 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba-3: Improved Sequence Modeling using State Space Principles
Mar 16, 2026Scaling inference-time compute has emerged as an important driver of LLM performance, making inference efficiency a central focus of model design alongside model quality. While the current Transformer-based models deliver strong model quality, their quadratic compute and linear memory make inference expensive. This has spurred the development of sub-quadratic models with reduced linear compute and constant memory requirements. However, many recent linear models trade off model quality and capability for algorithmic efficiency, failing on tasks such as state tracking. Moreover, their theoretically linear inference remains hardware-inefficient in practice. Guided by an inference-first perspective, we introduce three core methodological improvements inspired by the state space model (SSM) viewpoint of linear models. We combine: (1) a more expressive recurrence derived from SSM discretization, (2) a complex-valued state update rule that enables richer state tracking, and (3) a multi-input, multi-output (MIMO) formulation for better model performance without increasing decode latency. Together with architectural refinements, our Mamba-3 model achieves significant gains across retrieval, state-tracking, and downstream language modeling tasks. At the 1.5B scale, Mamba-3 improves average downstream accuracy by 0.6 percentage points compared to the next best model (Gated DeltaNet), with Mamba-3's MIMO variant further improving accuracy by another 1.2 points for a total 1.8 point gain. Across state-size experiments, Mamba-3 achieves comparable perplexity to Mamba-2 despite using half of its predecessor's state size. Our evaluations demonstrate Mamba-3's ability to advance the performance-efficiency Pareto frontier.
M$^2$RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling
Mar 15, 2026Transformers are highly parallel but are limited to computations in the TC$^0$ complexity class, excluding tasks such as entity tracking and code execution that provably require greater expressive power. Motivated by this limitation, we revisit non-linear Recurrent Neural Networks (RNNs) for language modeling and introduce Matrix-to-Matrix RNN (M$^2$RNN): an architecture with matrix-valued hidden states and expressive non-linear state transitions. We demonstrate that the language modeling performance of non-linear RNNs is limited by their state size. We also demonstrate how the state size expansion mechanism enables efficient use of tensor cores. Empirically, M$^2$RNN achieves perfect state tracking generalization at sequence lengths not seen during training. These benefits also translate to large-scale language modeling. In hybrid settings that interleave recurrent layers with attention, Hybrid M$^2$RNN outperforms equivalent Gated DeltaNet hybrids by $0.4$-$0.5$ perplexity points on a 7B MoE model, while using $3\times$ smaller state sizes for the recurrent layers. Notably, replacing even a single recurrent layer with M$^2$RNN in an existing hybrid architecture yields accuracy gains comparable to Hybrid M$^2$RNN with minimal impact on training throughput. Further, the Hybrid Gated DeltaNet models with a single M$^2$RNN layer also achieve superior long-context generalization, outperforming state-of-the-art hybrid linear attention architectures by up to $8$ points on LongBench. Together, these results establish non-linear RNN layers as a compelling building block for efficient and scalable language models.
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
Mar 05, 2026Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. While FlashAttention-3 optimized attention for Hopper GPUs through asynchronous execution and warp specialization, it primarily targets the H100 architecture. The AI industry has rapidly transitioned to deploying Blackwell-based systems such as the B200 and GB200, which exhibit fundamentally different performance characteristics due to asymmetric hardware scaling: tensor core throughput doubles while other functional units (shared memory bandwidth, exponential units) scale more slowly or remain unchanged. We develop several techniques to address these shifting bottlenecks on Blackwell GPUs: (1) redesigned pipelines that exploit fully asynchronous MMA operations and larger tile sizes, (2) software-emulated exponential and conditional softmax rescaling that reduces non-matmul operations, and (3) leveraging tensor memory and the 2-CTA MMA mode to reduce shared memory traffic and atomic adds in the backward pass. We demonstrate that our method, FlashAttention-4, achieves up to 1.3$\times$ speedup over cuDNN 9.13 and 2.7$\times$ over Triton on B200 GPUs with BF16, reaching up to 1613 TFLOPs/s (71% utilization). Beyond algorithmic innovations, we implement FlashAttention-4 entirely in CuTe-DSL embedded in Python, achieving 20-30$\times$ faster compile times compared to traditional C++ template-based approaches while maintaining full expressivity.
AI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
Speculative Speculative Decoding
Mar 03, 2026Autoregressive decoding is bottlenecked by its sequential nature. Speculative decoding has become a standard way to accelerate inference by using a fast draft model to predict upcoming tokens from a slower target model, and then verifying them in parallel with a single target model forward pass. However, speculative decoding itself relies on a sequential dependence between speculation and verification. We introduce speculative speculative decoding (SSD) to parallelize these operations. While a verification is ongoing, the draft model predicts likely verification outcomes and prepares speculations pre-emptively for them. If the actual verification outcome is then in the predicted set, a speculation can be returned immediately, eliminating drafting overhead entirely. We identify three key challenges presented by speculative speculative decoding, and suggest principled methods to solve each. The result is Saguaro, an optimized SSD algorithm. Our implementation is up to 2x faster than optimized speculative decoding baselines and up to 5x faster than autoregressive decoding with open source inference engines.
When RL Meets Adaptive Speculative Training: A Unified Training-Serving System
Feb 06, 2026Speculative decoding can significantly accelerate LLM serving, yet most deployments today disentangle speculator training from serving, treating speculator training as a standalone offline modeling problem. We show that this decoupled formulation introduces substantial deployment and adaptation lag: (1) high time-to-serve, since a speculator must be trained offline for a considerable period before deployment; (2) delayed utility feedback, since the true end-to-end decoding speedup is only known after training and cannot be inferred reliably from acceptance rate alone due to model-architecture and system-level overheads; and (3) domain-drift degradation, as the target model is repurposed to new domains and the speculator becomes stale and less effective. To address these issues, we present Aurora, a unified training-serving system that closes the loop by continuously learning a speculator directly from live inference traces. Aurora reframes online speculator learning as an asynchronous reinforcement-learning problem: accepted tokens provide positive feedback, while rejected speculator proposals provide implicit negative feedback that we exploit to improve sample efficiency. Our design integrates an SGLang-based inference server with an asynchronous training server, enabling hot-swapped speculator updates without service interruption. Crucially, Aurora supports day-0 deployment: a speculator can be served immediately and rapidly adapted to live traffic, improving system performance while providing immediate utility feedback. Across experiments, Aurora achieves a 1.5x day-0 speedup on recently released frontier models (e.g., MiniMax M2.1 229B and Qwen3-Coder-Next 80B). Aurora also adapts effectively to distribution shifts in user traffic, delivering an additional 1.25x speedup over a well-trained but static speculator on widely used models (e.g., Qwen3 and Llama3).
SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
Dec 16, 2025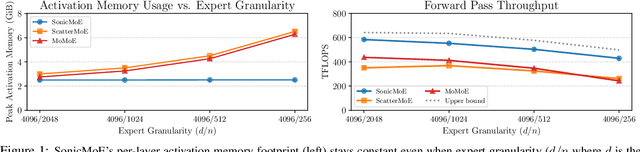
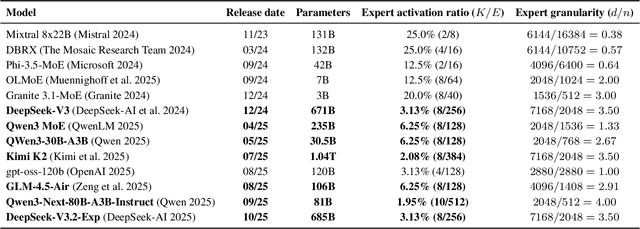
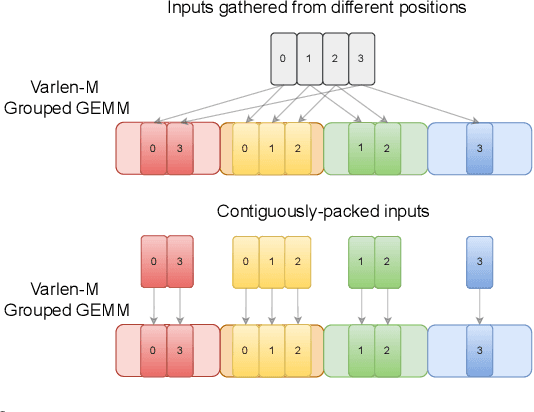
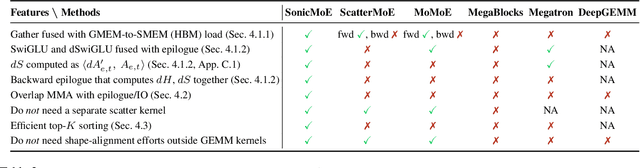
Mixture of Experts (MoE) models have emerged as the de facto architecture for scaling up language models without significantly increasing the computational cost. Recent MoE models demonstrate a clear trend towards high expert granularity (smaller expert intermediate dimension) and higher sparsity (constant number of activated experts with higher number of total experts), which improve model quality per FLOP. However, fine-grained MoEs suffer from increased activation memory footprint and reduced hardware efficiency due to higher IO costs, while sparser MoEs suffer from wasted computations due to padding in Grouped GEMM kernels. In response, we propose a memory-efficient algorithm to compute the forward and backward passes of MoEs with minimal activation caching for the backward pass. We also design GPU kernels that overlap memory IO with computation benefiting all MoE architectures. Finally, we propose a novel "token rounding" method that minimizes the wasted compute due to padding in Grouped GEMM kernels. As a result, our method SonicMoE reduces activation memory by 45% and achieves a 1.86x compute throughput improvement on Hopper GPUs compared to ScatterMoE's BF16 MoE kernel for a fine-grained 7B MoE. Concretely, SonicMoE on 64 H100s achieves a training throughput of 213 billion tokens per day comparable to ScatterMoE's 225 billion tokens per day on 96 H100s for a 7B MoE model training with FSDP-2 using the lm-engine codebase. Under high MoE sparsity settings, our tile-aware token rounding algorithm yields an additional 1.16x speedup on kernel execution time compared to vanilla top-$K$ routing while maintaining similar downstream performance. We open-source all our kernels to enable faster MoE model training.
Beat the long tail: Distribution-Aware Speculative Decoding for RL Training
Nov 17, 2025Reinforcement learning(RL) post-training has become essential for aligning large language models (LLMs), yet its efficiency is increasingly constrained by the rollout phase, where long trajectories are generated token by token. We identify a major bottleneck:the long-tail distribution of rollout lengths, where a small fraction of long generations dominates wall clock time and a complementary opportunity; the availability of historical rollouts that reveal stable prompt level patterns across training epochs. Motivated by these observations, we propose DAS, a Distribution Aware Speculative decoding framework that accelerates RL rollouts without altering model outputs. DAS integrates two key ideas: an adaptive, nonparametric drafter built from recent rollouts using an incrementally maintained suffix tree, and a length aware speculation policy that allocates more aggressive draft budgets to long trajectories that dominate makespan. This design exploits rollout history to sustain acceptance while balancing base and token level costs during decoding. Experiments on math and code reasoning tasks show that DAS reduces rollout time up to 50% while preserving identical training curves, demonstrating that distribution-aware speculative decoding can significantly accelerate RL post training without compromising learning quality.
Log-Linear Attention
Jun 05, 2025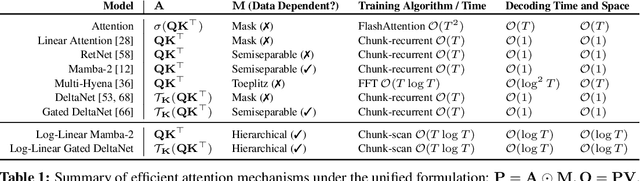
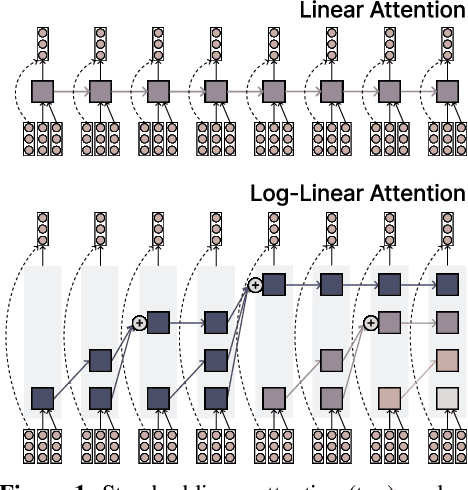
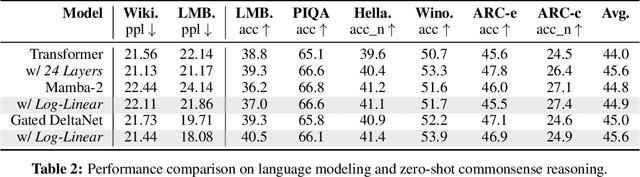
The attention mechanism in Transformers is an important primitive for accurate and scalable sequence modeling. Its quadratic-compute and linear-memory complexity however remain significant bottlenecks. Linear attention and state-space models enable linear-time, constant-memory sequence modeling and can moreover be trained efficiently through matmul-rich parallelization across sequence length. However, at their core these models are still RNNs, and thus their use of a fixed-size hidden state to model the context is a fundamental limitation. This paper develops log-linear attention, an attention mechanism that balances linear attention's efficiency and the expressiveness of softmax attention. Log-linear attention replaces the fixed-size hidden state with a logarithmically growing set of hidden states. We show that with a particular growth function, log-linear attention admits a similarly matmul-rich parallel form whose compute cost is log-linear in sequence length. Log-linear attention is a general framework and can be applied on top of existing linear attention variants. As case studies, we instantiate log-linear variants of two recent architectures -- Mamba-2 and Gated DeltaNet -- and find they perform well compared to their linear-time variants.
Hardware-Efficient Attention for Fast Decoding
May 27, 2025



LLM decoding is bottlenecked for large batches and long contexts by loading the key-value (KV) cache from high-bandwidth memory, which inflates per-token latency, while the sequential nature of decoding limits parallelism. We analyze the interplay among arithmetic intensity, parallelization, and model quality and question whether current architectures fully exploit modern hardware. This work redesigns attention to perform more computation per byte loaded from memory to maximize hardware efficiency without trading off parallel scalability. We first propose Grouped-Tied Attention (GTA), a simple variant that combines and reuses key and value states, reducing memory transfers without compromising model quality. We then introduce Grouped Latent Attention (GLA), a parallel-friendly latent attention paired with low-level optimizations for fast decoding while maintaining high model quality. Experiments show that GTA matches Grouped-Query Attention (GQA) quality while using roughly half the KV cache and that GLA matches Multi-head Latent Attention (MLA) and is easier to shard. Our optimized GLA kernel is up to 2$\times$ faster than FlashMLA, for example, in a speculative decoding setting when the query length exceeds one. Furthermore, by fetching a smaller KV cache per device, GLA reduces end-to-end latency and increases throughput in online serving benchmarks by up to 2$\times$.