 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Layout-R1: Structured Reasoning for Language-Instructed Spatial Editing
Mar 23, 2026Large Language Models (LLMs) and Vision Language Models (VLMs) have shown impressive reasoning abilities, yet they struggle with spatial understanding and layout consistency when performing fine-grained visual editing. We introduce a Structured Reasoning framework that performs text-conditioned spatial layout editing via scene-graph reasoning. Given an input scene graph and a natural-language instruction, the model reasons over the graph to generate an updated scene graph that satisfies the text condition while maintaining spatial coherence. By explicitly guiding the reasoning process through structured relational representations, our approach improves both interpretability and control over spatial relationships. We evaluate our method on a new text-guided layout editing benchmark encompassing sorting, spatial alignment, and room-editing tasks. Our training paradigm yields an average 15% improvement in IoU and 25% reduction in center-distance error compared to Chain of Thought Fine-tuning (CoT-SFT) and vanilla GRPO baselines. Compared to SOTA zero-shot LLMs, our best models achieve up to 20% higher mIoU, demonstrating markedly improved spatial precision.
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Feb 06, 2026Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.
PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation
Jan 07, 2026Humans anticipate, from a glance and a contemplated action of their bodies, how the 3D world will respond, a capability that is equally vital for robotic manipulation. We introduce PointWorld, a large pre-trained 3D world model that unifies state and action in a shared 3D space as 3D point flows: given one or few RGB-D images and a sequence of low-level robot action commands, PointWorld forecasts per-pixel displacements in 3D that respond to the given actions. By representing actions as 3D point flows instead of embodiment-specific action spaces (e.g., joint positions), this formulation directly conditions on physical geometries of robots while seamlessly integrating learning across embodiments. To train our 3D world model, we curate a large-scale dataset spanning real and simulated robotic manipulation in open-world environments, enabled by recent advances in 3D vision and simulated environments, totaling about 2M trajectories and 500 hours across a single-arm Franka and a bimanual humanoid. Through rigorous, large-scale empirical studies of backbones, action representations, learning objectives, partial observability, data mixtures, domain transfers, and scaling, we distill design principles for large-scale 3D world modeling. With a real-time (0.1s) inference speed, PointWorld can be efficiently integrated in the model-predictive control (MPC) framework for manipulation. We demonstrate that a single pre-trained checkpoint enables a real-world Franka robot to perform rigid-body pushing, deformable and articulated object manipulation, and tool use, without requiring any demonstrations or post-training and all from a single image captured in-the-wild. Project website at https://point-world.github.io/.
Openpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
Slot-Level Robotic Placement via Visual Imitation from Single Human Video
Apr 02, 2025



The majority of modern robot learning methods focus on learning a set of pre-defined tasks with limited or no generalization to new tasks. Extending the robot skillset to novel tasks involves gathering an extensive amount of training data for additional tasks. In this paper, we address the problem of teaching new tasks to robots using human demonstration videos for repetitive tasks (e.g., packing). This task requires understanding the human video to identify which object is being manipulated (the pick object) and where it is being placed (the placement slot). In addition, it needs to re-identify the pick object and the placement slots during inference along with the relative poses to enable robot execution of the task. To tackle this, we propose SLeRP, a modular system that leverages several advanced visual foundation models and a novel slot-level placement detector Slot-Net, eliminating the need for expensive video demonstrations for training. We evaluate our system using a new benchmark of real-world videos. The evaluation results show that SLeRP outperforms several baselines and can be deployed on a real robot.
SIGHT: Single-Image Conditioned Generation of Hand Trajectories for Hand-Object Interaction
Mar 28, 2025We introduce a novel task of generating realistic and diverse 3D hand trajectories given a single image of an object, which could be involved in a hand-object interaction scene or pictured by itself. When humans grasp an object, appropriate trajectories naturally form in our minds to use it for specific tasks. Hand-object interaction trajectory priors can greatly benefit applications in robotics, embodied AI, augmented reality and related fields. However, synthesizing realistic and appropriate hand trajectories given a single object or hand-object interaction image is a highly ambiguous task, requiring to correctly identify the object of interest and possibly even the correct interaction among many possible alternatives. To tackle this challenging problem, we propose the SIGHT-Fusion system, consisting of a curated pipeline for extracting visual features of hand-object interaction details from egocentric videos involving object manipulation, and a diffusion-based conditional motion generation model processing the extracted features. We train our method given video data with corresponding hand trajectory annotations, without supervision in the form of action labels. For the evaluation, we establish benchmarks utilizing the first-person FPHAB and HOI4D datasets, testing our method against various baselines and using multiple metrics. We also introduce task simulators for executing the generated hand trajectories and reporting task success rates as an additional metric. Experiments show that our method generates more appropriate and realistic hand trajectories than baselines and presents promising generalization capability on unseen objects. The accuracy of the generated hand trajectories is confirmed in a physics simulation setting, showcasing the authenticity of the created sequences and their applicability in downstream uses.
MatchMaker: Automated Asset Generation for Robotic Assembly
Mar 07, 2025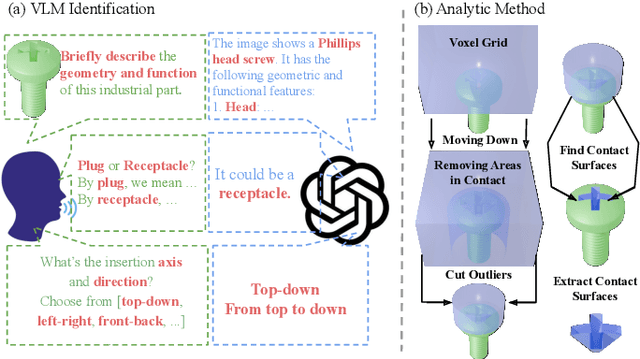
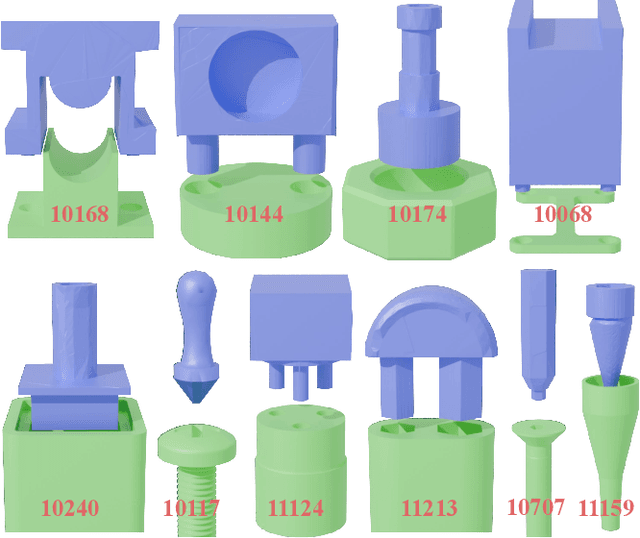
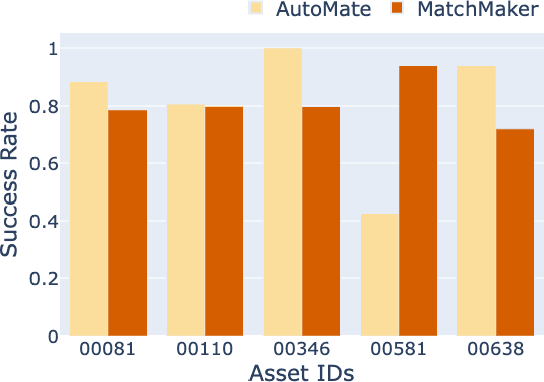
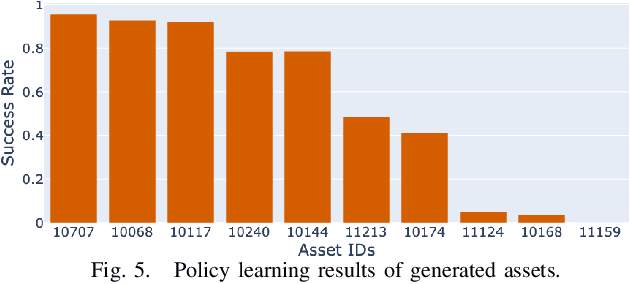
Robotic assembly remains a significant challenge due to complexities in visual perception, functional grasping, contact-rich manipulation, and performing high-precision tasks. Simulation-based learning and sim-to-real transfer have led to recent success in solving assembly tasks in the presence of object pose variation, perception noise, and control error; however, the development of a generalist (i.e., multi-task) agent for a broad range of assembly tasks has been limited by the need to manually curate assembly assets, which greatly constrains the number and diversity of assembly problems that can be used for policy learning. Inspired by recent success of using generative AI to scale up robot learning, we propose MatchMaker, a pipeline to automatically generate diverse, simulation-compatible assembly asset pairs to facilitate learning assembly skills. Specifically, MatchMaker can 1) take a simulation-incompatible, interpenetrating asset pair as input, and automatically convert it into a simulation-compatible, interpenetration-free pair, 2) take an arbitrary single asset as input, and generate a geometrically-mating asset to create an asset pair, 3) automatically erode contact surfaces from (1) or (2) according to a user-specified clearance parameter to generate realistic parts. We demonstrate that data generated by MatchMaker outperforms previous work in terms of diversity and effectiveness for downstream assembly skill learning. For videos and additional details, please see our project website: https://wangyian-me.github.io/MatchMaker/.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
3D-MVP: 3D Multiview Pretraining for Robotic Manipulation
Jun 26, 2024



Recent works have shown that visual pretraining on egocentric datasets using masked autoencoders (MAE) can improve generalization for downstream robotics tasks. However, these approaches pretrain only on 2D images, while many robotics applications require 3D scene understanding. In this work, we propose 3D-MVP, a novel approach for 3D multi-view pretraining using masked autoencoders. We leverage Robotic View Transformer (RVT), which uses a multi-view transformer to understand the 3D scene and predict gripper pose actions. We split RVT's multi-view transformer into visual encoder and action decoder, and pretrain its visual encoder using masked autoencoding on large-scale 3D datasets such as Objaverse. We evaluate 3D-MVP on a suite of virtual robot manipulation tasks and demonstrate improved performance over baselines. We also show promising results on a real robot platform with minimal finetuning. Our results suggest that 3D-aware pretraining is a promising approach to improve sample efficiency and generalization of vision-based robotic manipulation policies. We will release code and pretrained models for 3D-MVP to facilitate future research. Project site: https://jasonqsy.github.io/3DMVP
URDFormer: A Pipeline for Constructing Articulated Simulation Environments from Real-World Images
May 19, 2024



Constructing simulation scenes that are both visually and physically realistic is a problem of practical interest in domains ranging from robotics to computer vision. This problem has become even more relevant as researchers wielding large data-hungry learning methods seek new sources of training data for physical decision-making systems. However, building simulation models is often still done by hand. A graphic designer and a simulation engineer work with predefined assets to construct rich scenes with realistic dynamic and kinematic properties. While this may scale to small numbers of scenes, to achieve the generalization properties that are required for data-driven robotic control, we require a pipeline that is able to synthesize large numbers of realistic scenes, complete with 'natural' kinematic and dynamic structures. To attack this problem, we develop models for inferring structure and generating simulation scenes from natural images, allowing for scalable scene generation from web-scale datasets. To train these image-to-simulation models, we show how controllable text-to-image generative models can be used in generating paired training data that allows for modeling of the inverse problem, mapping from realistic images back to complete scene models. We show how this paradigm allows us to build large datasets of scenes in simulation with semantic and physical realism. We present an integrated end-to-end pipeline that generates simulation scenes complete with articulated kinematic and dynamic structures from real-world images and use these for training robotic control policies. We then robustly deploy in the real world for tasks like articulated object manipulation. In doing so, our work provides both a pipeline for large-scale generation of simulation environments and an integrated system for training robust robotic control policies in the resulting environments.