 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRINT: Semi-supervised Prototypical Representation for Few-Shot Class-Incremental Tabular Learning
Mar 04, 2026Real-world systems must continuously adapt to novel concepts from limited data without forgetting previously acquired knowledge. While Few-Shot Class-Incremental Learning (FSCIL) is established in computer vision, its application to tabular domains remains largely unexplored. Unlike images, tabular streams (e.g., logs, sensors) offer abundant unlabeled data, a scarcity of expert annotations and negligible storage costs, features ignored by existing vision-based methods that rely on restrictive buffers. We introduce SPRINT, the first FSCIL framework tailored for tabular distributions. SPRINT introduces a mixed episodic training strategy that leverages confidence-based pseudo-labeling to enrich novel class representations and exploits low storage costs to retain base class history. Extensive evaluation across six diverse benchmarks spanning cybersecurity, healthcare, and ecological domains, demonstrates SPRINT's cross-domain robustness. It achieves a state-of-the-art average accuracy of 77.37% (5-shot), outperforming the strongest incremental baseline by 4.45%.
SES: Bridging the Gap Between Explainability and Prediction of Graph Neural Networks
Jul 16, 2024



Despite the Graph Neural Networks' (GNNs) proficiency in analyzing graph data, achieving high-accuracy and interpretable predictions remains challenging. Existing GNN interpreters typically provide post-hoc explanations disjointed from GNNs' predictions, resulting in misrepresentations. Self-explainable GNNs offer built-in explanations during the training process. However, they cannot exploit the explanatory outcomes to augment prediction performance, and they fail to provide high-quality explanations of node features and require additional processes to generate explainable subgraphs, which is costly. To address the aforementioned limitations, we propose a self-explained and self-supervised graph neural network (SES) to bridge the gap between explainability and prediction. SES comprises two processes: explainable training and enhanced predictive learning. During explainable training, SES employs a global mask generator co-trained with a graph encoder and directly produces crucial structure and feature masks, reducing time consumption and providing node feature and subgraph explanations. In the enhanced predictive learning phase, mask-based positive-negative pairs are constructed utilizing the explanations to compute a triplet loss and enhance the node representations by contrastive learning.
Graph Structure Prompt Learning: A Novel Methodology to Improve Performance of Graph Neural Networks
Jul 16, 2024



Graph neural networks (GNNs) are widely applied in graph data modeling. However, existing GNNs are often trained in a task-driven manner that fails to fully capture the intrinsic nature of the graph structure, resulting in sub-optimal node and graph representations. To address this limitation, we propose a novel Graph structure Prompt Learning method (GPL) to enhance the training of GNNs, which is inspired by prompt mechanisms in natural language processing. GPL employs task-independent graph structure losses to encourage GNNs to learn intrinsic graph characteristics while simultaneously solving downstream tasks, producing higher-quality node and graph representations. In extensive experiments on eleven real-world datasets, after being trained by GPL, GNNs significantly outperform their original performance on node classification, graph classification, and edge prediction tasks (up to 10.28%, 16.5%, and 24.15%, respectively). By allowing GNNs to capture the inherent structural prompts of graphs in GPL, they can alleviate the issue of over-smooth and achieve new state-of-the-art performances, which introduces a novel and effective direction for GNN research with potential applications in various domains.
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding
Sep 15, 2023We present a novel inference scheme, self-speculative decoding, for accelerating Large Language Models (LLMs) without the need for an auxiliary model. This approach is characterized by a two-stage process: drafting and verification. The drafting stage generates draft tokens at a slightly lower quality but more quickly, which is achieved by selectively skipping certain intermediate layers during drafting Subsequently, the verification stage employs the original LLM to validate those draft output tokens in one forward pass. This process ensures the final output remains identical to that produced by the unaltered LLM, thereby maintaining output quality. The proposed method requires no additional neural network training and no extra memory footprint, making it a plug-and-play and cost-effective solution for inference acceleration. Benchmarks with LLaMA-2 and its fine-tuned models demonstrated a speedup up to 1.73$\times$.
Federated Analytics: A survey
Feb 02, 2023

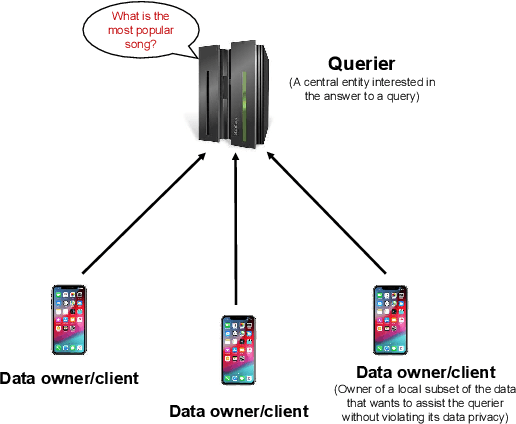

Federated analytics (FA) is a privacy-preserving framework for computing data analytics over multiple remote parties (e.g., mobile devices) or silo-ed institutional entities (e.g., hospitals, banks) without sharing the data among parties. Motivated by the practical use cases of federated analytics, we follow a systematic discussion on federated analytics in this article. In particular, we discuss the unique characteristics of federated analytics and how it differs from federated learning. We also explore a wide range of FA queries and discuss various existing solutions and potential use case applications for different FA queries.
* To appear in APSIPA Transactions on Signal and Information Processing, Volume 12, Issue 1
Prism: Private Verifiable Set Computation over Multi-Owner Outsourced Databases
Apr 07, 2021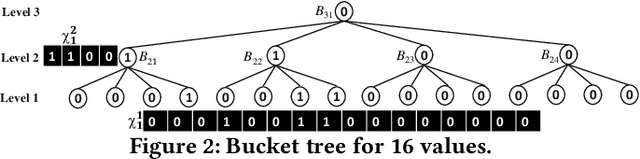

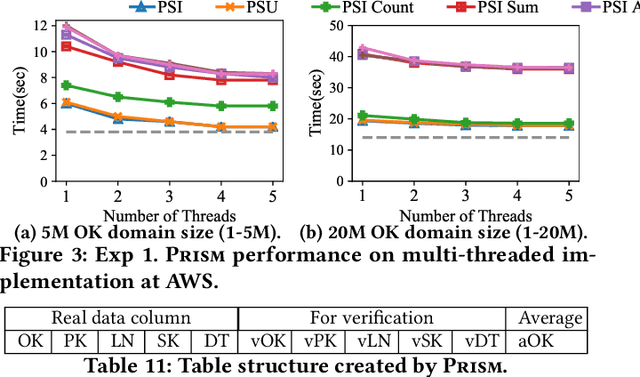

This paper proposes Prism, a secret sharing based approach to compute private set operations (i.e., intersection and union), as well as aggregates over outsourced databases belonging to multiple owners. Prism enables data owners to pre-load the data onto non-colluding servers and exploits the additive and multiplicative properties of secret-shares to compute the above-listed operations in (at most) two rounds of communication between the servers (storing the secret-shares) and the querier, resulting in a very efficient implementation. Also, Prism does not require communication among the servers and supports result verification techniques for each operation to detect malicious adversaries. Experimental results show that Prism scales both in terms of the number of data owners and database sizes, to which prior approaches do not scale.
Concealer: SGX-based Secure, Volume Hiding, and Verifiable Processing of Spatial Time-Series Datasets
Feb 10, 2021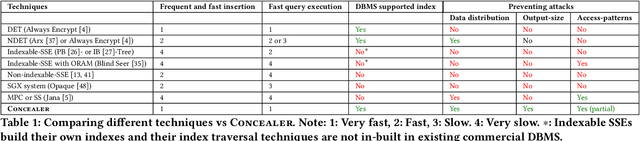
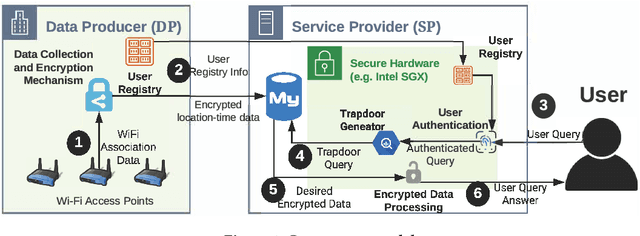


This paper proposes a system, entitled Concealer that allows sharing time-varying spatial data (e.g., as produced by sensors) in encrypted form to an untrusted third-party service provider to provide location-based applications (involving aggregation queries over selected regions over time windows) to users. Concealer exploits carefully selected encryption techniques to use indexes supported by database systems and combines ways to add fake tuples in order to realize an efficient system that protects against leakage based on output-size. Thus, the design of Concealer overcomes two limitations of existing symmetric searchable encryption (SSE) techniques: (i) it avoids the need of specialized data structures that limit usability/practicality of SSE in large scale deployments, and (ii) it avoids information leakages based on the output-size, which may leak data distributions. Experimental results validate the efficiency of the proposed algorithms over a spatial time-series dataset (collected from a smart space) and TPC-H datasets, each of 136 Million rows, the size of which prior approaches have not scaled to.
Canopy: A Verifiable Privacy-Preserving Token Ring based Communication Protocol for Smart Homes
Apr 08, 2020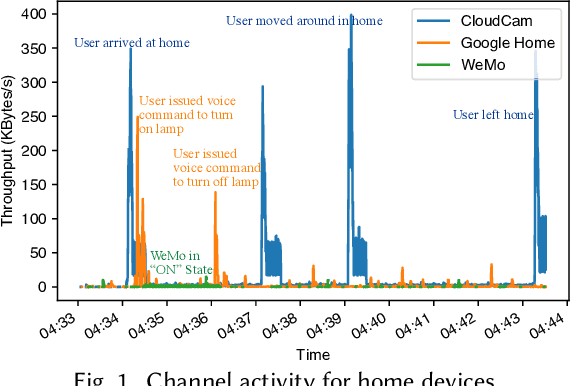

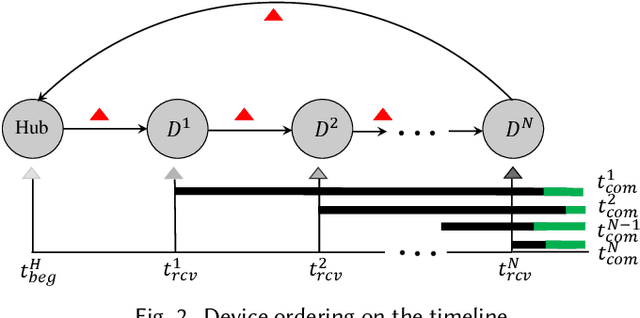
This paper focuses on the new privacy challenges that arise in smart homes. Specifically, the paper focuses on inferring the user's activities -- which may, in turn, lead to the user's privacy -- via inferences through device activities and network traffic analysis. We develop techniques that are based on a cryptographically secure token circulation in a ring network consisting of smart home devices to prevent inferences from device activities, via device workflow, i.e., inferences from a coordinated sequence of devices' actuation. The solution hides the device activity and corresponding channel activities, and thus, preserve the individual's activities. We also extend our solution to deal with a large number of devices and devices that produce large-sized data by implementing parallel rings. Our experiments also evaluate the performance in terms of communication overheads of the proposed approach and the obtained privacy.
Network2Vec Learning Node Representation Based on Space Mapping in Networks
Oct 23, 2019
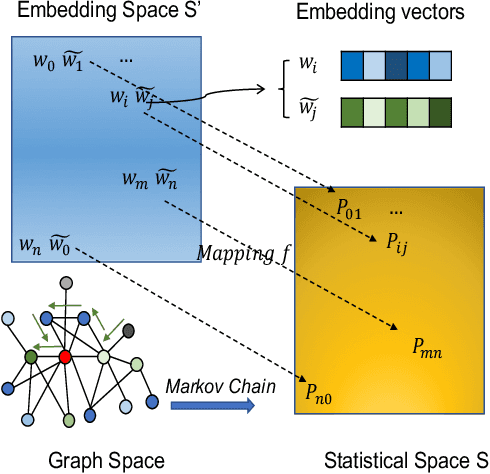
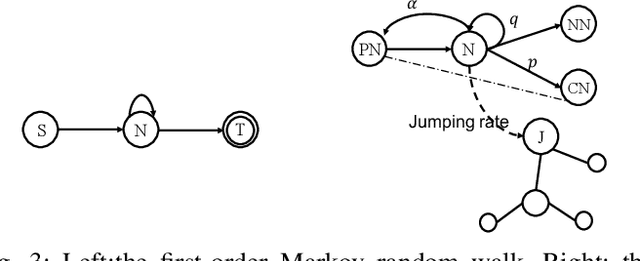
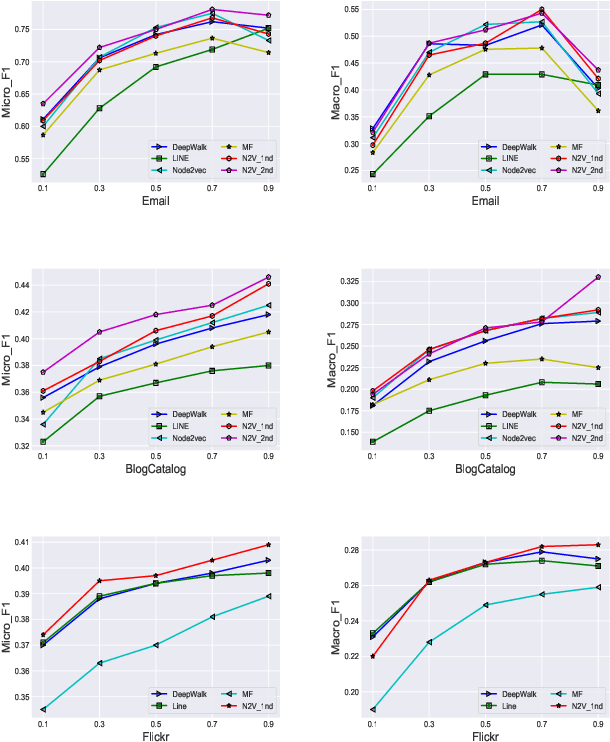
Complex networks represented as node adjacency matrices constrains the application of machine learning and parallel algorithms. To address this limitation, network embedding (i.e., graph representation) has been intensively studied to learn a fixed-length vector for each node in an embedding space, where the node properties in the original graph are preserved. Existing methods mainly focus on learning embedding vectors to preserve nodes proximity, i.e., nodes next to each other in the graph space should also be closed in the embedding space, but do not enforce algebraic statistical properties to be shared between the embedding space and graph space. In this work, we propose a lightweight model, entitled Network2Vec, to learn network embedding on the base of semantic distance mapping between the graph space and embedding space. The model builds a bridge between the two spaces leveraging the property of group homomorphism. Experiments on different learning tasks, including node classification, link prediction, and community visualization, demonstrate the effectiveness and efficiency of the new embedding method, which improves the state-of-the-art model by 19% in node classification and 7% in link prediction tasks at most. In addition, our method is significantly faster, consuming only a fraction of the time used by some famous methods.
Semi-Supervised Few-Shot Learning for Dual Question-Answer Extraction
Apr 08, 2019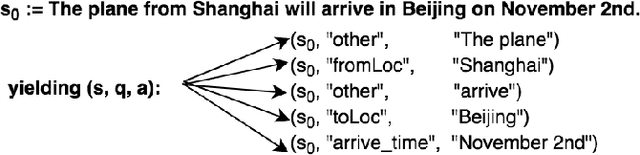
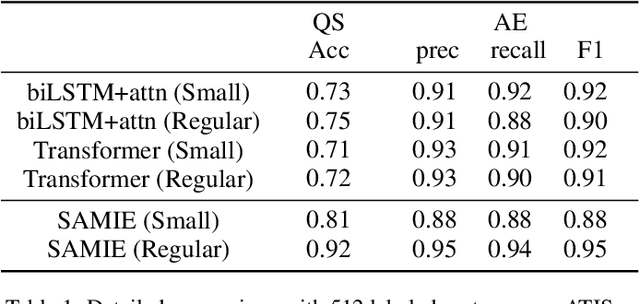

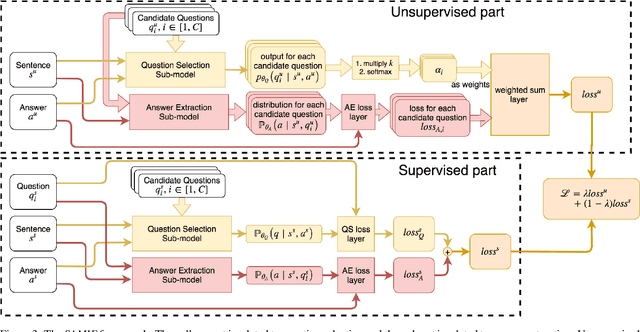
This paper addresses the problem of key phrase extraction from sentences. Existing state-of-the-art supervised methods require large amounts of annotated data to achieve good performance and generalization. Collecting labeled data is, however, often expensive. In this paper, we redefine the problem as question-answer extraction, and present SAMIE: Self-Asking Model for Information Ixtraction, a semi-supervised model which dually learns to ask and to answer questions by itself. Briefly, given a sentence $s$ and an answer $a$, the model needs to choose the most appropriate question $\hat q$; meanwhile, for the given sentence $s$ and same question $\hat q$ selected in the previous step, the model will predict an answer $\hat a$. The model can support few-shot learning with very limited supervision. It can also be used to perform clustering analysis when no supervision is provided. Experimental results show that the proposed method outperforms typical supervised methods especially when given little labeled data.