 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Safety Gap: A Guardrail Pipeline for Trustworthy LLM Inferences
Feb 12, 2025We present Wildflare GuardRail, a guardrail pipeline designed to enhance the safety and reliability of Large Language Model (LLM) inferences by systematically addressing risks across the entire processing workflow. Wildflare GuardRail integrates several core functional modules, including Safety Detector that identifies unsafe inputs and detects hallucinations in model outputs while generating root-cause explanations, Grounding that contextualizes user queries with information retrieved from vector databases, Customizer that adjusts outputs in real time using lightweight, rule-based wrappers, and Repairer that corrects erroneous LLM outputs using hallucination explanations provided by Safety Detector. Results show that our unsafe content detection model in Safety Detector achieves comparable performance with OpenAI API, though trained on a small dataset constructed with several public datasets. Meanwhile, the lightweight wrappers can address malicious URLs in model outputs in 1.06s per query with 100% accuracy without costly model calls. Moreover, the hallucination fixing model demonstrates effectiveness in reducing hallucinations with an accuracy of 80.7%.
Alopex: A Computational Framework for Enabling On-Device Function Calls with LLMs
Nov 07, 2024



The rapid advancement of Large Language Models (LLMs) has led to their increased integration into mobile devices for personalized assistance, which enables LLMs to call external API functions to enhance their performance. However, challenges such as data scarcity, ineffective question formatting, and catastrophic forgetting hinder the development of on-device LLM agents. To tackle these issues, we propose Alopex, a framework that enables precise on-device function calls using the Fox LLM. Alopex introduces a logic-based method for generating high-quality training data and a novel ``description-question-output'' format for fine-tuning, reducing risks of function information leakage. Additionally, a data mixing strategy is used to mitigate catastrophic forgetting, combining function call data with textbook datasets to enhance performance in various tasks. Experimental results show that Alopex improves function call accuracy and significantly reduces catastrophic forgetting, providing a robust solution for integrating function call capabilities into LLMs without manual intervention.
ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency
Jul 23, 2024Large language models (LLMs) have surged in popularity and are extensively used in commercial applications, where the efficiency of model serving is crucial for the user experience. Most current research focuses on optimizing individual sub-procedures, e.g. local inference and communication, however, there is no comprehensive framework that provides a holistic system view for optimizing LLM serving in an end-to-end manner. In this work, we conduct a detailed analysis to identify major bottlenecks that impact end-to-end latency in LLM serving systems. Our analysis reveals that a comprehensive LLM serving endpoint must address a series of efficiency bottlenecks that extend beyond LLM inference. We then propose ScaleLLM, an optimized system for resource-efficient LLM serving. Our extensive experiments reveal that with 64 concurrent requests, ScaleLLM achieves a 4.3x speed up over vLLM and outperforms state-of-the-arts with 1.5x higher throughput.
TorchOpera: A Compound AI System for LLM Safety
Jun 16, 2024We introduce TorchOpera, a compound AI system for enhancing the safety and quality of prompts and responses for Large Language Models. TorchOpera ensures that all user prompts are safe, contextually grounded, and effectively processed, while enhancing LLM responses to be relevant and high quality. TorchOpera utilizes the vector database for contextual grounding, rule-based wrappers for flexible modifications, and specialized mechanisms for detecting and adjusting unsafe or incorrect content. We also provide a view of the compound AI system to reduce the computational cost. Extensive experiments show that TorchOpera ensures the safety, reliability, and applicability of LLMs in real-world settings while maintaining the efficiency of LLM responses.
LLM Multi-Agent Systems: Challenges and Open Problems
Feb 05, 2024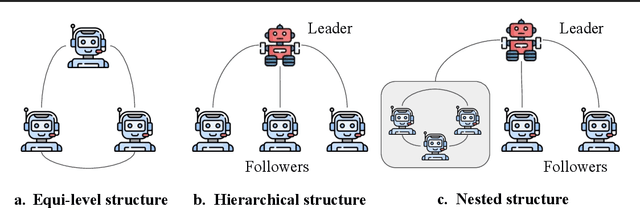
This paper explores existing works of multi-agent systems and identifies challenges that remain inadequately addressed. By leveraging the diverse capabilities and roles of individual agents within a multi-agent system, these systems can tackle complex tasks through collaboration. We discuss optimizing task allocation, fostering robust reasoning through iterative debates, managing complex and layered context information, and enhancing memory management to support the intricate interactions within multi-agent systems. We also explore the potential application of multi-agent systems in blockchain systems to shed light on their future development and application in real-world distributed systems.
Kick Bad Guys Out! Zero-Knowledge-Proof-Based Anomaly Detection in Federated Learning
Oct 06, 2023

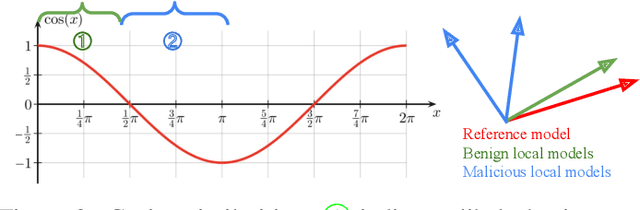
Federated learning (FL) systems are vulnerable to malicious clients that submit poisoned local models to achieve their adversarial goals, such as preventing the convergence of the global model or inducing the global model to misclassify some data. Many existing defense mechanisms are impractical in real-world FL systems, as they require prior knowledge of the number of malicious clients or rely on re-weighting or modifying submissions. This is because adversaries typically do not announce their intentions before attacking, and re-weighting might change aggregation results even in the absence of attacks. To address these challenges in real FL systems, this paper introduces a cutting-edge anomaly detection approach with the following features: i) Detecting the occurrence of attacks and performing defense operations only when attacks happen; ii) Upon the occurrence of an attack, further detecting the malicious client models and eliminating them without harming the benign ones; iii) Ensuring honest execution of defense mechanisms at the server by leveraging a zero-knowledge proof mechanism. We validate the superior performance of the proposed approach with extensive experiments.
FedMLSecurity: A Benchmark for Attacks and Defenses in Federated Learning and LLMs
Jun 08, 2023

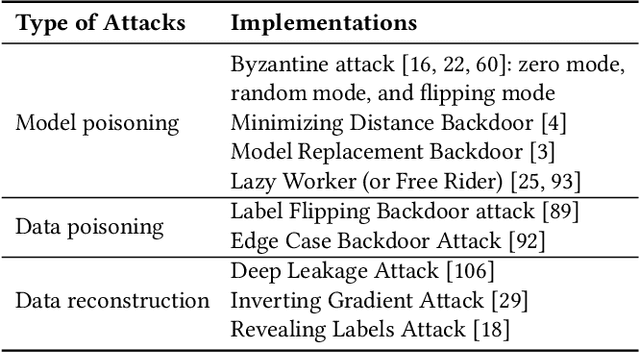
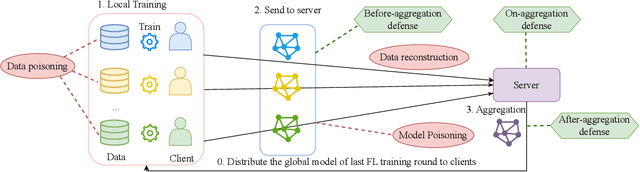
This paper introduces FedMLSecurity, a benchmark that simulates adversarial attacks and corresponding defense mechanisms in Federated Learning (FL). As an integral module of the open-sourced library FedML that facilitates FL algorithm development and performance comparison, FedMLSecurity enhances the security assessment capacity of FedML. FedMLSecurity comprises two principal components: FedMLAttacker, which simulates attacks injected into FL training, and FedMLDefender, which emulates defensive strategies designed to mitigate the impacts of the attacks. FedMLSecurity is open-sourced 1 and is customizable to a wide range of machine learning models (e.g., Logistic Regression, ResNet, GAN, etc.) and federated optimizers (e.g., FedAVG, FedOPT, FedNOVA, etc.). Experimental evaluations in this paper also demonstrate the ease of application of FedMLSecurity to Large Language Models (LLMs), further reinforcing its versatility and practical utility in various scenarios.
FedML-HE: An Efficient Homomorphic-Encryption-Based Privacy-Preserving Federated Learning System
Mar 20, 2023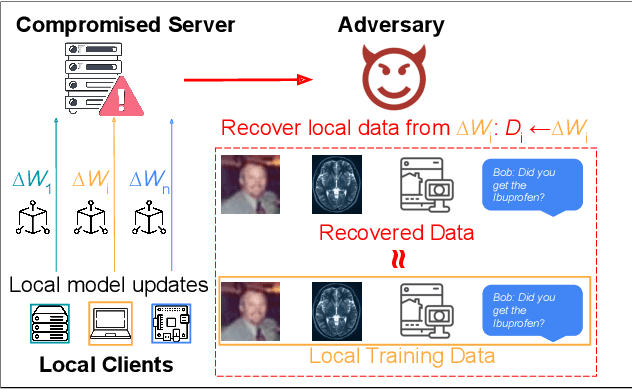


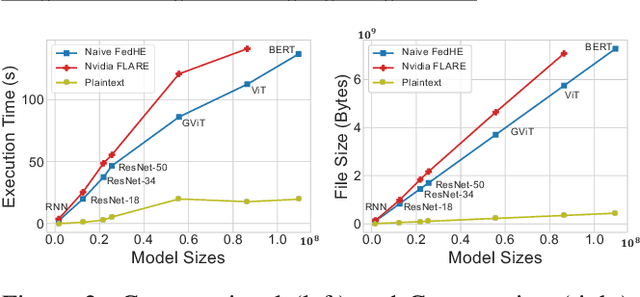
Federated Learning (FL) enables machine learning model training on distributed edge devices by aggregating local model updates rather than local data. However, privacy concerns arise as the FL server's access to local model updates can potentially reveal sensitive personal information by performing attacks like gradient inversion recovery. To address these concerns, privacy-preserving methods, such as Homomorphic Encryption (HE)-based approaches, have been proposed. Despite HE's post-quantum security advantages, its applications suffer from impractical overheads. In this paper, we present FedML-HE, the first practical system for efficient HE-based secure federated aggregation that provides a user/device-friendly deployment platform. FL-HE utilizes a novel universal overhead optimization scheme, significantly reducing both computation and communication overheads during deployment while providing customizable privacy guarantees. Our optimized system demonstrates considerable overhead reduction, particularly for large models (e.g., ~10x reduction for HE-federated training of ResNet-50 and ~40x reduction for BERT), demonstrating the potential for scalable HE-based FL deployment.
Proof-of-Contribution-Based Design for Collaborative Machine Learning on Blockchain
Feb 27, 2023
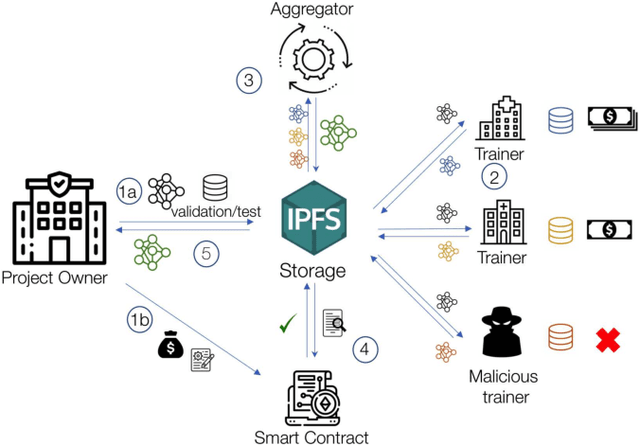
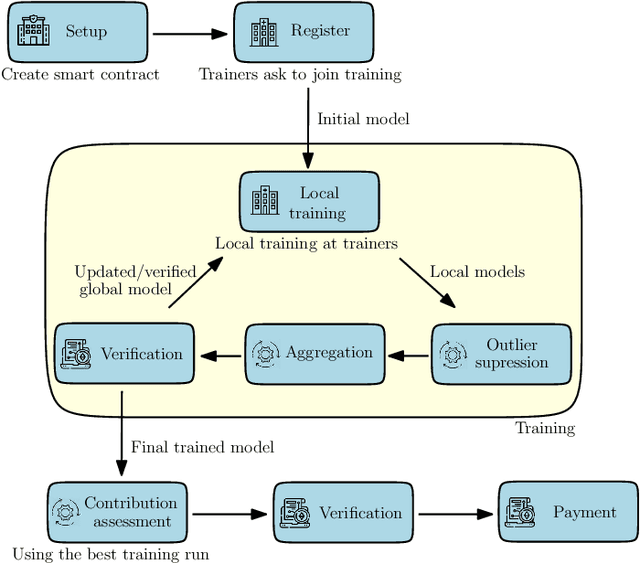
We consider a project (model) owner that would like to train a model by utilizing the local private data and compute power of interested data owners, i.e., trainers. Our goal is to design a data marketplace for such decentralized collaborative/federated learning applications that simultaneously provides i) proof-of-contribution based reward allocation so that the trainers are compensated based on their contributions to the trained model; ii) privacy-preserving decentralized model training by avoiding any data movement from data owners; iii) robustness against malicious parties (e.g., trainers aiming to poison the model); iv) verifiability in the sense that the integrity, i.e., correctness, of all computations in the data market protocol including contribution assessment and outlier detection are verifiable through zero-knowledge proofs; and v) efficient and universal design. We propose a blockchain-based marketplace design to achieve all five objectives mentioned above. In our design, we utilize a distributed storage infrastructure and an aggregator aside from the project owner and the trainers. The aggregator is a processing node that performs certain computations, including assessing trainer contributions, removing outliers, and updating hyper-parameters. We execute the proposed data market through a blockchain smart contract. The deployed smart contract ensures that the project owner cannot evade payment, and honest trainers are rewarded based on their contributions at the end of training. Finally, we implement the building blocks of the proposed data market and demonstrate their applicability in practical scenarios through extensive experiments.
Federated Analytics: A survey
Feb 02, 2023

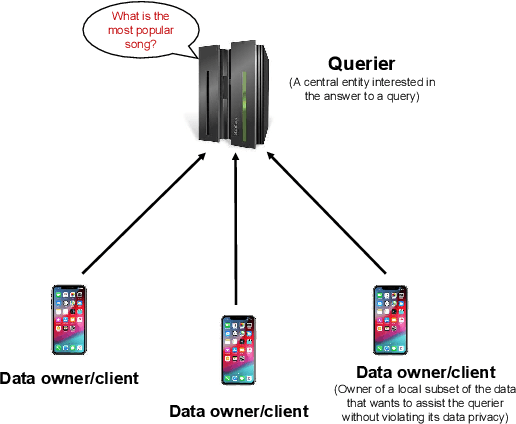

Federated analytics (FA) is a privacy-preserving framework for computing data analytics over multiple remote parties (e.g., mobile devices) or silo-ed institutional entities (e.g., hospitals, banks) without sharing the data among parties. Motivated by the practical use cases of federated analytics, we follow a systematic discussion on federated analytics in this article. In particular, we discuss the unique characteristics of federated analytics and how it differs from federated learning. We also explore a wide range of FA queries and discuss various existing solutions and potential use case applications for different FA queries.
* To appear in APSIPA Transactions on Signal and Information Processing, Volume 12, Issue 1