 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Platoon Patterns from Traffic Videos
Dec 28, 2024Discovering co-movement patterns from urban-scale video data sources has emerged as an attractive topic. This task aims to identify groups of objects that travel together along a common route, which offers effective support for government agencies in enhancing smart city management. However, the previous work has made a strong assumption on the accuracy of recovered trajectories from videos and their co-movement pattern definition requires the group of objects to appear across consecutive cameras along the common route. In practice, this often leads to missing patterns if a vehicle is not correctly identified from a certain camera due to object occlusion or vehicle mis-matching. To address this challenge, we propose a relaxed definition of co-movement patterns from video data, which removes the consecutiveness requirement in the common route and accommodates a certain number of missing captured cameras for objects within the group. Moreover, a novel enumeration framework called MaxGrowth is developed to efficiently retrieve the relaxed patterns. Unlike previous filter-and-refine frameworks comprising both candidate enumeration and subsequent candidate verification procedures, MaxGrowth incurs no verification cost for the candidate patterns. It treats the co-movement pattern as an equivalent sequence of clusters, enumerating candidates with increasing sequence length while avoiding the generation of any false positives. Additionally, we also propose two effective pruning rules to efficiently filter the non-maximal patterns. Extensive experiments are conducted to validate the efficiency of MaxGrowth and the quality of its generated co-movement patterns. Our MaxGrowth runs up to two orders of magnitude faster than the baseline algorithm. It also demonstrates high accuracy in real video dataset when the trajectory recovery algorithm is not perfect.
Revisiting CNNs for Trajectory Similarity Learning
May 30, 2024



Similarity search is a fundamental but expensive operator in querying trajectory data, due to its quadratic complexity of distance computation. To mitigate the computational burden for long trajectories, neural networks have been widely employed for similarity learning and each trajectory is encoded as a high-dimensional vector for similarity search with linear complexity. Given the sequential nature of trajectory data, previous efforts have been primarily devoted to the utilization of RNNs or Transformers. In this paper, we argue that the common practice of treating trajectory as sequential data results in excessive attention to capturing long-term global dependency between two sequences. Instead, our investigation reveals the pivotal role of local similarity, prompting a revisit of simple CNNs for trajectory similarity learning. We introduce ConvTraj, incorporating both 1D and 2D convolutions to capture sequential and geo-distribution features of trajectories, respectively. In addition, we conduct a series of theoretical analyses to justify the effectiveness of ConvTraj. Experimental results on three real-world large-scale datasets demonstrate that ConvTraj achieves state-of-the-art accuracy in trajectory similarity search. Owing to the simple network structure of ConvTraj, the training and inference speed on the Porto dataset with 1.6 million trajectories are increased by at least $240$x and $2.16$x, respectively. The source code and dataset can be found at \textit{\url{https://github.com/Proudc/ConvTraj}}.
TLM: Token-Level Masking for Transformers
Oct 28, 2023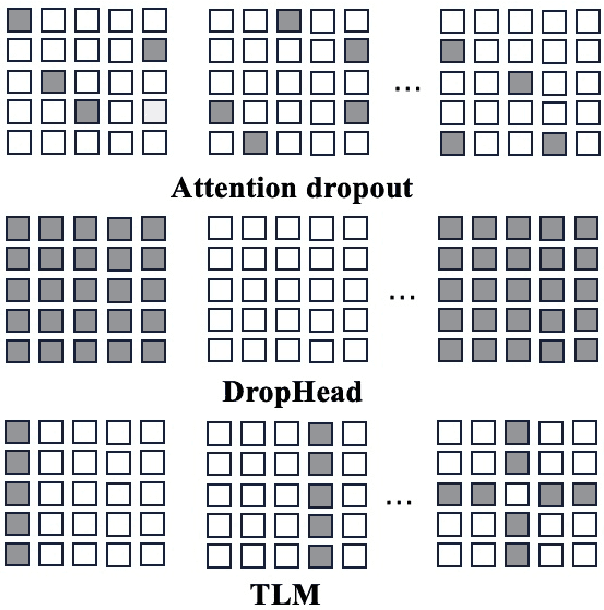

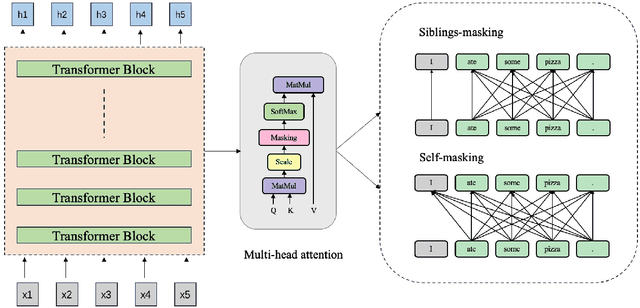

Structured dropout approaches, such as attention dropout and DropHead, have been investigated to regularize the multi-head attention mechanism in Transformers. In this paper, we propose a new regularization scheme based on token-level rather than structure-level to reduce overfitting. Specifically, we devise a novel Token-Level Masking (TLM) training strategy for Transformers to regularize the connections of self-attention, which consists of two masking techniques that are effective and easy to implement. The underlying idea is to manipulate the connections between tokens in the multi-head attention via masking, where the networks are forced to exploit partial neighbors' information to produce a meaningful representation. The generality and effectiveness of TLM are thoroughly evaluated via extensive experiments on 4 diversified NLP tasks across 18 datasets, including natural language understanding benchmark GLUE, ChineseGLUE, Chinese Grammatical Error Correction, and data-to-text generation. The results indicate that TLM can consistently outperform attention dropout and DropHead, e.g., it increases by 0.5 points relative to DropHead with BERT-large on GLUE. Moreover, TLM can establish a new record on the data-to-text benchmark Rotowire (18.93 BLEU). Our code will be publicly available at https://github.com/Young1993/tlm.
Programming Knowledge Tracing: A Comprehensive Dataset and A New Model
Dec 11, 2021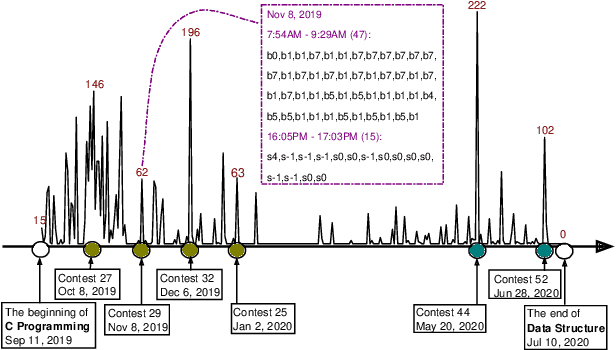
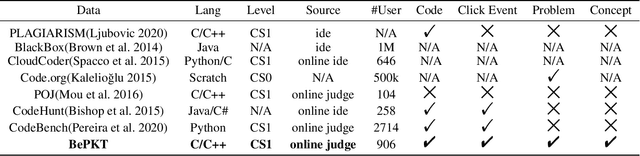
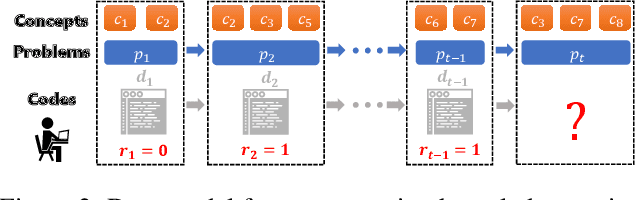
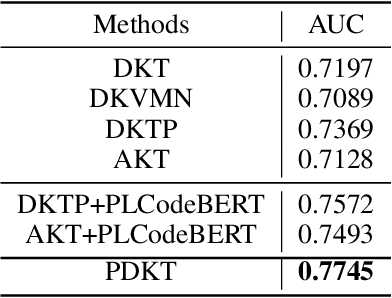
In this paper, we study knowledge tracing in the domain of programming education and make two important contributions. First, we harvest and publish so far the most comprehensive dataset, namely BePKT, which covers various online behaviors in an OJ system, including programming text problems, knowledge annotations, user-submitted code and system-logged events. Second, we propose a new model PDKT to exploit the enriched context for accurate student behavior prediction. More specifically, we construct a bipartite graph for programming problem embedding, and design an improved pre-training model PLCodeBERT for code embedding, as well as a double-sequence RNN model with exponential decay attention for effective feature fusion. Experimental results on the new dataset BePKT show that our proposed model establishes state-of-the-art performance in programming knowledge tracing. In addition, we verify that our code embedding strategy based on PLCodeBERT is complementary to existing knowledge tracing models to further enhance their accuracy. As a side product, PLCodeBERT also results in better performance in other programming-related tasks such as code clone detection.
MWPToolkit: An Open-Source Framework for Deep Learning-Based Math Word Problem Solvers
Sep 18, 2021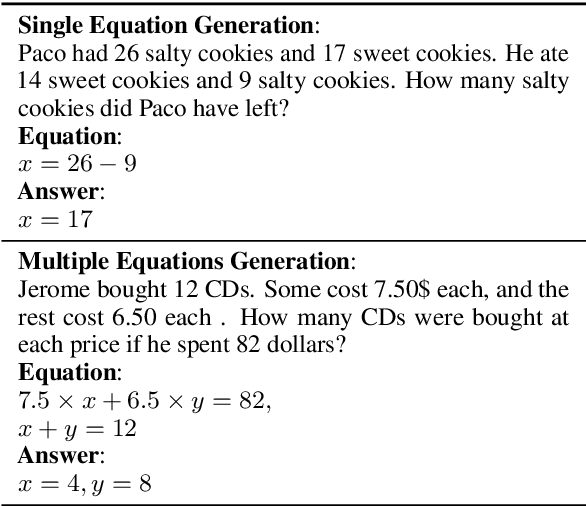
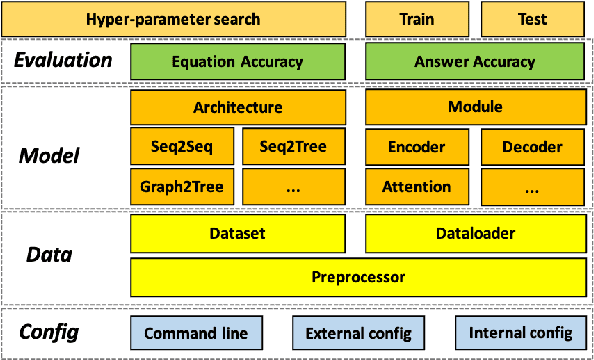
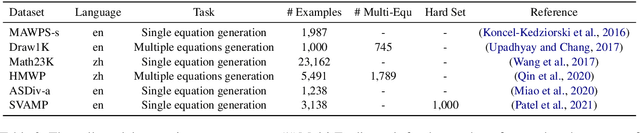
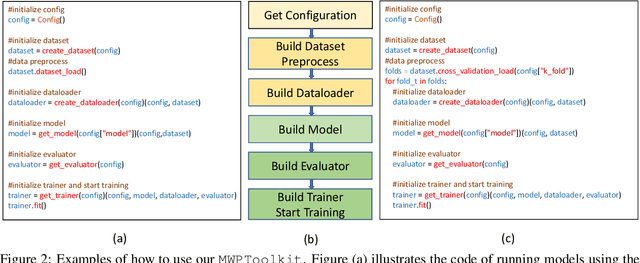
Developing automatic Math Word Problem (MWP) solvers has been an interest of NLP researchers since the 1960s. Over the last few years, there are a growing number of datasets and deep learning-based methods proposed for effectively solving MWPs. However, most existing methods are benchmarked soly on one or two datasets, varying in different configurations, which leads to a lack of unified, standardized, fair, and comprehensive comparison between methods. This paper presents MWPToolkit, the first open-source framework for solving MWPs. In MWPToolkit, we decompose the procedure of existing MWP solvers into multiple core components and decouple their models into highly reusable modules. We also provide a hyper-parameter search function to boost the performance. In total, we implement and compare 17 MWP solvers on 4 widely-used single equation generation benchmarks and 2 multiple equations generation benchmarks. These features enable our MWPToolkit to be suitable for researchers to reproduce advanced baseline models and develop new MWP solvers quickly. Code and documents are available at https://github.com/LYH-YF/MWPToolkit.
Meta-Learning Adversarial Domain Adaptation Network for Few-Shot Text Classification
Jul 26, 2021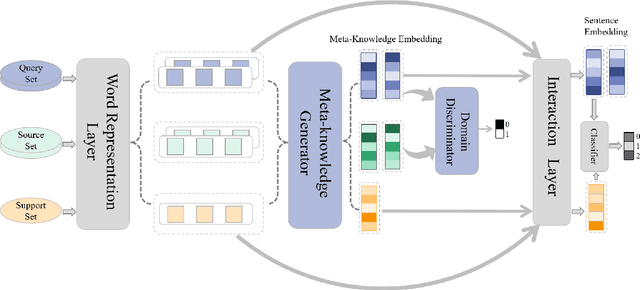

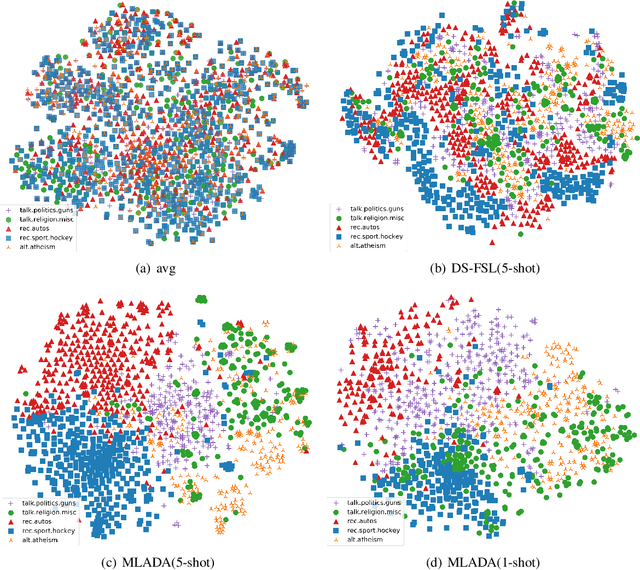
Meta-learning has emerged as a trending technique to tackle few-shot text classification and achieved state-of-the-art performance. However, existing solutions heavily rely on the exploitation of lexical features and their distributional signatures on training data, while neglecting to strengthen the model's ability to adapt to new tasks. In this paper, we propose a novel meta-learning framework integrated with an adversarial domain adaptation network, aiming to improve the adaptive ability of the model and generate high-quality text embedding for new classes. Extensive experiments are conducted on four benchmark datasets and our method demonstrates clear superiority over the state-of-the-art models in all the datasets. In particular, the accuracy of 1-shot and 5-shot classification on the dataset of 20 Newsgroups is boosted from 52.1% to 59.6%, and from 68.3% to 77.8%, respectively.
Enhancing Balanced Graph Edge Partition with Effective Local Search
Dec 17, 2020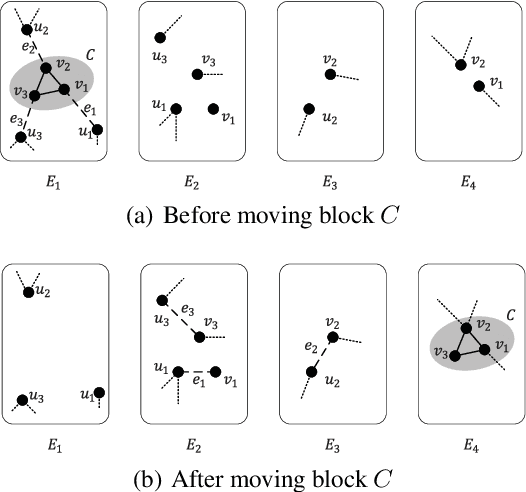
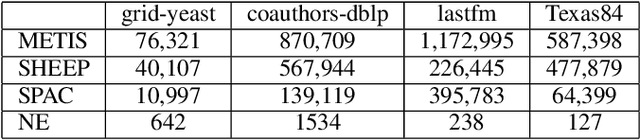
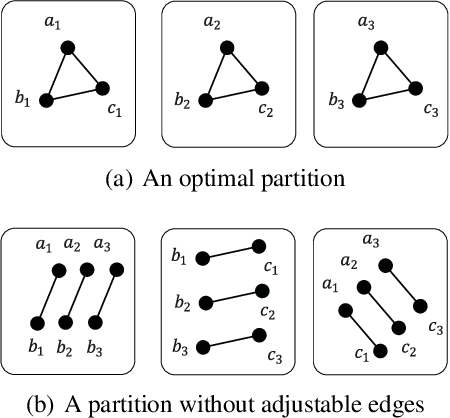
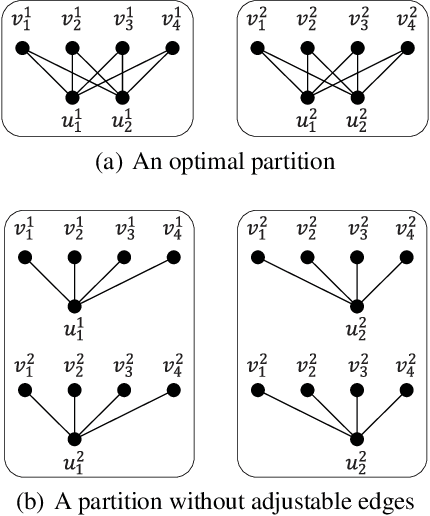
Graph partition is a key component to achieve workload balance and reduce job completion time in parallel graph processing systems. Among the various partition strategies, edge partition has demonstrated more promising performance in power-law graphs than vertex partition and thereby has been more widely adopted as the default partition strategy by existing graph systems. The graph edge partition problem, which is to split the edge set into multiple balanced parts to minimize the total number of copied vertices, has been widely studied from the view of optimization and algorithms. In this paper, we study local search algorithms for this problem to further improve the partition results from existing methods. More specifically, we propose two novel concepts, namely adjustable edges and blocks. Based on these, we develop a greedy heuristic as well as an improved search algorithm utilizing the property of the max-flow model. To evaluate the performance of our algorithms, we first provide adequate theoretical analysis in terms of the approximation quality. We significantly improve the previously known approximation ratio for this problem. Then we conduct extensive experiments on a large number of benchmark datasets and state-of-the-art edge partition strategies. The results show that our proposed local search framework can further improve the quality of graph partition by a wide margin.
One Network for Multi-Domains: Domain Adaptive Hashing with Intersectant Generative Adversarial Network
Jul 01, 2019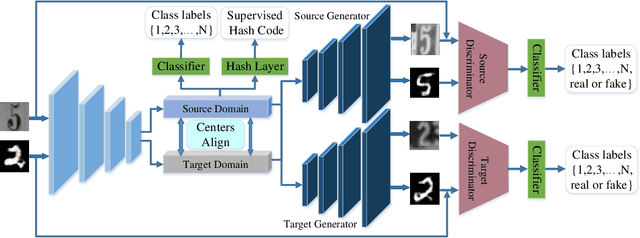
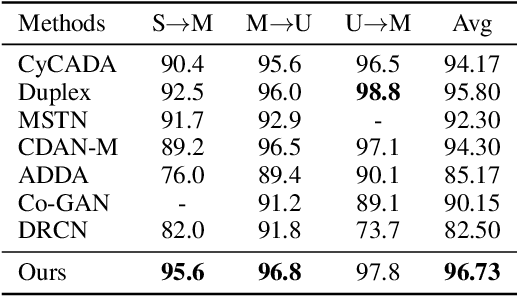
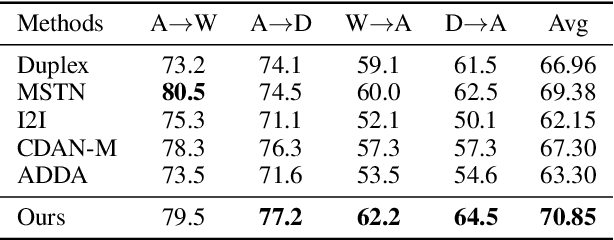

With the recent explosive increase of digital data, image recognition and retrieval become a critical practical application. Hashing is an effective solution to this problem, due to its low storage requirement and high query speed. However, most of past works focus on hashing in a single (source) domain. Thus, the learned hash function may not adapt well in a new (target) domain that has a large distributional difference with the source domain. In this paper, we explore an end-to-end domain adaptive learning framework that simultaneously and precisely generates discriminative hash codes and classifies target domain images. Our method encodes two domains images into a semantic common space, followed by two independent generative adversarial networks arming at crosswise reconstructing two domains' images, reducing domain disparity and improving alignment in the shared space. We evaluate our framework on {four} public benchmark datasets, all of which show that our method is superior to the other state-of-the-art methods on the tasks of object recognition and image retrieval.
Translating a Math Word Problem to an Expression Tree
Nov 15, 2018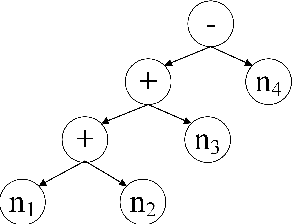
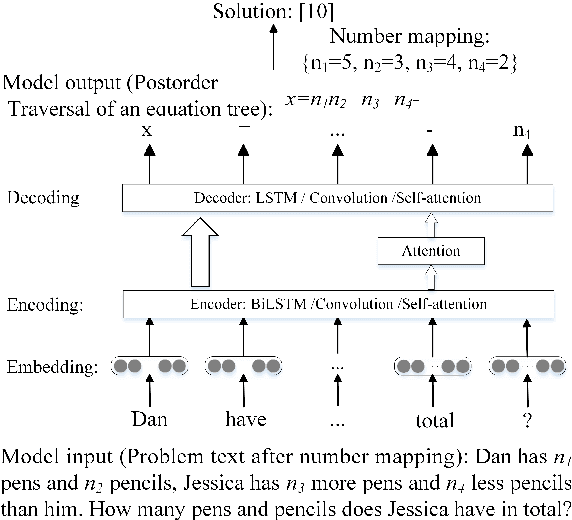
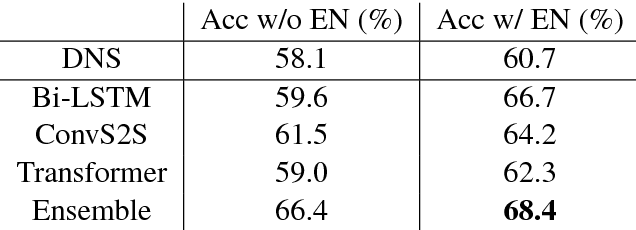
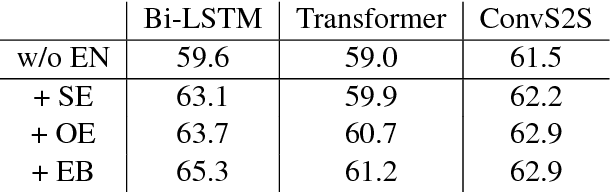
Sequence-to-sequence (SEQ2SEQ) models have been successfully applied to automatic math word problem solving. Despite its simplicity, a drawback still remains: a math word problem can be correctly solved by more than one equations. This non-deterministic transduction harms the performance of maximum likelihood estimation. In this paper, by considering the uniqueness of expression tree, we propose an equation normalization method to normalize the duplicated equations. Moreover, we analyze the performance of three popular SEQ2SEQ models on the math word problem solving. We find that each model has its own specialty in solving problems, consequently an ensemble model is then proposed to combine their advantages. Experiments on dataset Math23K show that the ensemble model with equation normalization significantly outperforms the previous state-of-the-art methods.
The Gap of Semantic Parsing: A Survey on Automatic Math Word Problem Solvers
Aug 22, 2018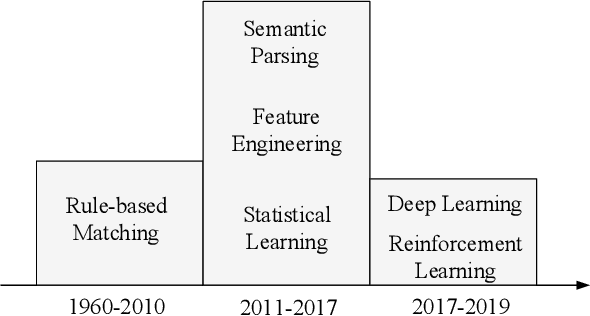
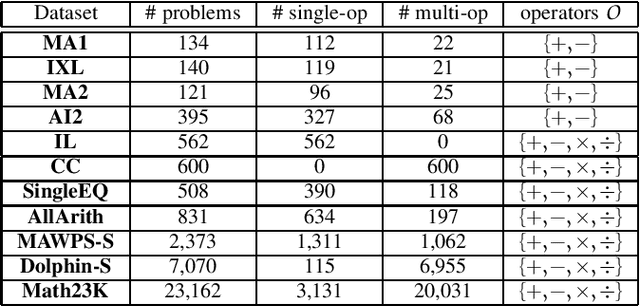

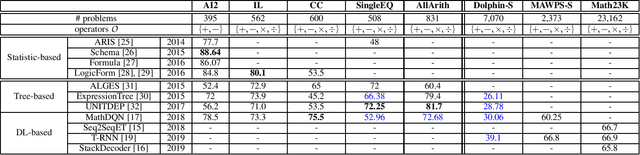
Automatically solving mathematical word problems (MWPs) is challenging, primarily due to the semantic gap between human-readable words and machine-understandable logics. Despite a long history dated back to the 1960s, MWPs has regained intensive attention in the past few years with the advancement of Artificial Intelligence (AI). To solve MWPs successfully is considered as a milestone towards general AI. Many systems have claimed promising results in self-crafted and small-scale datasets. However, when applied on large and diverse datasets, none of the proposed methods in the literatures achieves a high precision, revealing that current MWPs solvers are still far from intelligent. This motivated us to present a comprehensive survey to deliver a clear and complete picture of automatic math problem solvers. In this survey, we emphasize on algebraic word problems, summarize their extracted features and proposed techniques to bridge the semantic gap, and compare their performance in the publicly accessible datasets. We will also cover automatic solvers for other types of math problems such as geometric problems that require the understanding of diagrams. Finally, we will identify several emerging research directions for the readers with interests in MWPs.