 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Split Learning for LLM Fine-Tuning: Models, Systems, and Privacy Optimizations
Apr 27, 2026Fine-tuning unlocks large language models (LLMs) for specialized applications, but its high computational cost often puts it out of reach for resource-constrained organizations. While cloud platforms could provide the needed resources, data privacy concerns make sharing sensitive information with third parties risky. A promising solution is split learning for LLM fine-tuning, which divides the model between clients and a server, allowing collaborative and secure training through exchanged intermediate data, thus enabling resource-constrained participants to adapt LLMs safely. % In light of this, a growing body of literature has emerged to advance this paradigm, introducing varied model methods, system optimizations, and privacy defense-attack techniques for split learning. To bring clarity and direction to the field, a comprehensive survey is needed to classify, compare, and critique these diverse approaches. This paper fills the gap by presenting the first extensive survey dedicated to split learning for LLM fine-tuning. We propose a unified, fine-grained training pipeline to pinpoint key operational components and conduct a systematic review of state-of-the-art work across three core dimensions: model-level optimization, system-level efficiency, and privacy preservation. Through this structured taxonomy, we establish a foundation for advancing scalable, robust, and secure collaborative LLM adaptation.
Enhancing Reinforcement Learning for Radiology Report Generation with Evidence-aware Rewards and Self-correcting Preference Learning
Apr 15, 2026Recent reinforcement learning (RL) approaches have advanced radiology report generation (RRG), yet two core limitations persist: (1) report-level rewards offer limited evidence-grounded guidance for clinical faithfulness; and (2) current methods lack an explicit self-improving mechanism to align with clinical preference. We introduce clinically aligned Evidence-aware Self-Correcting Reinforcement Learning (ESC-RL), comprising two key components. First, a Group-wise Evidence-aware Alignment Reward (GEAR) delivers group-wise, evidence-aware feedback. GEAR reinforces consistent grounding for true positives, recovers missed findings for false negatives, and suppresses unsupported content for false positives. Second, a Self-correcting Preference Learning (SPL) strategy automatically constructs a reliable, disease-aware preference dataset from multiple noisy observations and leverages an LLM to synthesize refined reports without human supervision. ESC-RL promotes clinically faithful, disease-aligned reward and supports continual self-improvement during training. Extensive experiments on two public chest X-ray datasets demonstrate consistent gains and state-of-the-art performance.
Data-Free Privacy-Preserving for LLMs via Model Inversion and Selective Unlearning
Jan 22, 2026Large language models (LLMs) exhibit powerful capabilities but risk memorizing sensitive personally identifiable information (PII) from their training data, posing significant privacy concerns. While machine unlearning techniques aim to remove such data, they predominantly depend on access to the training data. This requirement is often impractical, as training data in real-world deployments is commonly proprietary or inaccessible. To address this limitation, we propose Data-Free Selective Unlearning (DFSU), a novel privacy-preserving framework that removes sensitive PII from an LLM without requiring its training data. Our approach first synthesizes pseudo-PII through language model inversion, then constructs token-level privacy masks for these synthetic samples, and finally performs token-level selective unlearning via a contrastive mask loss within a low-rank adaptation (LoRA) subspace. Extensive experiments on the AI4Privacy PII-Masking dataset using Pythia models demonstrate that our method effectively removes target PII while maintaining model utility.
Learner-Tailored Program Repair: A Solution Generator with Iterative Edit-Driven Retrieval Enhancement
Jan 13, 2026With the development of large language models (LLMs) in the field of programming, intelligent programming coaching systems have gained widespread attention. However, most research focuses on repairing the buggy code of programming learners without providing the underlying causes of the bugs. To address this gap, we introduce a novel task, namely \textbf{LPR} (\textbf{L}earner-Tailored \textbf{P}rogram \textbf{R}epair). We then propose a novel and effective framework, \textbf{\textsc{\MethodName{}}} (\textbf{L}earner-Tailored \textbf{S}olution \textbf{G}enerator), to enhance program repair while offering the bug descriptions for the buggy code. In the first stage, we utilize a repair solution retrieval framework to construct a solution retrieval database and then employ an edit-driven code retrieval approach to retrieve valuable solutions, guiding LLMs in identifying and fixing the bugs in buggy code. In the second stage, we propose a solution-guided program repair method, which fixes the code and provides explanations under the guidance of retrieval solutions. Moreover, we propose an Iterative Retrieval Enhancement method that utilizes evaluation results of the generated code to iteratively optimize the retrieval direction and explore more suitable repair strategies, improving performance in practical programming coaching scenarios. The experimental results show that our approach outperforms a set of baselines by a large margin, validating the effectiveness of our framework for the newly proposed LPR task.
CTkvr: KV Cache Retrieval for Long-Context LLMs via Centroid then Token Indexing
Dec 17, 2025Large language models (LLMs) are increasingly applied in long-context scenarios such as multi-turn conversations. However, long contexts pose significant challenges for inference efficiency, including high memory overhead from Key-Value (KV) cache and increased latency due to excessive memory accesses. Recent methods for dynamic KV selection struggle with trade-offs: block-level indexing degrades accuracy by retrieving irrelevant KV entries, while token-level indexing incurs high latency from inefficient retrieval mechanisms. In this paper, we propose CTKVR, a novel centroid-then-token KV retrieval scheme that addresses these limitations. CTKVR leverages a key observation: query vectors adjacent in position exhibit high similarity after Rotary Position Embedding (RoPE) and share most of their top-k KV cache entries. Based on this insight, CTKVR employs a two-stage retrieval strategy: lightweight centroids are precomputed during prefilling for centroid-grained indexing, followed by token-level refinement for precise KV retrieval. This approach balances retrieval efficiency and accuracy. To further enhance performance, we implement an optimized system for indexing construction and search using CPU-GPU co-execution. Experimentally, CTKVR achieves superior performance across multiple benchmarks with less than 1% accuracy degradation. Meanwhile, CTKVR delivers 3 times and 4 times throughput speedups on Llama-3-8B and Yi-9B at 96K context length across diverse GPU hardware.
Less is More: Adaptive Program Repair with Bug Localization and Preference Learning
Mar 09, 2025Automated Program Repair (APR) is a task to automatically generate patches for the buggy code. However, most research focuses on generating correct patches while ignoring the consistency between the fixed code and the original buggy code. How to conduct adaptive bug fixing and generate patches with minimal modifications have seldom been investigated. To bridge this gap, we first introduce a novel task, namely AdaPR (Adaptive Program Repair). We then propose a two-stage approach AdaPatcher (Adaptive Patch Generator) to enhance program repair while maintaining the consistency. In the first stage, we utilize a Bug Locator with self-debug learning to accurately pinpoint bug locations. In the second stage, we train a Program Modifier to ensure consistency between the post-modified fixed code and the pre-modified buggy code. The Program Modifier is enhanced with a location-aware repair learning strategy to generate patches based on identified buggy lines, a hybrid training strategy for selective reference and an adaptive preference learning to prioritize fewer changes. The experimental results show that our approach outperforms a set of baselines by a large margin, validating the effectiveness of our two-stage framework for the newly proposed AdaPR task.
Mining Platoon Patterns from Traffic Videos
Dec 28, 2024Discovering co-movement patterns from urban-scale video data sources has emerged as an attractive topic. This task aims to identify groups of objects that travel together along a common route, which offers effective support for government agencies in enhancing smart city management. However, the previous work has made a strong assumption on the accuracy of recovered trajectories from videos and their co-movement pattern definition requires the group of objects to appear across consecutive cameras along the common route. In practice, this often leads to missing patterns if a vehicle is not correctly identified from a certain camera due to object occlusion or vehicle mis-matching. To address this challenge, we propose a relaxed definition of co-movement patterns from video data, which removes the consecutiveness requirement in the common route and accommodates a certain number of missing captured cameras for objects within the group. Moreover, a novel enumeration framework called MaxGrowth is developed to efficiently retrieve the relaxed patterns. Unlike previous filter-and-refine frameworks comprising both candidate enumeration and subsequent candidate verification procedures, MaxGrowth incurs no verification cost for the candidate patterns. It treats the co-movement pattern as an equivalent sequence of clusters, enumerating candidates with increasing sequence length while avoiding the generation of any false positives. Additionally, we also propose two effective pruning rules to efficiently filter the non-maximal patterns. Extensive experiments are conducted to validate the efficiency of MaxGrowth and the quality of its generated co-movement patterns. Our MaxGrowth runs up to two orders of magnitude faster than the baseline algorithm. It also demonstrates high accuracy in real video dataset when the trajectory recovery algorithm is not perfect.
AIGT: AI Generative Table Based on Prompt
Dec 24, 2024



Tabular data, which accounts for over 80% of enterprise data assets, is vital in various fields. With growing concerns about privacy protection and data-sharing restrictions, generating high-quality synthetic tabular data has become essential. Recent advancements show that large language models (LLMs) can effectively gener-ate realistic tabular data by leveraging semantic information and overcoming the challenges of high-dimensional data that arise from one-hot encoding. However, current methods do not fully utilize the rich information available in tables. To address this, we introduce AI Generative Table (AIGT) based on prompt enhancement, a novel approach that utilizes meta data information, such as table descriptions and schemas, as prompts to generate ultra-high quality synthetic data. To overcome the token limit constraints of LLMs, we propose long-token partitioning algorithms that enable AIGT to model tables of any scale. AIGT achieves state-of-the-art performance on 14 out of 20 public datasets and two real industry datasets within the Alipay risk control system.
Revisiting CNNs for Trajectory Similarity Learning
May 30, 2024



Similarity search is a fundamental but expensive operator in querying trajectory data, due to its quadratic complexity of distance computation. To mitigate the computational burden for long trajectories, neural networks have been widely employed for similarity learning and each trajectory is encoded as a high-dimensional vector for similarity search with linear complexity. Given the sequential nature of trajectory data, previous efforts have been primarily devoted to the utilization of RNNs or Transformers. In this paper, we argue that the common practice of treating trajectory as sequential data results in excessive attention to capturing long-term global dependency between two sequences. Instead, our investigation reveals the pivotal role of local similarity, prompting a revisit of simple CNNs for trajectory similarity learning. We introduce ConvTraj, incorporating both 1D and 2D convolutions to capture sequential and geo-distribution features of trajectories, respectively. In addition, we conduct a series of theoretical analyses to justify the effectiveness of ConvTraj. Experimental results on three real-world large-scale datasets demonstrate that ConvTraj achieves state-of-the-art accuracy in trajectory similarity search. Owing to the simple network structure of ConvTraj, the training and inference speed on the Porto dataset with 1.6 million trajectories are increased by at least $240$x and $2.16$x, respectively. The source code and dataset can be found at \textit{\url{https://github.com/Proudc/ConvTraj}}.
A Comprehensive Survey of Dynamic Graph Neural Networks: Models, Frameworks, Benchmarks, Experiments and Challenges
May 01, 2024


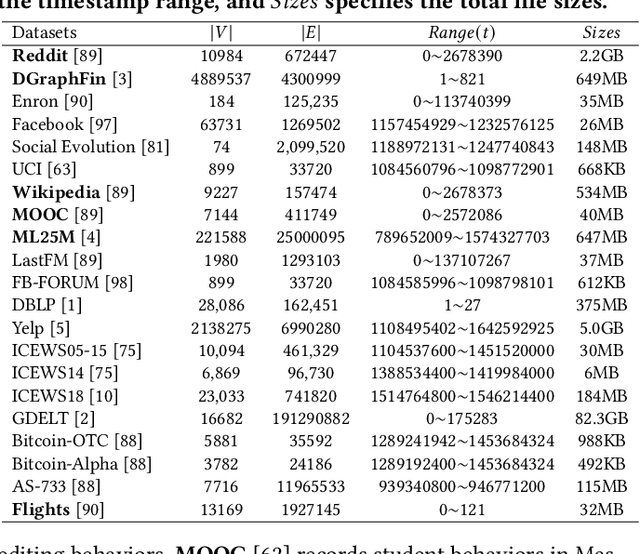
Dynamic Graph Neural Networks (GNNs) combine temporal information with GNNs to capture structural, temporal, and contextual relationships in dynamic graphs simultaneously, leading to enhanced performance in various applications. As the demand for dynamic GNNs continues to grow, numerous models and frameworks have emerged to cater to different application needs. There is a pressing need for a comprehensive survey that evaluates the performance, strengths, and limitations of various approaches in this domain. This paper aims to fill this gap by offering a thorough comparative analysis and experimental evaluation of dynamic GNNs. It covers 81 dynamic GNN models with a novel taxonomy, 12 dynamic GNN training frameworks, and commonly used benchmarks. We also conduct experimental results from testing representative nine dynamic GNN models and three frameworks on six standard graph datasets. Evaluation metrics focus on convergence accuracy, training efficiency, and GPU memory usage, enabling a thorough comparison of performance across various models and frameworks. From the analysis and evaluation results, we identify key challenges and offer principles for future research to enhance the design of models and frameworks in the dynamic GNNs field.