 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Perception to Action: An Interactive Benchmark for Vision Reasoning
Feb 24, 2026Understanding the physical structure is essential for real-world applications such as embodied agents, interactive design, and long-horizon manipulation. Yet, prevailing Vision-Language Model (VLM) evaluations still center on structure-agnostic, single-turn setups (e.g., VQA), which fail to assess agents' ability to reason about how geometry, contact, and support relations jointly constrain what actions are possible in a dynamic environment. To address this gap, we introduce the Causal Hierarchy of Actions and Interactions (CHAIN) benchmark, an interactive 3D, physics-driven testbed designed to evaluate whether models can understand, plan, and execute structured action sequences grounded in physical constraints. CHAIN shifts evaluation from passive perception to active problem solving, spanning tasks such as interlocking mechanical puzzles and 3D stacking and packing. We conduct a comprehensive study of state-of-the-art VLMs and diffusion-based models under unified interactive settings. Our results show that top-performing models still struggle to internalize physical structure and causal constraints, often failing to produce reliable long-horizon plans and cannot robustly translate perceived structure into effective actions. The project is available at https://social-ai-studio.github.io/CHAIN/.
An Empirical Study on Prompt Compression for Large Language Models
Apr 24, 2025Prompt engineering enables Large Language Models (LLMs) to perform a variety of tasks. However, lengthy prompts significantly increase computational complexity and economic costs. To address this issue, we study six prompt compression methods for LLMs, aiming to reduce prompt length while maintaining LLM response quality. In this paper, we present a comprehensive analysis covering aspects such as generation performance, model hallucinations, efficacy in multimodal tasks, word omission analysis, and more. We evaluate these methods across 13 datasets, including news, scientific articles, commonsense QA, math QA, long-context QA, and VQA datasets. Our experiments reveal that prompt compression has a greater impact on LLM performance in long contexts compared to short ones. In the Longbench evaluation, moderate compression even enhances LLM performance. Our code and data is available at https://github.com/3DAgentWorld/Toolkit-for-Prompt-Compression.
DVM: Towards Controllable LLM Agents in Social Deduction Games
Jan 12, 2025



Large Language Models (LLMs) have advanced the capability of game agents in social deduction games (SDGs). These games rely heavily on conversation-driven interactions and require agents to infer, make decisions, and express based on such information. While this progress leads to more sophisticated and strategic non-player characters (NPCs) in SDGs, there exists a need to control the proficiency of these agents. This control not only ensures that NPCs can adapt to varying difficulty levels during gameplay, but also provides insights into the safety and fairness of LLM agents. In this paper, we present DVM, a novel framework for developing controllable LLM agents for SDGs, and demonstrate its implementation on one of the most popular SDGs, Werewolf. DVM comprises three main components: Predictor, Decider, and Discussor. By integrating reinforcement learning with a win rate-constrained decision chain reward mechanism, we enable agents to dynamically adjust their gameplay proficiency to achieve specified win rates. Experiments show that DVM not only outperforms existing methods in the Werewolf game, but also successfully modulates its performance levels to meet predefined win rate targets. These results pave the way for LLM agents' adaptive and balanced gameplay in SDGs, opening new avenues for research in controllable game agents.
PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models
Mar 26, 2024Prompt compression is an innovative method for efficiently condensing input prompts while preserving essential information. To facilitate quick-start services, user-friendly interfaces, and compatibility with common datasets and metrics, we present the Prompt Compression Toolkit (PCToolkit). This toolkit is a unified plug-and-play solution for compressing prompts in Large Language Models (LLMs), featuring cutting-edge prompt compressors, diverse datasets, and metrics for comprehensive performance evaluation. PCToolkit boasts a modular design, allowing for easy integration of new datasets and metrics through portable and user-friendly interfaces. In this paper, we outline the key components and functionalities of PCToolkit. We conducted evaluations of the compressors within PCToolkit across various natural language tasks, including reconstruction, summarization, mathematical problem-solving, question answering, few-shot learning, synthetic tasks, code completion, boolean expressions, multiple choice questions, and lies recognition.
All in a Single Image: Large Multimodal Models are In-Image Learners
Feb 28, 2024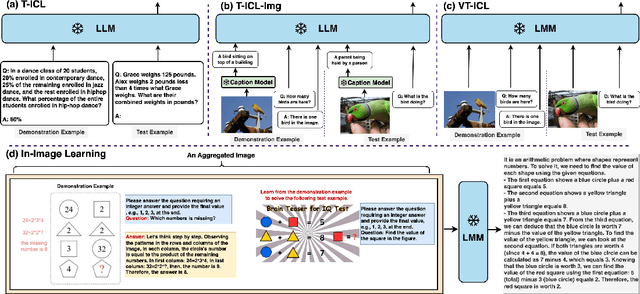
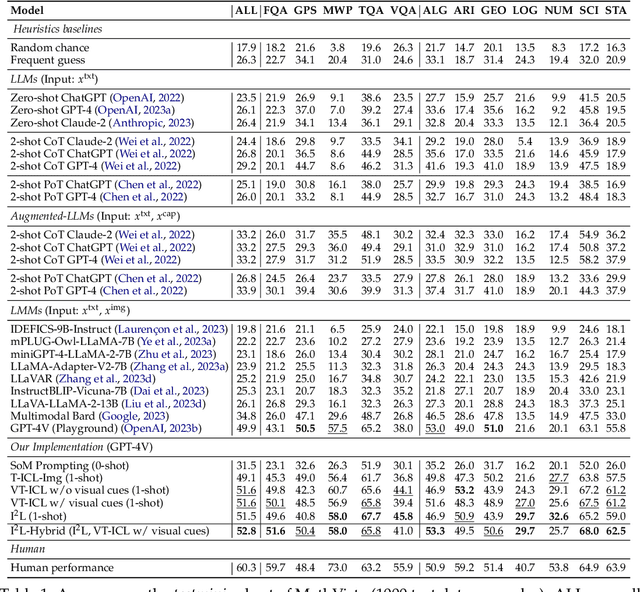
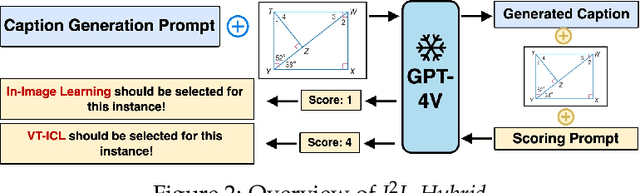

This paper introduces a new in-context learning (ICL) mechanism called In-Image Learning (I$^2$L) that combines demonstration examples, visual cues, and instructions into a single image to enhance the capabilities of GPT-4V. Unlike previous approaches that rely on converting images to text or incorporating visual input into language models, I$^2$L consolidates all information into one image and primarily leverages image processing, understanding, and reasoning abilities. This has several advantages: it avoids inaccurate textual descriptions of complex images, provides flexibility in positioning demonstration examples, reduces the input burden, and avoids exceeding input limits by eliminating the need for multiple images and lengthy text. To further combine the strengths of different ICL methods, we introduce an automatic strategy to select the appropriate ICL method for a data example in a given task. We conducted experiments on MathVista and Hallusionbench to test the effectiveness of I$^2$L in complex multimodal reasoning tasks and mitigating language hallucination and visual illusion. Additionally, we explored the impact of image resolution, the number of demonstration examples, and their positions on the effectiveness of I$^2$L. Our code is publicly available at https://github.com/AGI-Edgerunners/IIL.
LLM-Based Agent Society Investigation: Collaboration and Confrontation in Avalon Gameplay
Oct 23, 2023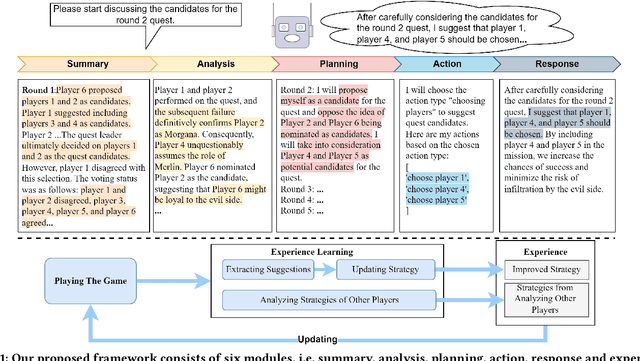

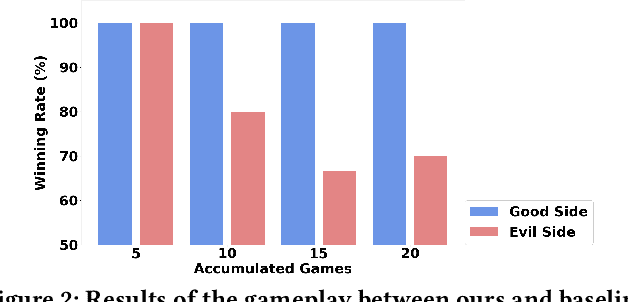
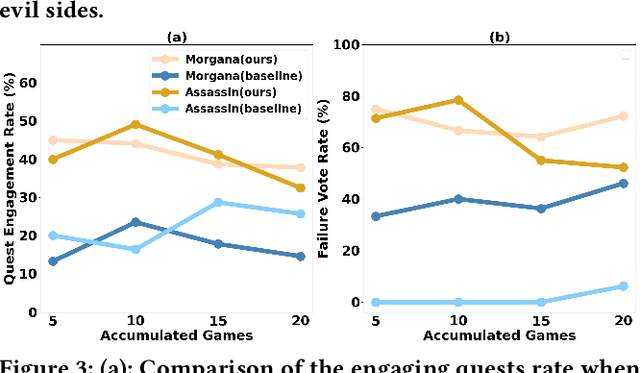
This paper aims to investigate the open research problem of uncovering the social behaviors of LLM-based agents. To achieve this goal, we adopt Avalon, a representative communication game, as the environment and use system prompts to guide LLM agents to play the game. While previous studies have conducted preliminary investigations into gameplay with LLM agents, there lacks research on their social behaviors. In this paper, we present a novel framework designed to seamlessly adapt to Avalon gameplay. The core of our proposed framework is a multi-agent system that enables efficient communication and interaction among agents. We evaluate the performance of our framework based on metrics from two perspectives: winning the game and analyzing the social behaviors of LLM agents. Our results demonstrate the effectiveness of our framework in generating adaptive and intelligent agents and highlight the potential of LLM-based agents in addressing the challenges associated with dynamic social environment interaction. By analyzing the social behaviors of LLM agents from the aspects of both collaboration and confrontation, we provide insights into the research and applications of this domain.
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
May 06, 2023Large language models (LLMs) have recently been shown to deliver impressive performance in various NLP tasks. To tackle multi-step reasoning tasks, few-shot chain-of-thought (CoT) prompting includes a few manually crafted step-by-step reasoning demonstrations which enable LLMs to explicitly generate reasoning steps and improve their reasoning task accuracy. To eliminate the manual effort, Zero-shot-CoT concatenates the target problem statement with "Let's think step by step" as an input prompt to LLMs. Despite the success of Zero-shot-CoT, it still suffers from three pitfalls: calculation errors, missing-step errors, and semantic misunderstanding errors. To address the missing-step errors, we propose Plan-and-Solve (PS) Prompting. It consists of two components: first, devising a plan to divide the entire task into smaller subtasks, and then carrying out the subtasks according to the plan. To address the calculation errors and improve the quality of generated reasoning steps, we extend PS prompting with more detailed instructions and derive PS+ prompting. We evaluate our proposed prompting strategy on ten datasets across three reasoning problems. The experimental results over GPT-3 show that our proposed zero-shot prompting consistently outperforms Zero-shot-CoT across all datasets by a large margin, is comparable to or exceeds Zero-shot-Program-of-Thought Prompting, and has comparable performance with 8-shot CoT prompting on the math reasoning problem. The code can be found at https://github.com/AGI-Edgerunners/Plan-and-Solve-Prompting.
LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
Apr 04, 2023The success of large language models (LLMs), like GPT-3 and ChatGPT, has led to the development of numerous cost-effective and accessible alternatives that are created by fine-tuning open-access LLMs with task-specific data (e.g., ChatDoctor) or instruction data (e.g., Alpaca). Among the various fine-tuning methods, adapter-based parameter-efficient fine-tuning (PEFT) is undoubtedly one of the most attractive topics, as it only requires fine-tuning a few external parameters instead of the entire LLMs while achieving comparable or even better performance. To enable further research on PEFT methods of LLMs, this paper presents LLM-Adapters, an easy-to-use framework that integrates various adapters into LLMs and can execute these adapter-based PEFT methods of LLMs for different tasks. The framework includes state-of-the-art open-access LLMs such as LLaMA, BLOOM, OPT, and GPT-J, as well as widely used adapters such as Series adapter, Parallel adapter, and LoRA. The framework is designed to be research-friendly, efficient, modular, and extendable, allowing the integration of new adapters and the evaluation of them with new and larger-scale LLMs. Furthermore, to evaluate the effectiveness of adapters in LLMs-Adapters, we conduct experiments on six math reasoning datasets. The results demonstrate that using adapter-based PEFT in smaller-scale LLMs (7B) with few extra trainable parameters yields comparable, and in some cases superior, performance to that of powerful LLMs (175B) in zero-shot inference on simple math reasoning datasets. Overall, we provide a promising framework for fine-tuning large LLMs on downstream tasks. We believe the proposed LLMs-Adapters will advance adapter-based PEFT research, facilitate the deployment of research pipelines, and enable practical applications to real-world systems.
MWPToolkit: An Open-Source Framework for Deep Learning-Based Math Word Problem Solvers
Sep 18, 2021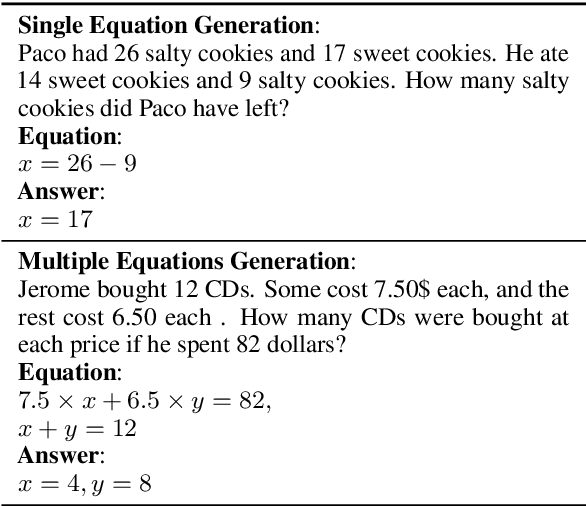
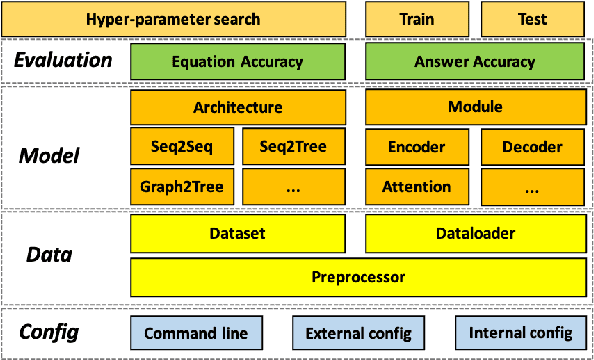
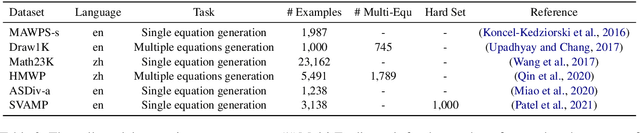
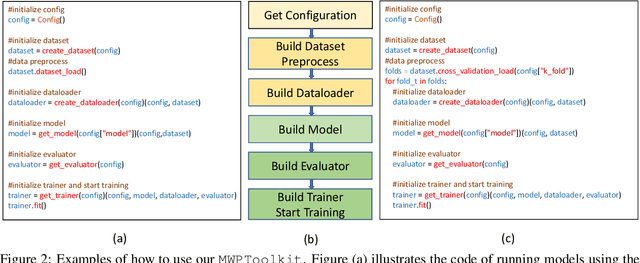
Developing automatic Math Word Problem (MWP) solvers has been an interest of NLP researchers since the 1960s. Over the last few years, there are a growing number of datasets and deep learning-based methods proposed for effectively solving MWPs. However, most existing methods are benchmarked soly on one or two datasets, varying in different configurations, which leads to a lack of unified, standardized, fair, and comprehensive comparison between methods. This paper presents MWPToolkit, the first open-source framework for solving MWPs. In MWPToolkit, we decompose the procedure of existing MWP solvers into multiple core components and decouple their models into highly reusable modules. We also provide a hyper-parameter search function to boost the performance. In total, we implement and compare 17 MWP solvers on 4 widely-used single equation generation benchmarks and 2 multiple equations generation benchmarks. These features enable our MWPToolkit to be suitable for researchers to reproduce advanced baseline models and develop new MWP solvers quickly. Code and documents are available at https://github.com/LYH-YF/MWPToolkit.