 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLT2: Linear-Time Looped Transformers
May 20, 2026Looped Transformers (LT) have emerged as a powerful architecture by iterating their layers multiple times before decoding the final token. However, pairing them with full attention retains quadratic complexity, making them computationally expensive and slow. We introduce LT2 (Linear-Time Looped Transformers), a family of looped architectures that replace quadratic softmax attention with subquadratic, linear-time attention. We study two variants: LT2-linear with linear attention and LT2-sparse with sparse attention. We find that looping uniquely synergizes with these variants: it enables iterative memory refinement in linear attention and progressively expands the effective receptive field in sparse attention. We formalize these benefits theoretically and demonstrate consistent empirical gains across controlled recall, state-tracking, and language modeling tasks. We then explore LT2-hybrid, which combines different attention variants in a looped setting. Two variants are especially promising: LT2-hybrid (GDN+DSA), which interleaves linear and sparse attention to maximize efficiency and matches the standard looped transformer's quality at fully linear-time cost; and LT2-hybrid (Full+GDN), which interleaves GDN with a small fraction of full attention layers to maximize quality, surpassing the standard looped transformer in both performance and efficiency. We also show how to convert a pre-trained LT into an LT2-hybrid model. With about 1B tokens of training, our converted model, Ouro-hybrid-1.4B, outperforms industry-level 1B models and is competitive with industry-level 4B models while retaining the speed benefits of linear-time attention. Together, these results show a clear path toward making looped transformers more scalable and advancing efficient, capable small language models.
SuperGen: An Efficient Ultra-high-resolution Video Generation System with Sketching and Tiling
Aug 25, 2025Diffusion models have recently achieved remarkable success in generative tasks (e.g., image and video generation), and the demand for high-quality content (e.g., 2K/4K videos) is rapidly increasing across various domains. However, generating ultra-high-resolution videos on existing standard-resolution (e.g., 720p) platforms remains challenging due to the excessive re-training requirements and prohibitively high computational and memory costs. To this end, we introduce SuperGen, an efficient tile-based framework for ultra-high-resolution video generation. SuperGen features a novel training-free algorithmic innovation with tiling to successfully support a wide range of resolutions without additional training efforts while significantly reducing both memory footprint and computational complexity. Moreover, SuperGen incorporates a tile-tailored, adaptive, region-aware caching strategy that accelerates video generation by exploiting redundancy across denoising steps and spatial regions. SuperGen also integrates cache-guided, communication-minimized tile parallelism for enhanced throughput and minimized latency. Evaluations demonstrate that SuperGen harvests the maximum performance gains while achieving high output quality across various benchmarks.
Zen: Near-Optimal Sparse Tensor Synchronization for Distributed DNN Training
Sep 23, 2023Distributed training is the de facto standard to scale up the training of Deep Neural Networks (DNNs) with multiple GPUs. The performance bottleneck of distributed training lies in communications for gradient synchronization. Recently, practitioners have observed sparsity in gradient tensors, suggesting the potential to reduce the traffic volume in communication and improve end-to-end training efficiency. Yet, the optimal communication scheme to fully leverage sparsity is still missing. This paper aims to address this gap. We first analyze the characteristics of sparse tensors in popular DNN models to understand the fundamentals of sparsity. We then systematically explore the design space of communication schemes for sparse tensors and find the optimal one. % We then find the optimal scheme based on the characteristics by systematically exploring the design space. We also develop a gradient synchronization system called Zen that approximately realizes it for sparse tensors. We demonstrate that Zen can achieve up to 5.09x speedup in communication time and up to 2.48x speedup in training throughput compared to the state-of-the-art methods.
ByteComp: Revisiting Gradient Compression in Distributed Training
Jun 06, 2022
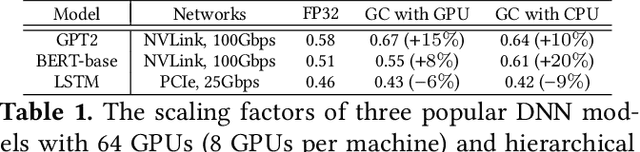


Gradient compression (GC) is a promising approach to addressing the communication bottleneck in distributed deep learning (DDL). However, it is challenging to find the optimal compression strategy for applying GC to DDL because of the intricate interactions among tensors. To fully unleash the benefits of GC, two questions must be addressed: 1) How to express all compression strategies and the corresponding interactions among tensors of any DDL training job? 2) How to quickly select a near-optimal compression strategy? In this paper, we propose ByteComp to answer these questions. It first designs a decision tree abstraction to express all the compression strategies and develops empirical models to timeline tensor computation, communication, and compression to enable ByteComp to derive the intricate interactions among tensors. It then designs a compression decision algorithm that analyzes tensor interactions to eliminate and prioritize strategies and optimally offloads compression to CPUs. Experimental evaluations show that ByteComp can improve the training throughput over the start-of-the-art compression-enabled system by up to 77% for representative DDL training jobs. Moreover, the computational time needed to select the compression strategy is measured in milliseconds, and the selected strategy is only a few percent from optimal.
MergeComp: A Compression Scheduler for Scalable Communication-Efficient Distributed Training
Mar 28, 2021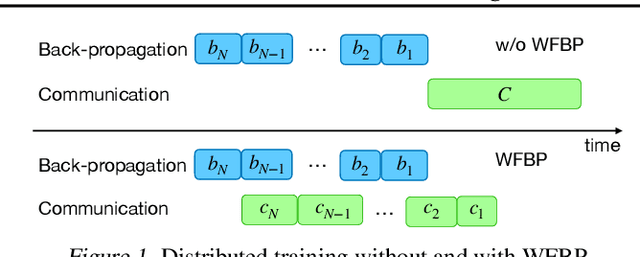
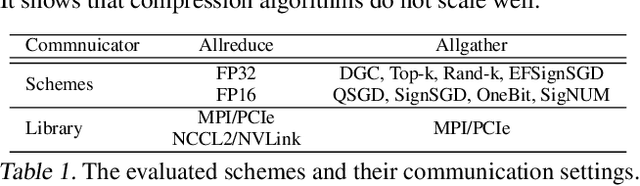
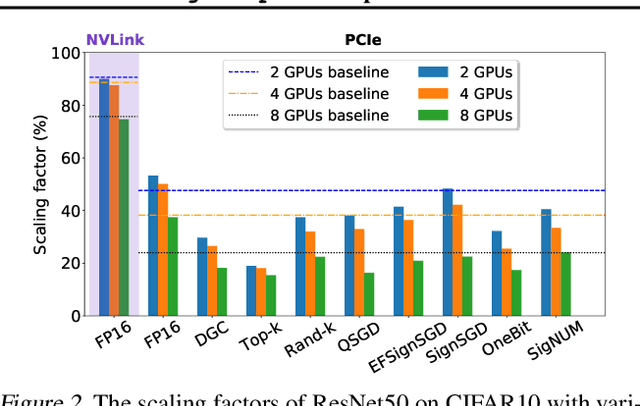
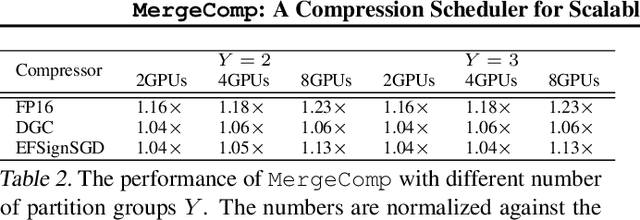
Large-scale distributed training is increasingly becoming communication bound. Many gradient compression algorithms have been proposed to reduce the communication overhead and improve scalability. However, it has been observed that in some cases gradient compression may even harm the performance of distributed training. In this paper, we propose MergeComp, a compression scheduler to optimize the scalability of communication-efficient distributed training. It automatically schedules the compression operations to optimize the performance of compression algorithms without the knowledge of model architectures or system parameters. We have applied MergeComp to nine popular compression algorithms. Our evaluations show that MergeComp can improve the performance of compression algorithms by up to 3.83x without losing accuracy. It can even achieve a scaling factor of distributed training up to 99% over high-speed networks.