 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleSim: Serving Large-Scale Multi-Agent Simulation with Invocation Distance-Based Memory Management
Jan 29, 2026LLM-based multi-agent simulations are increasingly adopted across application domains, but remain difficult to scale due to GPU memory pressure. Each agent maintains private GPU-resident states, including models, prefix caches, and adapters, which quickly exhaust device memory as the agent count grows. We identify two key properties of these workloads: sparse agent activation and an estimable agent invocation order. Based on an analysis of representative workload classes, we introduce invocation distance, a unified abstraction that estimates the relative order in which agents will issue future LLM requests. Leveraging this abstraction, we present ScaleSim, a memory-efficient LLM serving system for large-scale multi-agent simulations. ScaleSim enables proactive prefetching and priority-based eviction, supports diverse agent-specific memory through a modular interface, and achieves up to 1.74x speedup over SGLang on simulation benchmarks.
Marconi: Prefix Caching for the Era of Hybrid LLMs
Nov 28, 2024



Hybrid models that combine the language modeling capabilities of Attention layers with the efficiency of Recurrent layers (e.g., State Space Models) have gained traction in practically supporting long contexts in Large Language Model serving. Yet, the unique properties of these models complicate the usage of complementary efficiency optimizations such as prefix caching that skip redundant computations across requests. Most notably, their use of in-place state updates for recurrent layers precludes rolling back cache entries for partial sequence overlaps, and instead mandates only exact-match cache hits; the effect is a deluge of (large) cache entries per sequence, most of which yield minimal reuse opportunities. We present Marconi, the first system that supports efficient prefix caching with Hybrid LLMs. Key to Marconi are its novel admission and eviction policies that more judiciously assess potential cache entries based not only on recency, but also on (1) forecasts of their reuse likelihood across a taxonomy of different hit scenarios, and (2) the compute savings that hits deliver relative to memory footprints. Across diverse workloads and Hybrid models, Marconi achieves up to 34.4$\times$ higher token hit rates (71.1% or 617 ms lower TTFT) compared to state-of-the-art prefix caching systems.
Lazarus: Resilient and Elastic Training of Mixture-of-Experts Models with Adaptive Expert Placement
Jul 05, 2024



Sparsely-activated Mixture-of-Experts (MoE) architecture has increasingly been adopted to further scale large language models (LLMs) due to its sub-linear scaling for computation costs. However, frequent failures still pose significant challenges as training scales. The cost of even a single failure is significant, as all GPUs need to wait idle until the failure is resolved, potentially losing considerable training progress as training has to restart from checkpoints. Existing solutions for efficient fault-tolerant training either lack elasticity or rely on building resiliency into pipeline parallelism, which cannot be applied to MoE models due to the expert parallelism strategy adopted by the MoE architecture. We present Lazarus, a system for resilient and elastic training of MoE models. Lazarus adaptively allocates expert replicas to address the inherent imbalance in expert workload and speeds-up training, while a provably optimal expert placement algorithm is developed to maximize the probability of recovery upon failures. Through adaptive expert placement and a flexible token dispatcher, Lazarus can also fully utilize all available nodes after failures, leaving no GPU idle. Our evaluation shows that Lazarus outperforms existing MoE training systems by up to 5.7x under frequent node failures and 3.4x on a real spot instance trace.
Zen: Near-Optimal Sparse Tensor Synchronization for Distributed DNN Training
Sep 23, 2023Distributed training is the de facto standard to scale up the training of Deep Neural Networks (DNNs) with multiple GPUs. The performance bottleneck of distributed training lies in communications for gradient synchronization. Recently, practitioners have observed sparsity in gradient tensors, suggesting the potential to reduce the traffic volume in communication and improve end-to-end training efficiency. Yet, the optimal communication scheme to fully leverage sparsity is still missing. This paper aims to address this gap. We first analyze the characteristics of sparse tensors in popular DNN models to understand the fundamentals of sparsity. We then systematically explore the design space of communication schemes for sparse tensors and find the optimal one. % We then find the optimal scheme based on the characteristics by systematically exploring the design space. We also develop a gradient synchronization system called Zen that approximately realizes it for sparse tensors. We demonstrate that Zen can achieve up to 5.09x speedup in communication time and up to 2.48x speedup in training throughput compared to the state-of-the-art methods.
ByteComp: Revisiting Gradient Compression in Distributed Training
Jun 06, 2022
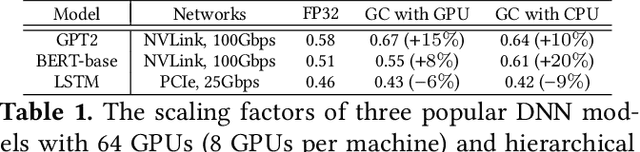


Gradient compression (GC) is a promising approach to addressing the communication bottleneck in distributed deep learning (DDL). However, it is challenging to find the optimal compression strategy for applying GC to DDL because of the intricate interactions among tensors. To fully unleash the benefits of GC, two questions must be addressed: 1) How to express all compression strategies and the corresponding interactions among tensors of any DDL training job? 2) How to quickly select a near-optimal compression strategy? In this paper, we propose ByteComp to answer these questions. It first designs a decision tree abstraction to express all the compression strategies and develops empirical models to timeline tensor computation, communication, and compression to enable ByteComp to derive the intricate interactions among tensors. It then designs a compression decision algorithm that analyzes tensor interactions to eliminate and prioritize strategies and optimally offloads compression to CPUs. Experimental evaluations show that ByteComp can improve the training throughput over the start-of-the-art compression-enabled system by up to 77% for representative DDL training jobs. Moreover, the computational time needed to select the compression strategy is measured in milliseconds, and the selected strategy is only a few percent from optimal.
MergeComp: A Compression Scheduler for Scalable Communication-Efficient Distributed Training
Mar 28, 2021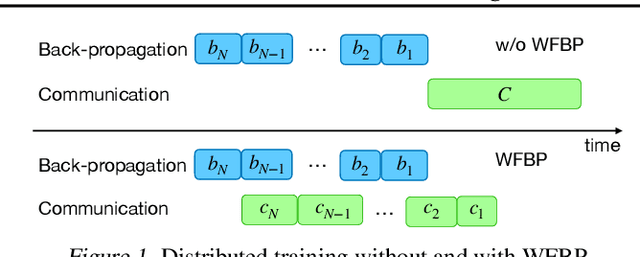
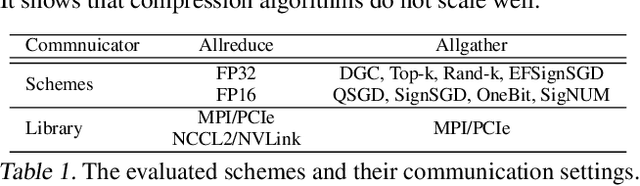
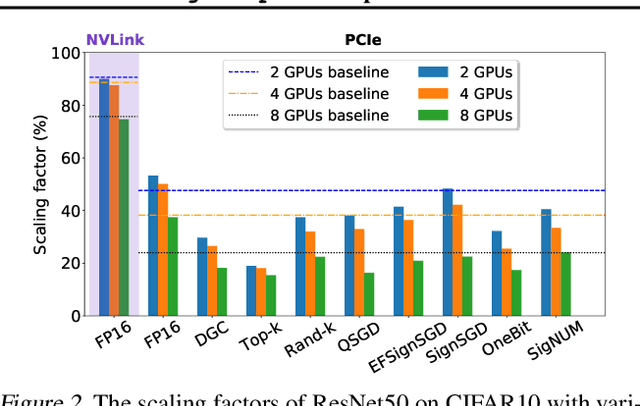
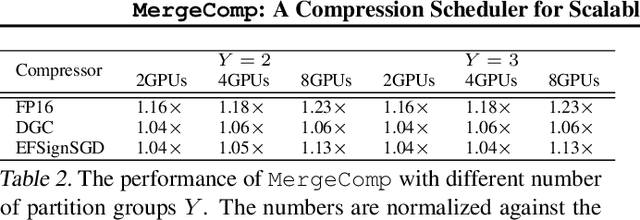
Large-scale distributed training is increasingly becoming communication bound. Many gradient compression algorithms have been proposed to reduce the communication overhead and improve scalability. However, it has been observed that in some cases gradient compression may even harm the performance of distributed training. In this paper, we propose MergeComp, a compression scheduler to optimize the scalability of communication-efficient distributed training. It automatically schedules the compression operations to optimize the performance of compression algorithms without the knowledge of model architectures or system parameters. We have applied MergeComp to nine popular compression algorithms. Our evaluations show that MergeComp can improve the performance of compression algorithms by up to 3.83x without losing accuracy. It can even achieve a scaling factor of distributed training up to 99% over high-speed networks.