 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIG to Heal: Scaling General-purpose Agent Collaboration via Explainable Dynamic Decision Paths
Feb 27, 2026The increasingly popular agentic AI paradigm promises to harness the power of multiple, general-purpose large language model (LLM) agents to collaboratively complete complex tasks. While many agentic AI systems utilize predefined workflows or agent roles in order to reduce complexity, ideally these agents would be truly autonomous, able to achieve emergent collaboration even as the number of collaborating agents increases. Yet in practice, such unstructured interactions can lead to redundant work and cascading failures that are difficult to interpret or correct. In this work, we study multi-agent systems composed of general-purpose LLM agents that operate without predefined roles, control flow, or communication constraints, relying instead on emergent collaboration to solve problems. We introduce the Dynamic Interaction Graph (DIG), which captures emergent collaboration as a time-evolving causal network of agent activations and interactions. DIG makes emergent collaboration observable and explainable for the first time, enabling real-time identification, explanation, and correction of collaboration-induced error patterns directly from agents' collaboration paths. Thus, DIG fills a critical gap in understanding how general LLM agents solve problems together in truly agentic multi-agent systems. The project webpage can be found at: https://happyeureka.github.io/dig.
RooflineBench: A Benchmarking Framework for On-Device LLMs via Roofline Analysis
Feb 12, 2026The transition toward localized intelligence through Small Language Models (SLMs) has intensified the need for rigorous performance characterization on resource-constrained edge hardware. However, objectively measuring the theoretical performance ceilings of diverse architectures across heterogeneous platforms remains a formidable challenge. In this work, we propose a systematic framework based on the Roofline model that unifies architectural primitives and hardware constraints through the lens of operational intensity (OI). By defining an inference-potential region, we introduce the Relative Inference Potential as a novel metric to compare efficiency differences between Large Language Models (LLMs) on the same hardware substrate. Extensive empirical analysis across diverse compute tiers reveals that variations in performance and OI are significantly influenced by sequence length. We further identify a critical regression in OI as model depth increases. Additionally, our findings highlight an efficiency trap induced by hardware heterogeneity and demonstrate how structural refinements, such as Multi-head Latent Attention (M LA), can effectively unlock latent inference potential across various hardware substrates. These insights provide actionable directions for hardware-software co-design to align neural structures with physical constraints in on-device intelligence. The released code is available in the Appendix C.
Evaluating Selective Encryption Against Gradient Inversion Attacks
Aug 06, 2025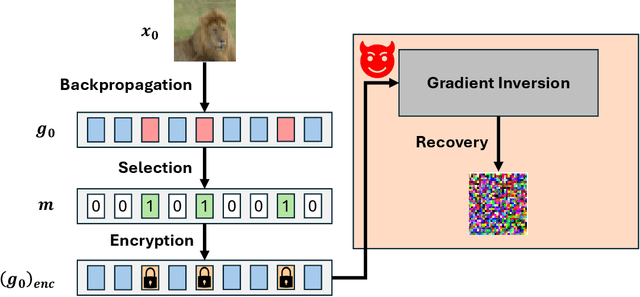

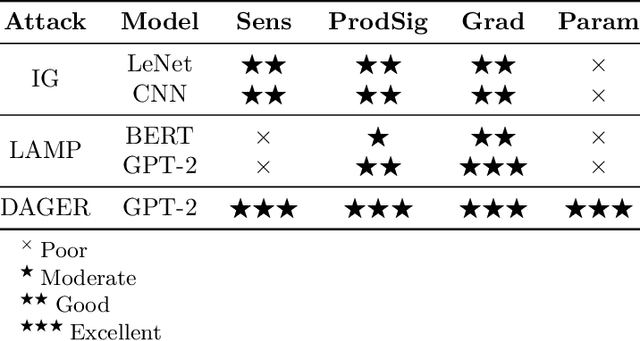

Gradient inversion attacks pose significant privacy threats to distributed training frameworks such as federated learning, enabling malicious parties to reconstruct sensitive local training data from gradient communications between clients and an aggregation server during the aggregation process. While traditional encryption-based defenses, such as homomorphic encryption, offer strong privacy guarantees without compromising model utility, they often incur prohibitive computational overheads. To mitigate this, selective encryption has emerged as a promising approach, encrypting only a subset of gradient data based on the data's significance under a certain metric. However, there have been few systematic studies on how to specify this metric in practice. This paper systematically evaluates selective encryption methods with different significance metrics against state-of-the-art attacks. Our findings demonstrate the feasibility of selective encryption in reducing computational overhead while maintaining resilience against attacks. We propose a distance-based significance analysis framework that provides theoretical foundations for selecting critical gradient elements for encryption. Through extensive experiments on different model architectures (LeNet, CNN, BERT, GPT-2) and attack types, we identify gradient magnitude as a generally effective metric for protection against optimization-based gradient inversions. However, we also observe that no single selective encryption strategy is universally optimal across all attack scenarios, and we provide guidelines for choosing appropriate strategies for different model architectures and privacy requirements.
Toward Super Agent System with Hybrid AI Routers
Apr 11, 2025AI Agents powered by Large Language Models are transforming the world through enormous applications. A super agent has the potential to fulfill diverse user needs, such as summarization, coding, and research, by accurately understanding user intent and leveraging the appropriate tools to solve tasks. However, to make such an agent viable for real-world deployment and accessible at scale, significant optimizations are required to ensure high efficiency and low cost. This paper presents a design of the Super Agent System. Upon receiving a user prompt, the system first detects the intent of the user, then routes the request to specialized task agents with the necessary tools or automatically generates agentic workflows. In practice, most applications directly serve as AI assistants on edge devices such as phones and robots. As different language models vary in capability and cloud-based models often entail high computational costs, latency, and privacy concerns, we then explore the hybrid mode where the router dynamically selects between local and cloud models based on task complexity. Finally, we introduce the blueprint of an on-device super agent enhanced with cloud. With advances in multi-modality models and edge hardware, we envision that most computations can be handled locally, with cloud collaboration only as needed. Such architecture paves the way for super agents to be seamlessly integrated into everyday life in the near future.
FedGAT: A Privacy-Preserving Federated Approximation Algorithm for Graph Attention Networks
Dec 20, 2024



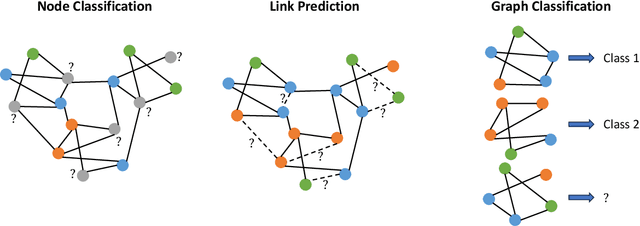
Federated training methods have gained popularity for graph learning with applications including friendship graphs of social media sites and customer-merchant interaction graphs of huge online marketplaces. However, privacy regulations often require locally generated data to be stored on local clients. The graph is then naturally partitioned across clients, with no client permitted access to information stored on another. Cross-client edges arise naturally in such cases and present an interesting challenge to federated training methods, as training a graph model at one client requires feature information of nodes on the other end of cross-client edges. Attempting to retain such edges often incurs significant communication overhead, and dropping them altogether reduces model performance. In simpler models such as Graph Convolutional Networks, this can be fixed by communicating a limited amount of feature information across clients before training, but GATs (Graph Attention Networks) require additional information that cannot be pre-communicated, as it changes from training round to round. We introduce the Federated Graph Attention Network (FedGAT) algorithm for semi-supervised node classification, which approximates the behavior of GATs with provable bounds on the approximation error. FedGAT requires only one pre-training communication round, significantly reducing the communication overhead for federated GAT training. We then analyze the error in the approximation and examine the communication overhead and computational complexity of the algorithm. Experiments show that FedGAT achieves nearly the same accuracy as a GAT model in a centralised setting, and its performance is robust to the number of clients as well as data distribution.
Alopex: A Computational Framework for Enabling On-Device Function Calls with LLMs
Nov 07, 2024



The rapid advancement of Large Language Models (LLMs) has led to their increased integration into mobile devices for personalized assistance, which enables LLMs to call external API functions to enhance their performance. However, challenges such as data scarcity, ineffective question formatting, and catastrophic forgetting hinder the development of on-device LLM agents. To tackle these issues, we propose Alopex, a framework that enables precise on-device function calls using the Fox LLM. Alopex introduces a logic-based method for generating high-quality training data and a novel ``description-question-output'' format for fine-tuning, reducing risks of function information leakage. Additionally, a data mixing strategy is used to mitigate catastrophic forgetting, combining function call data with textbook datasets to enhance performance in various tasks. Experimental results show that Alopex improves function call accuracy and significantly reduces catastrophic forgetting, providing a robust solution for integrating function call capabilities into LLMs without manual intervention.
FedGraph: A Research Library and Benchmark for Federated Graph Learning
Oct 08, 2024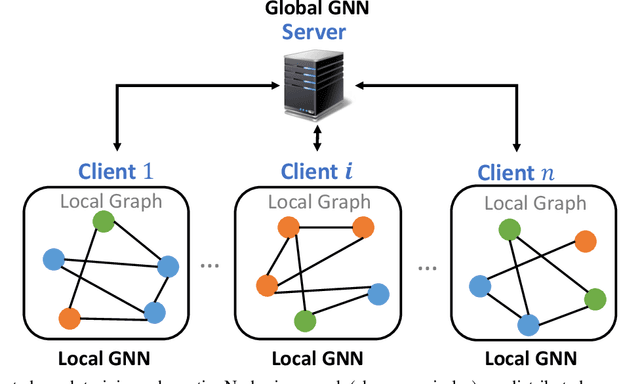
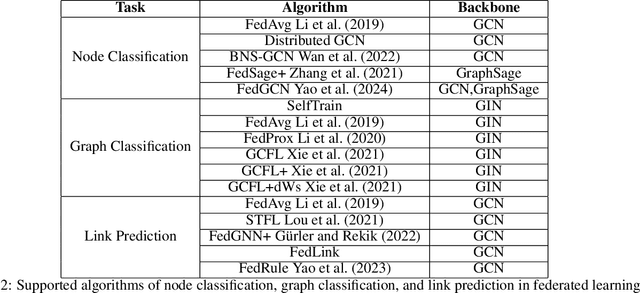
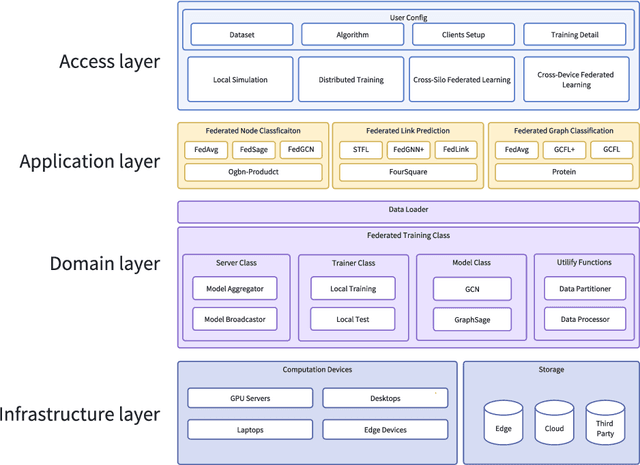
Federated graph learning is an emerging field with significant practical challenges. While many algorithms have been proposed to enhance model accuracy, their system performance, crucial for real-world deployment, is often overlooked. To address this gap, we present FedGraph, a research library designed for practical distributed deployment and benchmarking in federated graph learning. FedGraph supports a range of state-of-the-art methods and includes profiling tools for system performance evaluation, focusing on communication and computation costs during training. FedGraph can then facilitate the development of practical applications and guide the design of future algorithms.
PolyRouter: A Multi-LLM Querying System
Aug 26, 2024



With the rapid growth of Large Language Models (LLMs) across various domains, numerous new LLMs have emerged, each possessing domain-specific expertise. This proliferation has highlighted the need for quick, high-quality, and cost-effective LLM query response methods. Yet, no single LLM exists to efficiently balance this trilemma. Some models are powerful but extremely costly, while others are fast and inexpensive but qualitatively inferior. To address this challenge, we present PolyRouter, a non-monolithic LLM querying system that seamlessly integrates various LLM experts into a single query interface and dynamically routes incoming queries to the most high-performant expert based on query's requirements. Through extensive experiments, we demonstrate that when compared to standalone expert models, PolyRouter improves query efficiency by up to 40%, and leads to significant cost reductions of up to 30%, while maintaining or enhancing model performance by up to 10%.
ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency
Jul 23, 2024Large language models (LLMs) have surged in popularity and are extensively used in commercial applications, where the efficiency of model serving is crucial for the user experience. Most current research focuses on optimizing individual sub-procedures, e.g. local inference and communication, however, there is no comprehensive framework that provides a holistic system view for optimizing LLM serving in an end-to-end manner. In this work, we conduct a detailed analysis to identify major bottlenecks that impact end-to-end latency in LLM serving systems. Our analysis reveals that a comprehensive LLM serving endpoint must address a series of efficiency bottlenecks that extend beyond LLM inference. We then propose ScaleLLM, an optimized system for resource-efficient LLM serving. Our extensive experiments reveal that with 64 concurrent requests, ScaleLLM achieves a 4.3x speed up over vLLM and outperforms state-of-the-arts with 1.5x higher throughput.
TorchOpera: A Compound AI System for LLM Safety
Jun 16, 2024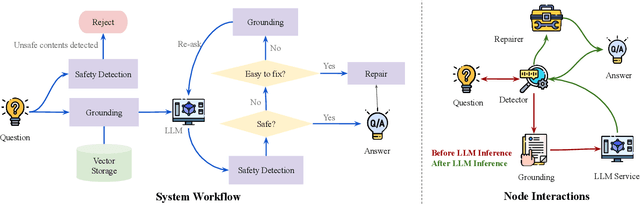



We introduce TorchOpera, a compound AI system for enhancing the safety and quality of prompts and responses for Large Language Models. TorchOpera ensures that all user prompts are safe, contextually grounded, and effectively processed, while enhancing LLM responses to be relevant and high quality. TorchOpera utilizes the vector database for contextual grounding, rule-based wrappers for flexible modifications, and specialized mechanisms for detecting and adjusting unsafe or incorrect content. We also provide a view of the compound AI system to reduce the computational cost. Extensive experiments show that TorchOpera ensures the safety, reliability, and applicability of LLMs in real-world settings while maintaining the efficiency of LLM responses.