 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLoRA: Federated Parameter Efficient Fine-Tuning of Language Models
Aug 12, 2023



Transfer learning via fine-tuning pre-trained transformer models has gained significant success in delivering state-of-the-art results across various NLP tasks. In the absence of centralized data, Federated Learning (FL) can benefit from distributed and private data of the FL edge clients for fine-tuning. However, due to the limited communication, computation, and storage capabilities of edge devices and the huge sizes of popular transformer models, efficient fine-tuning is crucial to make federated training feasible. This work explores the opportunities and challenges associated with applying parameter efficient fine-tuning (PEFT) methods in different FL settings for language tasks. Specifically, our investigation reveals that as the data across users becomes more diverse, the gap between fully fine-tuning the model and employing PEFT methods widens. To bridge this performance gap, we propose a method called SLoRA, which overcomes the key limitations of LoRA in high heterogeneous data scenarios through a novel data-driven initialization technique. Our experimental results demonstrate that SLoRA achieves performance comparable to full fine-tuning, with significant sparse updates with approximately $\sim 1\%$ density while reducing training time by up to $90\%$.
The Resource Problem of Using Linear Layer Leakage Attack in Federated Learning
Mar 27, 2023



Secure aggregation promises a heightened level of privacy in federated learning, maintaining that a server only has access to a decrypted aggregate update. Within this setting, linear layer leakage methods are the only data reconstruction attacks able to scale and achieve a high leakage rate regardless of the number of clients or batch size. This is done through increasing the size of an injected fully-connected (FC) layer. However, this results in a resource overhead which grows larger with an increasing number of clients. We show that this resource overhead is caused by an incorrect perspective in all prior work that treats an attack on an aggregate update in the same way as an individual update with a larger batch size. Instead, by attacking the update from the perspective that aggregation is combining multiple individual updates, this allows the application of sparsity to alleviate resource overhead. We show that the use of sparsity can decrease the model size overhead by over 327$\times$ and the computation time by 3.34$\times$ compared to SOTA while maintaining equivalent total leakage rate, 77% even with $1000$ clients in aggregation.
Secure Aggregation in Federated Learning is not Private: Leaking User Data at Large Scale through Model Modification
Mar 21, 2023



Security and privacy are important concerns in machine learning. End user devices often contain a wealth of data and this information is sensitive and should not be shared with servers or enterprises. As a result, federated learning was introduced to enable machine learning over large decentralized datasets while promising privacy by eliminating the need for data sharing. However, prior work has shown that shared gradients often contain private information and attackers can gain knowledge either through malicious modification of the architecture and parameters or by using optimization to approximate user data from the shared gradients. Despite this, most attacks have so far been limited in scale of number of clients, especially failing when client gradients are aggregated together using secure model aggregation. The attacks that still function are strongly limited in the number of clients attacked, amount of training samples they leak, or number of iterations they take to be trained. In this work, we introduce MANDRAKE, an attack that overcomes previous limitations to directly leak large amounts of client data even under secure aggregation across large numbers of clients. Furthermore, we break the anonymity of aggregation as the leaked data is identifiable and directly tied back to the clients they come from. We show that by sending clients customized convolutional parameters, the weight gradients of data points between clients will remain separate through aggregation. With an aggregation across many clients, prior work could only leak less than 1% of images. With the same number of non-zero parameters, and using only a single training iteration, MANDRAKE leaks 70-80% of data samples.
Federated Analytics: A survey
Feb 02, 2023

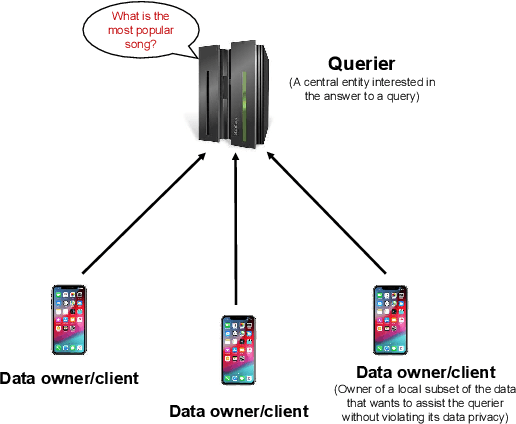

Federated analytics (FA) is a privacy-preserving framework for computing data analytics over multiple remote parties (e.g., mobile devices) or silo-ed institutional entities (e.g., hospitals, banks) without sharing the data among parties. Motivated by the practical use cases of federated analytics, we follow a systematic discussion on federated analytics in this article. In particular, we discuss the unique characteristics of federated analytics and how it differs from federated learning. We also explore a wide range of FA queries and discuss various existing solutions and potential use case applications for different FA queries.
* To appear in APSIPA Transactions on Signal and Information Processing, Volume 12, Issue 1
How Much Privacy Does Federated Learning with Secure Aggregation Guarantee?
Aug 03, 2022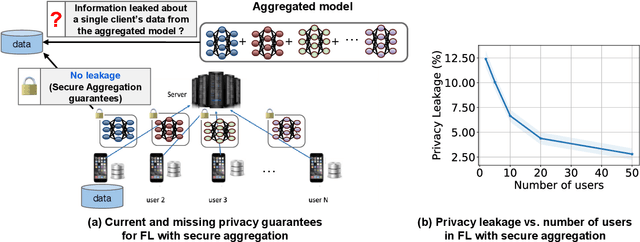
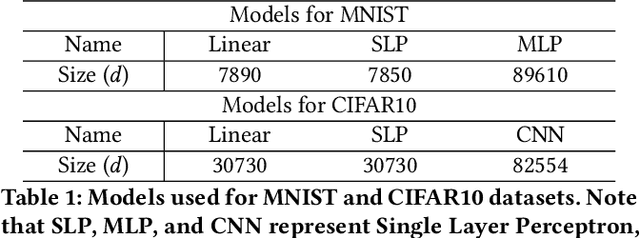
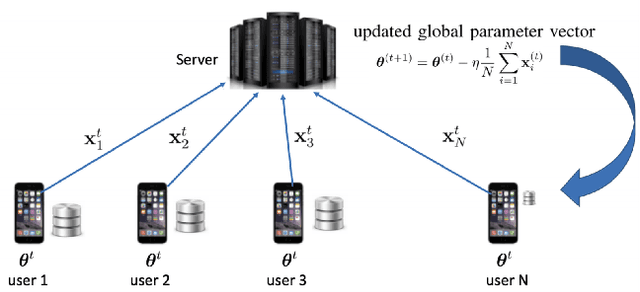
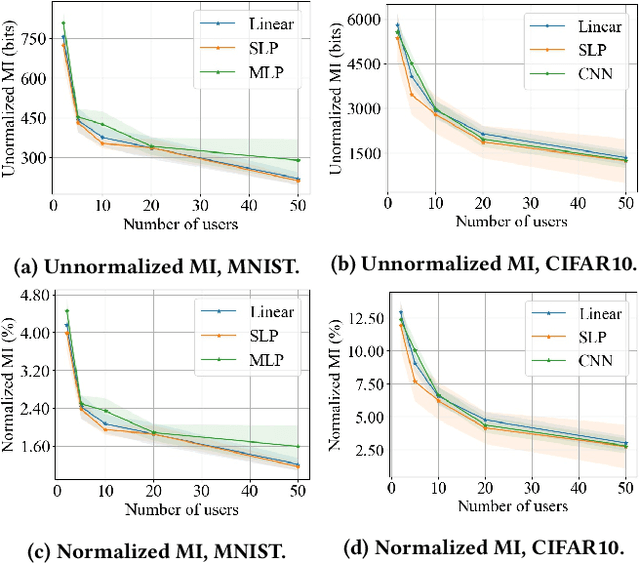
Federated learning (FL) has attracted growing interest for enabling privacy-preserving machine learning on data stored at multiple users while avoiding moving the data off-device. However, while data never leaves users' devices, privacy still cannot be guaranteed since significant computations on users' training data are shared in the form of trained local models. These local models have recently been shown to pose a substantial privacy threat through different privacy attacks such as model inversion attacks. As a remedy, Secure Aggregation (SA) has been developed as a framework to preserve privacy in FL, by guaranteeing the server can only learn the global aggregated model update but not the individual model updates. While SA ensures no additional information is leaked about the individual model update beyond the aggregated model update, there are no formal guarantees on how much privacy FL with SA can actually offer; as information about the individual dataset can still potentially leak through the aggregated model computed at the server. In this work, we perform a first analysis of the formal privacy guarantees for FL with SA. Specifically, we use Mutual Information (MI) as a quantification metric and derive upper bounds on how much information about each user's dataset can leak through the aggregated model update. When using the FedSGD aggregation algorithm, our theoretical bounds show that the amount of privacy leakage reduces linearly with the number of users participating in FL with SA. To validate our theoretical bounds, we use an MI Neural Estimator to empirically evaluate the privacy leakage under different FL setups on both the MNIST and CIFAR10 datasets. Our experiments verify our theoretical bounds for FedSGD, which show a reduction in privacy leakage as the number of users and local batch size grow, and an increase in privacy leakage with the number of training rounds.