 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Data Selection for Instruction Tuning
Mar 03, 2025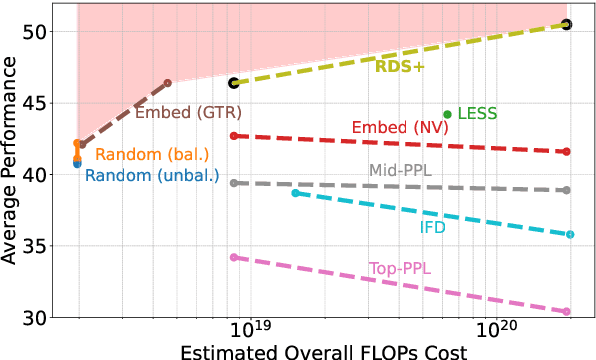


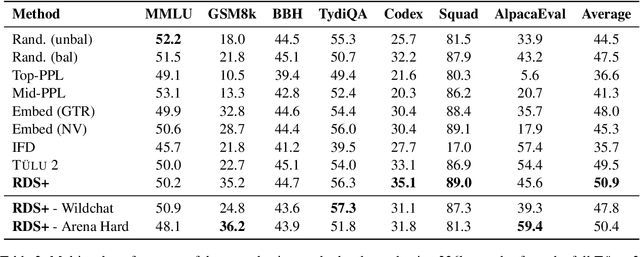
Selecting high-quality training data from a larger pool is a crucial step when instruction-tuning language models, as carefully curated datasets often produce models that outperform those trained on much larger, noisier datasets. Automated data selection approaches for instruction-tuning are typically tested by selecting small datasets (roughly 10k samples) from small pools (100-200k samples). However, popular deployed instruction-tuned models often train on hundreds of thousands to millions of samples, subsampled from even larger data pools. We present a systematic study of how well data selection methods scale to these settings, selecting up to 2.5M samples from pools of up to 5.8M samples and evaluating across 7 diverse tasks. We show that many recently proposed methods fall short of random selection in this setting (while using more compute), and even decline in performance when given access to larger pools of data to select over. However, we find that a variant of representation-based data selection (RDS+), which uses weighted mean pooling of pretrained LM hidden states, consistently outperforms more complex methods across all settings tested -- all whilst being more compute-efficient. Our findings highlight that the scaling properties of proposed automated selection methods should be more closely examined. We release our code, data, and models at https://github.com/hamishivi/automated-instruction-selection.
Ladder-residual: parallelism-aware architecture for accelerating large model inference with communication overlapping
Jan 11, 2025



Large language model inference is both memory-intensive and time-consuming, often requiring distributed algorithms to efficiently scale. Various model parallelism strategies are used in multi-gpu training and inference to partition computation across multiple devices, reducing memory load and computation time. However, using model parallelism necessitates communication of information between GPUs, which has been a major bottleneck and limits the gains obtained by scaling up the number of devices. We introduce Ladder Residual, a simple architectural modification applicable to all residual-based models that enables straightforward overlapping that effectively hides the latency of communication. Our insight is that in addition to systems optimization, one can also redesign the model architecture to decouple communication from computation. While Ladder Residual can allow communication-computation decoupling in conventional parallelism patterns, we focus on Tensor Parallelism in this paper, which is particularly bottlenecked by its heavy communication. For a Transformer model with 70B parameters, applying Ladder Residual to all its layers can achieve 30% end-to-end wall clock speed up at inference time with TP sharding over 8 devices. We refer the resulting Transformer model as the Ladder Transformer. We train a 1B and 3B Ladder Transformer from scratch and observe comparable performance to a standard dense transformer baseline. We also show that it is possible to convert parts of the Llama-3.1 8B model to our Ladder Residual architecture with minimal accuracy degradation by only retraining for 3B tokens.
Learning to Build by Building Your Own Instructions
Oct 01, 2024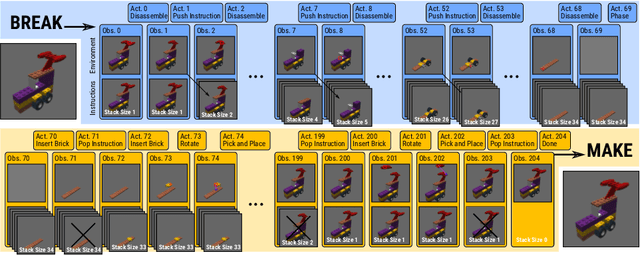
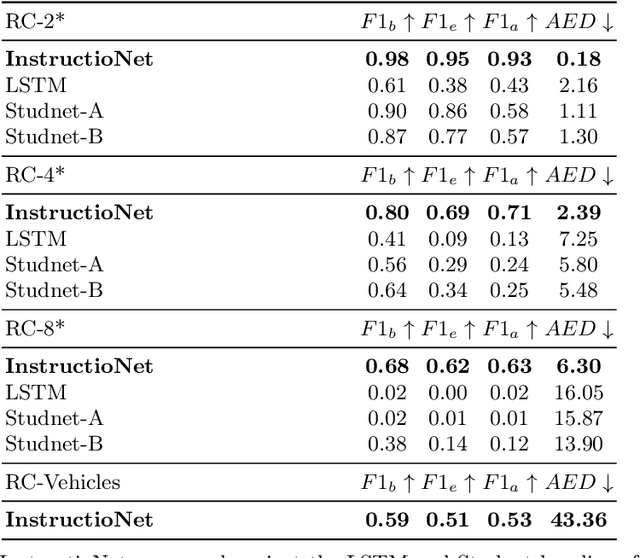

Structural understanding of complex visual objects is an important unsolved component of artificial intelligence. To study this, we develop a new technique for the recently proposed Break-and-Make problem in LTRON where an agent must learn to build a previously unseen LEGO assembly using a single interactive session to gather information about its components and their structure. We attack this problem by building an agent that we call \textbf{\ours} that is able to make its own visual instruction book. By disassembling an unseen assembly and periodically saving images of it, the agent is able to create a set of instructions so that it has the information necessary to rebuild it. These instructions form an explicit memory that allows the model to reason about the assembly process one step at a time, avoiding the need for long-term implicit memory. This in turn allows us to train on much larger LEGO assemblies than has been possible in the past. To demonstrate the power of this model, we release a new dataset of procedurally built LEGO vehicles that contain an average of 31 bricks each and require over one hundred steps to disassemble and reassemble. We train these models using online imitation learning which allows the model to learn from its own mistakes. Finally, we also provide some small improvements to LTRON and the Break-and-Make problem that simplify the learning environment and improve usability.
Toward a More Complete OMR Solution
Aug 31, 2024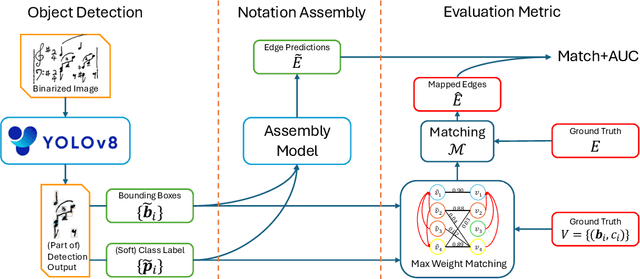
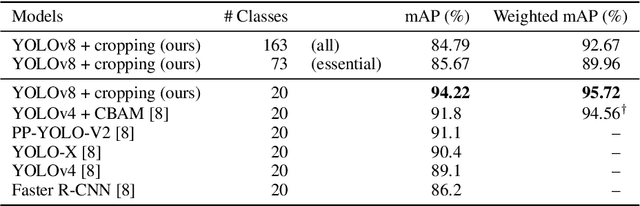


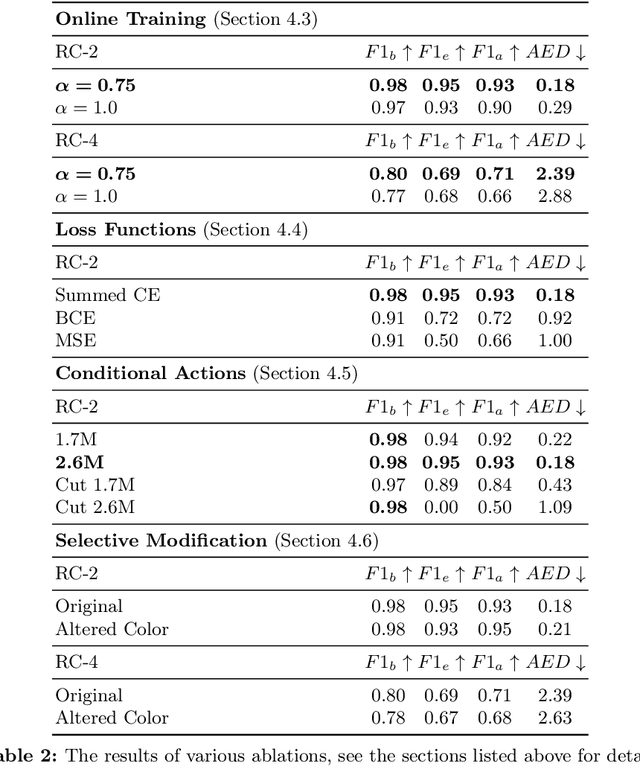
Optical music recognition (OMR) aims to convert music notation into digital formats. One approach to tackle OMR is through a multi-stage pipeline, where the system first detects visual music notation elements in the image (object detection) and then assembles them into a music notation (notation assembly). Most previous work on notation assembly unrealistically assumes perfect object detection. In this study, we focus on the MUSCIMA++ v2.0 dataset, which represents musical notation as a graph with pairwise relationships among detected music objects, and we consider both stages together. First, we introduce a music object detector based on YOLOv8, which improves detection performance. Second, we introduce a supervised training pipeline that completes the notation assembly stage based on detection output. We find that this model is able to outperform existing models trained on perfect detection output, showing the benefit of considering the detection and assembly stages in a more holistic way. These findings, together with our novel evaluation metric, are important steps toward a more complete OMR solution.
STOW: Discrete-Frame Segmentation and Tracking of Unseen Objects for Warehouse Picking Robots
Nov 04, 2023



Segmentation and tracking of unseen object instances in discrete frames pose a significant challenge in dynamic industrial robotic contexts, such as distribution warehouses. Here, robots must handle object rearrangement, including shifting, removal, and partial occlusion by new items, and track these items after substantial temporal gaps. The task is further complicated when robots encounter objects not learned in their training sets, which requires the ability to segment and track previously unseen items. Considering that continuous observation is often inaccessible in such settings, our task involves working with a discrete set of frames separated by indefinite periods during which substantial changes to the scene may occur. This task also translates to domestic robotic applications, such as rearrangement of objects on a table. To address these demanding challenges, we introduce new synthetic and real-world datasets that replicate these industrial and household scenarios. We also propose a novel paradigm for joint segmentation and tracking in discrete frames along with a transformer module that facilitates efficient inter-frame communication. The experiments we conduct show that our approach significantly outperforms recent methods. For additional results and videos, please visit \href{https://sites.google.com/view/stow-corl23}{website}. Code and dataset will be released.
How Language Model Hallucinations Can Snowball
May 22, 2023



A major risk of using language models in practical applications is their tendency to hallucinate incorrect statements. Hallucinations are often attributed to knowledge gaps in LMs, but we hypothesize that in some cases, when justifying previously generated hallucinations, LMs output false claims that they can separately recognize as incorrect. We construct three question-answering datasets where ChatGPT and GPT-4 often state an incorrect answer and offer an explanation with at least one incorrect claim. Crucially, we find that ChatGPT and GPT-4 can identify 67% and 87% of their own mistakes, respectively. We refer to this phenomenon as hallucination snowballing: an LM over-commits to early mistakes, leading to more mistakes that it otherwise would not make.
Measuring and Narrowing the Compositionality Gap in Language Models
Oct 07, 2022
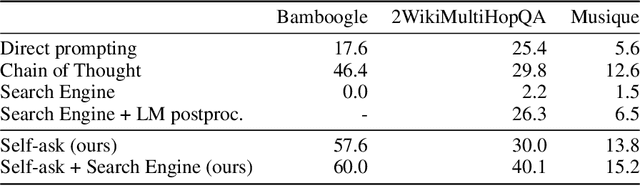


We investigate the ability of language models to perform compositional reasoning tasks where the overall solution depends on correctly composing the answers to sub-problems. We measure how often models can correctly answer all sub-problems but not generate the overall solution, a ratio we call the compositionality gap. We evaluate this ratio by asking multi-hop questions with answers that require composing multiple facts unlikely to have been observed together during pretraining. In the GPT-3 family of models, as model size increases we show that the single-hop question answering performance improves faster than the multi-hop performance does, therefore the compositionality gap does not decrease. This surprising result suggests that while more powerful models memorize and recall more factual knowledge, they show no corresponding improvement in their ability to perform this kind of compositional reasoning. We then demonstrate how elicitive prompting (such as chain of thought) narrows the compositionality gap by reasoning explicitly instead of implicitly. We present a new method, self-ask, that further improves on chain of thought. In our method, the model explicitly asks itself (and then answers) follow-up questions before answering the initial question. We finally show that self-ask's structured prompting lets us easily plug in a search engine to answer the follow-up questions, which additionally improves accuracy.
Break and Make: Interactive Structural Understanding Using LEGO Bricks
Jul 27, 2022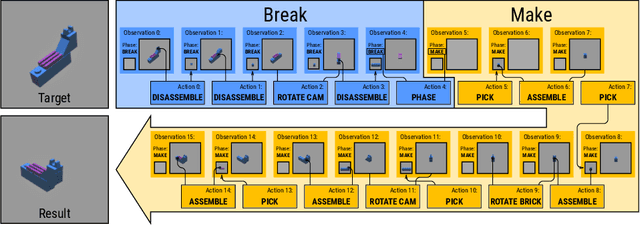
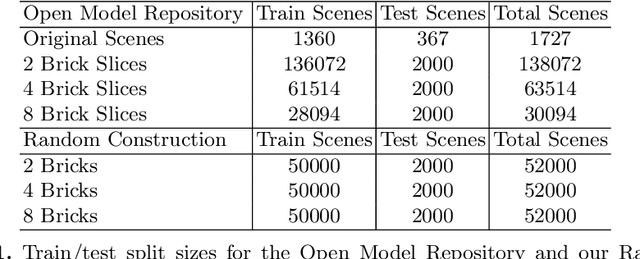
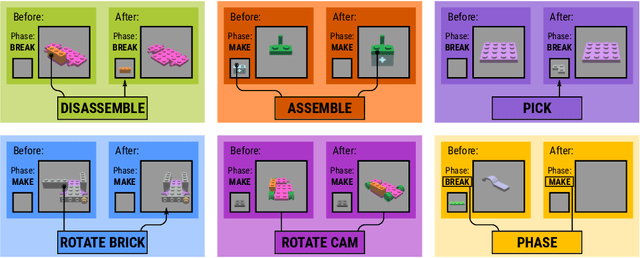
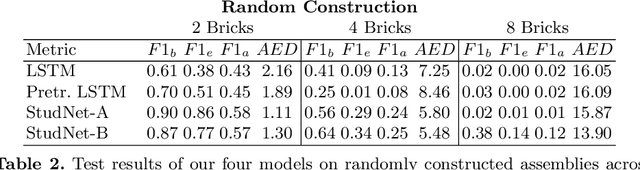
Visual understanding of geometric structures with complex spatial relationships is a fundamental component of human intelligence. As children, we learn how to reason about structure not only from observation, but also by interacting with the world around us -- by taking things apart and putting them back together again. The ability to reason about structure and compositionality allows us to not only build things, but also understand and reverse-engineer complex systems. In order to advance research in interactive reasoning for part-based geometric understanding, we propose a challenging new assembly problem using LEGO bricks that we call Break and Make. In this problem an agent is given a LEGO model and attempts to understand its structure by interactively inspecting and disassembling it. After this inspection period, the agent must then prove its understanding by rebuilding the model from scratch using low-level action primitives. In order to facilitate research on this problem we have built LTRON, a fully interactive 3D simulator that allows learning agents to assemble, disassemble and manipulate LEGO models. We pair this simulator with a new dataset of fan-made LEGO creations that have been uploaded to the internet in order to provide complex scenes containing over a thousand unique brick shapes. We take a first step towards solving this problem using sequence-to-sequence models that provide guidance for how to make progress on this challenging problem. Our simulator and data are available at github.com/aaronwalsman/ltron. Additional training code and PyTorch examples are available at github.com/aaronwalsman/ltron-torch-eccv22.