 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyright Detective: A Forensic System to Evidence LLMs Flickering Copyright Leakage Risks
Feb 05, 2026We present Copyright Detective, the first interactive forensic system for detecting, analyzing, and visualizing potential copyright risks in LLM outputs. The system treats copyright infringement versus compliance as an evidence discovery process rather than a static classification task due to the complex nature of copyright law. It integrates multiple detection paradigms, including content recall testing, paraphrase-level similarity analysis, persuasive jailbreak probing, and unlearning verification, within a unified and extensible framework. Through interactive prompting, response collection, and iterative workflows, our system enables systematic auditing of verbatim memorization and paraphrase-level leakage, supporting responsible deployment and transparent evaluation of LLM copyright risks even with black-box access.
DEL-ToM: Inference-Time Scaling for Theory-of-Mind Reasoning via Dynamic Epistemic Logic
May 22, 2025Theory-of-Mind (ToM) tasks pose a unique challenge for small language models (SLMs) with limited scale, which often lack the capacity to perform deep social reasoning. In this work, we propose DEL-ToM, a framework that improves ToM reasoning through inference-time scaling rather than architectural changes. Our approach decomposes ToM tasks into a sequence of belief updates grounded in Dynamic Epistemic Logic (DEL), enabling structured and transparent reasoning. We train a verifier, called the Process Belief Model (PBM), to score each belief update step using labels generated automatically via a DEL simulator. During inference, candidate belief traces generated by a language model are evaluated by the PBM, and the highest-scoring trace is selected. This allows SLMs to emulate more deliberate reasoning by allocating additional compute at test time. Experiments across multiple model scales and benchmarks show that DEL-ToM consistently improves performance, demonstrating that verifiable belief supervision can significantly enhance ToM abilities of SLMs without retraining.
VTBench: Evaluating Visual Tokenizers for Autoregressive Image Generation
May 19, 2025Autoregressive (AR) models have recently shown strong performance in image generation, where a critical component is the visual tokenizer (VT) that maps continuous pixel inputs to discrete token sequences. The quality of the VT largely defines the upper bound of AR model performance. However, current discrete VTs fall significantly behind continuous variational autoencoders (VAEs), leading to degraded image reconstructions and poor preservation of details and text. Existing benchmarks focus on end-to-end generation quality, without isolating VT performance. To address this gap, we introduce VTBench, a comprehensive benchmark that systematically evaluates VTs across three core tasks: Image Reconstruction, Detail Preservation, and Text Preservation, and covers a diverse range of evaluation scenarios. We systematically assess state-of-the-art VTs using a set of metrics to evaluate the quality of reconstructed images. Our findings reveal that continuous VAEs produce superior visual representations compared to discrete VTs, particularly in retaining spatial structure and semantic detail. In contrast, the degraded representations produced by discrete VTs often lead to distorted reconstructions, loss of fine-grained textures, and failures in preserving text and object integrity. Furthermore, we conduct experiments on GPT-4o image generation and discuss its potential AR nature, offering new insights into the role of visual tokenization. We release our benchmark and codebase publicly to support further research and call on the community to develop strong, general-purpose open-source VTs.
Sensitivity Meets Sparsity: The Impact of Extremely Sparse Parameter Patterns on Theory-of-Mind of Large Language Models
Apr 05, 2025



This paper investigates the emergence of Theory-of-Mind (ToM) capabilities in large language models (LLMs) from a mechanistic perspective, focusing on the role of extremely sparse parameter patterns. We introduce a novel method to identify ToM-sensitive parameters and reveal that perturbing as little as 0.001% of these parameters significantly degrades ToM performance while also impairing contextual localization and language understanding. To understand this effect, we analyze their interaction with core architectural components of LLMs. Our findings demonstrate that these sensitive parameters are closely linked to the positional encoding module, particularly in models using Rotary Position Embedding (RoPE), where perturbations disrupt dominant-frequency activations critical for contextual processing. Furthermore, we show that perturbing ToM-sensitive parameters affects LLM's attention mechanism by modulating the angle between queries and keys under positional encoding. These insights provide a deeper understanding of how LLMs acquire social reasoning abilities, bridging AI interpretability with cognitive science. Our results have implications for enhancing model alignment, mitigating biases, and improving AI systems designed for human interaction.
ALinFiK: Learning to Approximate Linearized Future Influence Kernel for Scalable Third-Parity LLM Data Valuation
Mar 02, 2025Large Language Models (LLMs) heavily rely on high-quality training data, making data valuation crucial for optimizing model performance, especially when working within a limited budget. In this work, we aim to offer a third-party data valuation approach that benefits both data providers and model developers. We introduce a linearized future influence kernel (LinFiK), which assesses the value of individual data samples in improving LLM performance during training. We further propose ALinFiK, a learning strategy to approximate LinFiK, enabling scalable data valuation. Our comprehensive evaluations demonstrate that this approach surpasses existing baselines in effectiveness and efficiency, demonstrating significant scalability advantages as LLM parameters increase.
Fox-1 Technical Report
Nov 08, 2024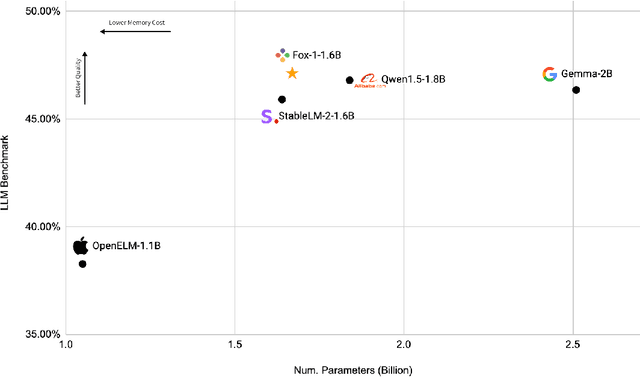

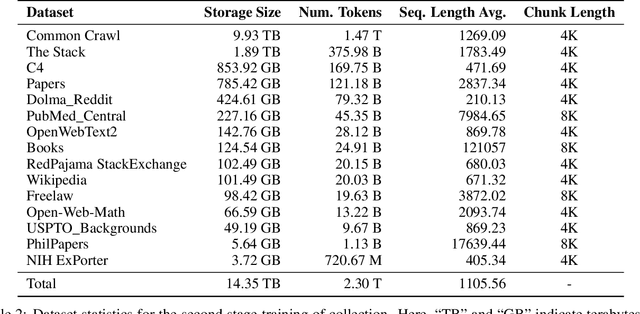
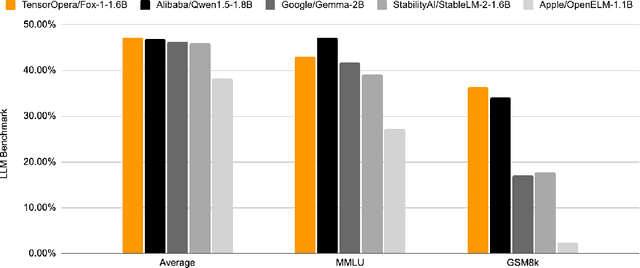
We present Fox-1, a series of small language models (SLMs) consisting of Fox-1-1.6B and Fox-1-1.6B-Instruct-v0.1. These models are pre-trained on 3 trillion tokens of web-scraped document data and fine-tuned with 5 billion tokens of instruction-following and multi-turn conversation data. Aiming to improve the pre-training efficiency, Fox-1-1.6B model introduces a novel 3-stage data curriculum across all the training data with 2K-8K sequence length. In architecture design, Fox-1 features a deeper layer structure, an expanded vocabulary, and utilizes Grouped Query Attention (GQA), offering a performant and efficient architecture compared to other SLMs. Fox-1 achieves better or on-par performance in various benchmarks compared to StableLM-2-1.6B, Gemma-2B, Qwen1.5-1.8B, and OpenELM1.1B, with competitive inference speed and throughput. The model weights have been released under the Apache 2.0 license, where we aim to promote the democratization of LLMs and make them fully accessible to the whole open-source community.
Alopex: A Computational Framework for Enabling On-Device Function Calls with LLMs
Nov 07, 2024



The rapid advancement of Large Language Models (LLMs) has led to their increased integration into mobile devices for personalized assistance, which enables LLMs to call external API functions to enhance their performance. However, challenges such as data scarcity, ineffective question formatting, and catastrophic forgetting hinder the development of on-device LLM agents. To tackle these issues, we propose Alopex, a framework that enables precise on-device function calls using the Fox LLM. Alopex introduces a logic-based method for generating high-quality training data and a novel ``description-question-output'' format for fine-tuning, reducing risks of function information leakage. Additionally, a data mixing strategy is used to mitigate catastrophic forgetting, combining function call data with textbook datasets to enhance performance in various tasks. Experimental results show that Alopex improves function call accuracy and significantly reduces catastrophic forgetting, providing a robust solution for integrating function call capabilities into LLMs without manual intervention.
Do LLMs Know to Respect Copyright Notice?
Nov 02, 2024



Prior study shows that LLMs sometimes generate content that violates copyright. In this paper, we study another important yet underexplored problem, i.e., will LLMs respect copyright information in user input, and behave accordingly? The research problem is critical, as a negative answer would imply that LLMs will become the primary facilitator and accelerator of copyright infringement behavior. We conducted a series of experiments using a diverse set of language models, user prompts, and copyrighted materials, including books, news articles, API documentation, and movie scripts. Our study offers a conservative evaluation of the extent to which language models may infringe upon copyrights when processing user input containing protected material. This research emphasizes the need for further investigation and the importance of ensuring LLMs respect copyright regulations when handling user input to prevent unauthorized use or reproduction of protected content. We also release a benchmark dataset serving as a test bed for evaluating infringement behaviors by LLMs and stress the need for future alignment.
Weighted Diversified Sampling for Efficient Data-Driven Single-Cell Gene-Gene Interaction Discovery
Oct 21, 2024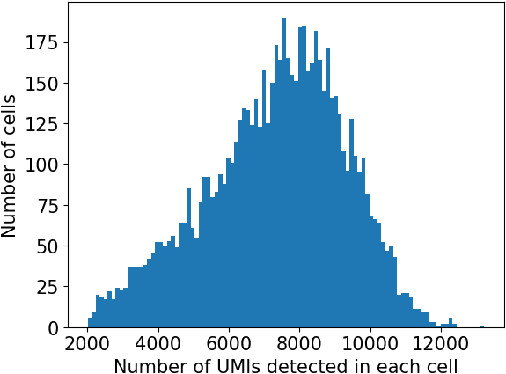
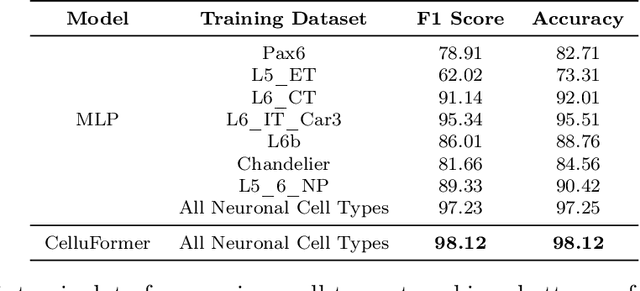
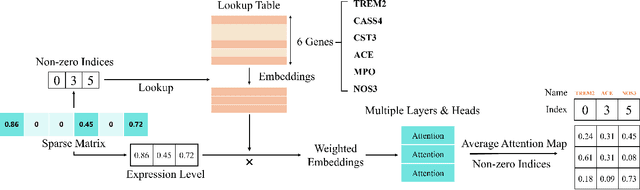
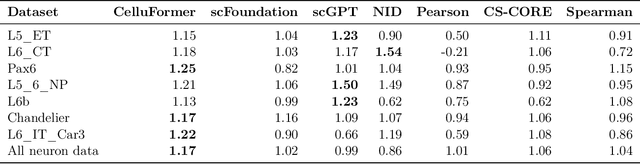
Gene-gene interactions play a crucial role in the manifestation of complex human diseases. Uncovering significant gene-gene interactions is a challenging task. Here, we present an innovative approach utilizing data-driven computational tools, leveraging an advanced Transformer model, to unearth noteworthy gene-gene interactions. Despite the efficacy of Transformer models, their parameter intensity presents a bottleneck in data ingestion, hindering data efficiency. To mitigate this, we introduce a novel weighted diversified sampling algorithm. This algorithm computes the diversity score of each data sample in just two passes of the dataset, facilitating efficient subset generation for interaction discovery. Our extensive experimentation demonstrates that by sampling a mere 1\% of the single-cell dataset, we achieve performance comparable to that of utilizing the entire dataset.
SpaLLM: Unified Compressive Adaptation of Large Language Models with Sketching
Oct 08, 2024



Compressive adaptation approaches, such as QLoRA, are widely popular alternatives for reducing memory requirements during fine-tuning of large language models (LLMs) while producing models capable of handling various downstream tasks. The key idea is to employ a "two-tower" architecture: compressing pre-trained LLM parameters into compact representations and fine-tuning the additive full-precision adapter, which typically has few tunable parameters in low-rank format. However, the strict algebraic assumptions, such as low-rank assumption, and the complexity of composing two-tower architectures are some of the known shortcomings, resulting in a poor accuracy-efficiency trade-off. In response to these known limitations, we propose SpaLLM (Sketched Parameter Adaptation of LLMs), a novel compressive adaptation approach for LLMs. This method is also the first to illustrate parameter-sharing compression methods for LLM fine-tuning, which, unlike QLoRA, are free from strict low-rank algebraic assumptions on adapters. Furthermore, our proposal unifies model compression and adaptation into a single, streamlined process, eliminating the need for two-tower architectures. SpaLLM sketches pre-trained LLM weights into lookup tables and directly fine-tunes the values in these tables. This approach simplifies LLMs' compressive adaptation workflow, potentially improves multi-user serving efficiency, and delivers significantly better accuracy for both natural language understanding and generation tasks. Moreover, by avoiding the "two-tower" architecture, our framework only requires one compressed matrix multiplication per layer during inference, demonstrating superior inference efficiency compared to previous methods.