation network, with EABlock, the main component of our network. Rather than directly utilizing two hand features as input tokens, our EABlock utilizes two complementary types of novel tokens, SimToken and JoinToken, as input tokens. Our two novel tokens are from a combination of separated two hand features; hence, it is much more robust to the distant token problem. Using the two type of tokens, our EABlock effectively extracts interaction feature and adapts it to each hand. The proposed EANet achieves the state-of-the-art performance on 3D interacting hands benchmarks. The codes are available at https://github.com/jkpark0825/EANet.
Recovering 3D Hand Mesh Sequence from a Single Blurry Image: A New Dataset and Temporal Unfolding
Mar 27, 2023Hands, one of the most dynamic parts of our body, suffer from blur due to their active movements. However, previous 3D hand mesh recovery methods have mainly focused on sharp hand images rather than considering blur due to the absence of datasets providing blurry hand images. We first present a novel dataset BlurHand, which contains blurry hand images with 3D groundtruths. The BlurHand is constructed by synthesizing motion blur from sequential sharp hand images, imitating realistic and natural motion blurs. In addition to the new dataset, we propose BlurHandNet, a baseline network for accurate 3D hand mesh recovery from a blurry hand image. Our BlurHandNet unfolds a blurry input image to a 3D hand mesh sequence to utilize temporal information in the blurry input image, while previous works output a static single hand mesh. We demonstrate the usefulness of BlurHand for the 3D hand mesh recovery from blurry images in our experiments. The proposed BlurHandNet produces much more robust results on blurry images while generalizing well to in-the-wild images. The training codes and BlurHand dataset are available at https://github.com/JaehaKim97/BlurHand_RELEASE.
Pay Attention to Hidden States for Video Deblurring: Ping-Pong Recurrent Neural Networks and Selective Non-Local Attention
Apr 07, 2022
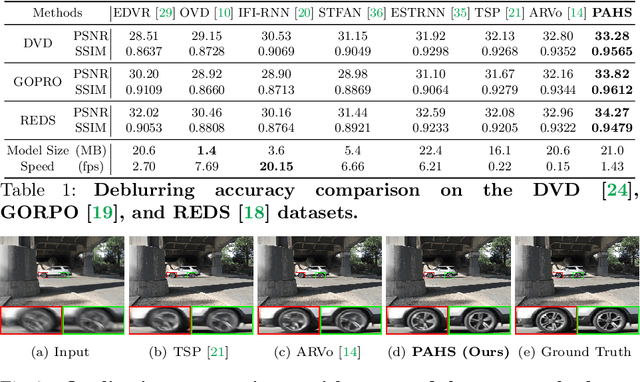
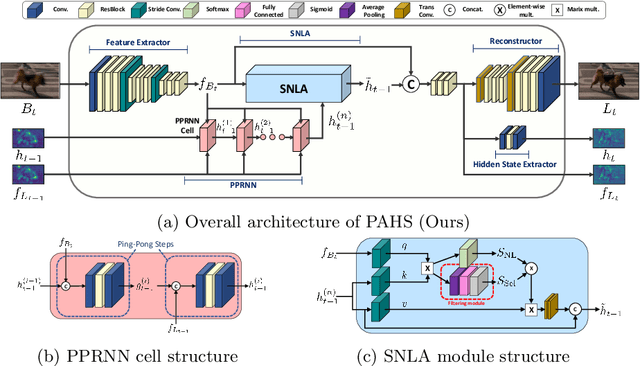

Video deblurring models exploit information in the neighboring frames to remove blur caused by the motion of the camera and the objects. Recurrent Neural Networks~(RNNs) are often adopted to model the temporal dependency between frames via hidden states. When motion blur is strong, however, hidden states are hard to deliver proper information due to the displacement between different frames. While there have been attempts to update the hidden states, it is difficult to handle misaligned features beyond the receptive field of simple modules. Thus, we propose 2 modules to supplement the RNN architecture for video deblurring. First, we design Ping-Pong RNN~(PPRNN) that acts on updating the hidden states by referring to the features from the current and the previous time steps alternately. PPRNN gathers relevant information from the both features in an iterative and balanced manner by utilizing its recurrent architecture. Second, we use a Selective Non-Local Attention~(SNLA) module to additionally refine the hidden state by aligning it with the positional information from the input frame feature. The attention score is scaled by the relevance to the input feature to focus on the necessary information. By paying attention to hidden states with both modules, which have strong synergy, our PAHS framework improves the representation powers of RNN structures and achieves state-of-the-art deblurring performance on standard benchmarks and real-world videos.
HandOccNet: Occlusion-Robust 3D Hand Mesh Estimation Network
Mar 28, 2022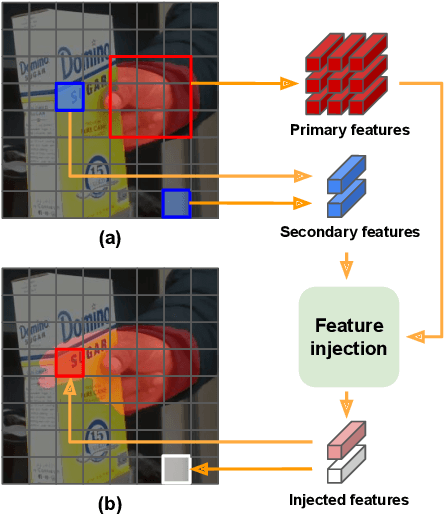
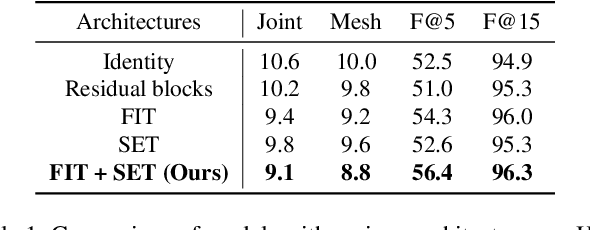
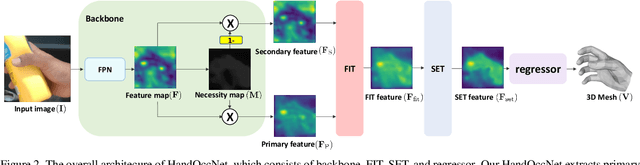

Hands are often severely occluded by objects, which makes 3D hand mesh estimation challenging. Previous works often have disregarded information at occluded regions. However, we argue that occluded regions have strong correlations with hands so that they can provide highly beneficial information for complete 3D hand mesh estimation. Thus, in this work, we propose a novel 3D hand mesh estimation network HandOccNet, that can fully exploits the information at occluded regions as a secondary means to enhance image features and make it much richer. To this end, we design two successive Transformer-based modules, called feature injecting transformer (FIT) and self- enhancing transformer (SET). FIT injects hand information into occluded region by considering their correlation. SET refines the output of FIT by using a self-attention mechanism. By injecting the hand information to the occluded region, our HandOccNet reaches the state-of-the-art performance on 3D hand mesh benchmarks that contain challenging hand-object occlusions. The codes are available in: https://github.com/namepllet/HandOccNet.
* also attached the supplementary material
3DCrowdNet: 2D Human Pose-Guided3D Crowd Human Pose and Shape Estimation in the Wild
Apr 15, 2021



Recovering accurate 3D human pose and shape from in-the-wild crowd scenes is highly challenging and barely studied, despite their common presence. In this regard, we present 3DCrowdNet, a 2D human pose-guided 3D crowd pose and shape estimation system for in-the-wild scenes. 2D human pose estimation methods provide relatively robust outputs on crowd scenes than 3D human pose estimation methods, as they can exploit in-the-wild multi-person 2D datasets that include crowd scenes. On the other hand, the 3D methods leverage 3D datasets, of which images mostly contain a single actor without a crowd. The train data difference impedes the 3D methods' ability to focus on a target person in in-the-wild crowd scenes. Thus, we design our system to leverage the robust 2D pose outputs from off-the-shelf 2D pose estimators, which guide a network to focus on a target person and provide essential human articulation information. We show that our 3DCrowdNet outperforms previous methods on in-the-wild crowd scenes. We will release the codes.