 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human-Object Interaction for 3D Human Pose Estimation from LiDAR Point Clouds
Mar 17, 2026Understanding humans from LiDAR point clouds is one of the most critical tasks in autonomous driving due to its close relationships with pedestrian safety, yet it remains challenging in the presence of diverse human-object interactions and cluttered backgrounds. Nevertheless, existing methods largely overlook the potential of leveraging human-object interactions to build robust 3D human pose estimation frameworks. There are two major challenges that motivate the incorporation of human-object interaction. First, human-object interactions introduce spatial ambiguity between human and object points, which often leads to erroneous 3D human keypoint predictions in interaction regions. Second, there exists severe class imbalance in the number of points between interacting and non-interacting body parts, with the interaction-frequent regions such as hand and foot being sparsely observed in LiDAR data. To address these challenges, we propose a Human-Object Interaction Learning (HOIL) framework for robust 3D human pose estimation from LiDAR point clouds. To mitigate the spatial ambiguity issue, we present human-object interaction-aware contrastive learning (HOICL) that effectively enhances feature discrimination between human and object points, particularly in interaction regions. To alleviate the class imbalance issue, we introduce contact-aware part-guided pooling (CPPool) that adaptively reallocates representational capacity by compressing overrepresented points while preserving informative points from interacting body parts. In addition, we present an optional contact-based temporal refinement that refines erroneous per-frame keypoint estimates using contact cues over time. As a result, our HOIL effectively leverages human-object interaction to resolve spatial ambiguity and class imbalance in interaction regions. Codes will be released.
TeHOR: Text-Guided 3D Human and Object Reconstruction with Textures
Feb 23, 2026Joint reconstruction of 3D human and object from a single image is an active research area, with pivotal applications in robotics and digital content creation. Despite recent advances, existing approaches suffer from two fundamental limitations. First, their reconstructions rely heavily on physical contact information, which inherently cannot capture non-contact human-object interactions, such as gazing at or pointing toward an object. Second, the reconstruction process is primarily driven by local geometric proximity, neglecting the human and object appearances that provide global context crucial for understanding holistic interactions. To address these issues, we introduce TeHOR, a framework built upon two core designs. First, beyond contact information, our framework leverages text descriptions of human-object interactions to enforce semantic alignment between the 3D reconstruction and its textual cues, enabling reasoning over a wider spectrum of interactions, including non-contact cases. Second, we incorporate appearance cues of the 3D human and object into the alignment process to capture holistic contextual information, thereby ensuring visually plausible reconstructions. As a result, our framework produces accurate and semantically coherent reconstructions, achieving state-of-the-art performance.
Learning Dense Hand Contact Estimation from Imbalanced Data
May 16, 2025Hands are essential to human interaction, and understanding contact between hands and the world can promote comprehensive understanding of their function. Recently, there have been growing number of hand interaction datasets that cover interaction with object, other hand, scene, and body. Despite the significance of the task and increasing high-quality data, how to effectively learn dense hand contact estimation remains largely underexplored. There are two major challenges for learning dense hand contact estimation. First, there exists class imbalance issue from hand contact datasets where majority of samples are not in contact. Second, hand contact datasets contain spatial imbalance issue with most of hand contact exhibited in finger tips, resulting in challenges for generalization towards contacts in other hand regions. To tackle these issues, we present a framework that learns dense HAnd COntact estimation (HACO) from imbalanced data. To resolve the class imbalance issue, we introduce balanced contact sampling, which builds and samples from multiple sampling groups that fairly represent diverse contact statistics for both contact and non-contact samples. Moreover, to address the spatial imbalance issue, we propose vertex-level class-balanced (VCB) loss, which incorporates spatially varying contact distribution by separately reweighting loss contribution of each vertex based on its contact frequency across dataset. As a result, we effectively learn to predict dense hand contact estimation with large-scale hand contact data without suffering from class and spatial imbalance issue. The codes will be released.
Joint Reconstruction of 3D Human and Object via Contact-Based Refinement Transformer
Apr 07, 2024Human-object contact serves as a strong cue to understand how humans physically interact with objects. Nevertheless, it is not widely explored to utilize human-object contact information for the joint reconstruction of 3D human and object from a single image. In this work, we present a novel joint 3D human-object reconstruction method (CONTHO) that effectively exploits contact information between humans and objects. There are two core designs in our system: 1) 3D-guided contact estimation and 2) contact-based 3D human and object refinement. First, for accurate human-object contact estimation, CONTHO initially reconstructs 3D humans and objects and utilizes them as explicit 3D guidance for contact estimation. Second, to refine the initial reconstructions of 3D human and object, we propose a novel contact-based refinement Transformer that effectively aggregates human features and object features based on the estimated human-object contact. The proposed contact-based refinement prevents the learning of erroneous correlation between human and object, which enables accurate 3D reconstruction. As a result, our CONTHO achieves state-of-the-art performance in both human-object contact estimation and joint reconstruction of 3D human and object. The code is publicly available at https://github.com/dqj5182/CONTHO_RELEASE.
StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
Apr 01, 2024



The enormous success of diffusion models in text-to-image synthesis has made them promising candidates for the next generation of end-user applications for image generation and editing. Previous works have focused on improving the usability of diffusion models by reducing the inference time or increasing user interactivity by allowing new, fine-grained controls such as region-based text prompts. However, we empirically find that integrating both branches of works is nontrivial, limiting the potential of diffusion models. To solve this incompatibility, we present StreamMultiDiffusion, the first real-time region-based text-to-image generation framework. By stabilizing fast inference techniques and restructuring the model into a newly proposed multi-prompt stream batch architecture, we achieve $\times 10$ faster panorama generation than existing solutions, and the generation speed of 1.57 FPS in region-based text-to-image synthesis on a single RTX 2080 Ti GPU. Our solution opens up a new paradigm for interactive image generation named semantic palette, where high-quality images are generated in real-time from given multiple hand-drawn regions, encoding prescribed semantic meanings (e.g., eagle, girl). Our code and demo application are available at https://github.com/ironjr/StreamMultiDiffusion.
RHOBIN Challenge: Reconstruction of Human Object Interaction
Jan 07, 2024Modeling the interaction between humans and objects has been an emerging research direction in recent years. Capturing human-object interaction is however a very challenging task due to heavy occlusion and complex dynamics, which requires understanding not only 3D human pose, and object pose but also the interaction between them. Reconstruction of 3D humans and objects has been two separate research fields in computer vision for a long time. We hence proposed the first RHOBIN challenge: reconstruction of human-object interactions in conjunction with the RHOBIN workshop. It was aimed at bringing the research communities of human and object reconstruction as well as interaction modeling together to discuss techniques and exchange ideas. Our challenge consists of three tracks of 3D reconstruction from monocular RGB images with a focus on dealing with challenging interaction scenarios. Our challenge attracted more than 100 participants with more than 300 submissions, indicating the broad interest in the research communities. This paper describes the settings of our challenge and discusses the winning methods of each track in more detail. We observe that the human reconstruction task is becoming mature even under heavy occlusion settings while object pose estimation and joint reconstruction remain challenging tasks. With the growing interest in interaction modeling, we hope this report can provide useful insights and foster future research in this direction. Our workshop website can be found at \href{https://rhobin-challenge.github.io/}{https://rhobin-challenge.github.io/}.
Extract-and-Adaptation Network for 3D Interacting Hand Mesh Recovery
Sep 05, 2023Understanding how two hands interact with each other is a key component of accurate 3D interacting hand mesh recovery. However, recent Transformer-based methods struggle to learn the interaction between two hands as they directly utilize two hand features as input tokens, which results in distant token problem. The distant token problem represents that input tokens are in heterogeneous spaces, leading Transformer to fail in capturing correlation between input tokens. Previous Transformer-based methods suffer from the problem especially when poses of two hands are very different as they project features from a backbone to separate left and right hand-dedicated features. We present EANet, extract-and-adaptation network, with EABlock, the main component of our network. Rather than directly utilizing two hand features as input tokens, our EABlock utilizes two complementary types of novel tokens, SimToken and JoinToken, as input tokens. Our two novel tokens are from a combination of separated two hand features; hence, it is much more robust to the distant token problem. Using the two type of tokens, our EABlock effectively extracts interaction feature and adapts it to each hand. The proposed EANet achieves the state-of-the-art performance on 3D interacting hands benchmarks. The codes are available at https://github.com/jkpark0825/EANet.
Cyclic Test-Time Adaptation on Monocular Video for 3D Human Mesh Reconstruction
Aug 12, 2023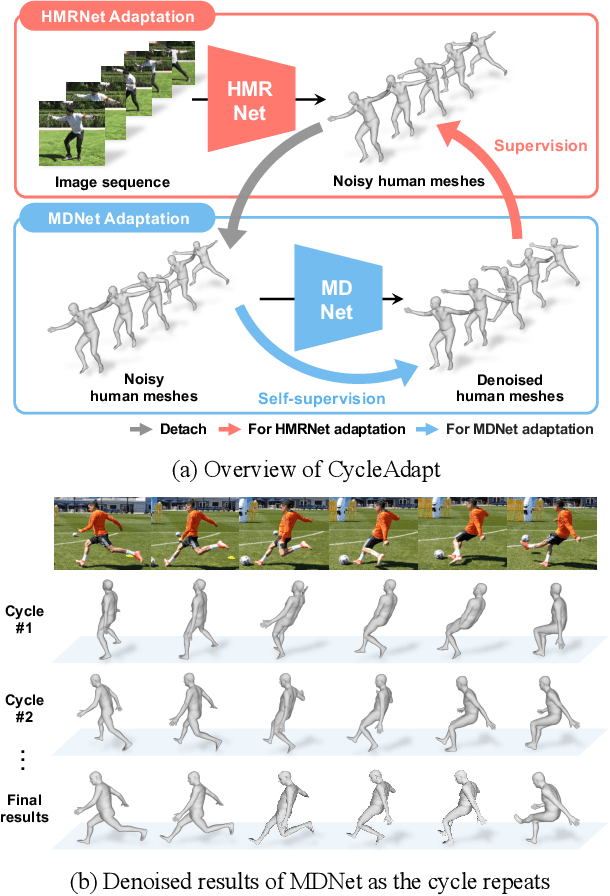



Despite recent advances in 3D human mesh reconstruction, domain gap between training and test data is still a major challenge. Several prior works tackle the domain gap problem via test-time adaptation that fine-tunes a network relying on 2D evidence (e.g., 2D human keypoints) from test images. However, the high reliance on 2D evidence during adaptation causes two major issues. First, 2D evidence induces depth ambiguity, preventing the learning of accurate 3D human geometry. Second, 2D evidence is noisy or partially non-existent during test time, and such imperfect 2D evidence leads to erroneous adaptation. To overcome the above issues, we introduce CycleAdapt, which cyclically adapts two networks: a human mesh reconstruction network (HMRNet) and a human motion denoising network (MDNet), given a test video. In our framework, to alleviate high reliance on 2D evidence, we fully supervise HMRNet with generated 3D supervision targets by MDNet. Our cyclic adaptation scheme progressively elaborates the 3D supervision targets, which compensate for imperfect 2D evidence. As a result, our CycleAdapt achieves state-of-the-art performance compared to previous test-time adaptation methods. The codes are available at https://github.com/hygenie1228/CycleAdapt_RELEASE.