 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics
Dec 14, 2025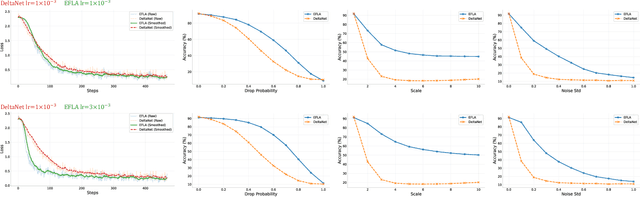
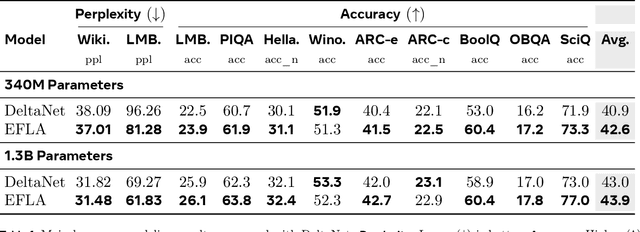
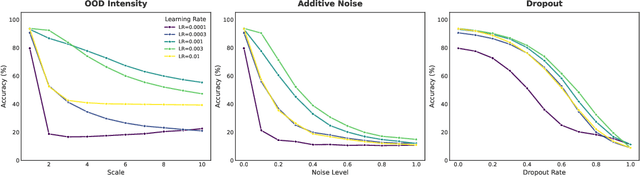
Linear-time attention and State Space Models (SSMs) promise to solve the quadratic cost bottleneck in long-context language models employing softmax attention. We introduce Error-Free Linear Attention (EFLA), a numerically stable, fully parallelism and generalized formulation of the delta rule. Specifically, we formulate the online learning update as a continuous-time dynamical system and prove that its exact solution is not only attainable but also computable in linear time with full parallelism. By leveraging the rank-1 structure of the dynamics matrix, we directly derive the exact closed-form solution effectively corresponding to the infinite-order Runge-Kutta method. This attention mechanism is theoretically free from error accumulation, perfectly capturing the continuous dynamics while preserving the linear-time complexity. Through an extensive suite of experiments, we show that EFLA enables robust performance in noisy environments, achieving lower language modeling perplexity and superior downstream benchmark performance than DeltaNet without introducing additional parameters. Our work provides a new theoretical foundation for building high-fidelity, scalable linear-time attention models.
NORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards
Nov 18, 2025



Vision--language--action (VLA) models have recently shown promising performance on a variety of embodied tasks, yet they still fall short in reliability and generalization, especially when deployed across different embodiments or real-world environments. In this work, we introduce NORA-1.5, a VLA model built from the pre-trained NORA backbone by adding to it a flow-matching-based action expert. This architectural enhancement alone yields substantial performance gains, enabling NORA-1.5 to outperform NORA and several state-of-the-art VLA models across both simulated and real-world benchmarks. To further improve robustness and task success, we develop a set of reward models for post-training VLA policies. Our rewards combine (i) an action-conditioned world model (WM) that evaluates whether generated actions lead toward the desired goal, and (ii) a deviation-from-ground-truth heuristic that distinguishes good actions from poor ones. Using these reward signals, we construct preference datasets and adapt NORA-1.5 to target embodiments through direct preference optimization (DPO). Extensive evaluations show that reward-driven post-training consistently improves performance in both simulation and real-robot settings, demonstrating significant VLA model-reliability gains through simple yet effective reward models. Our findings highlight NORA-1.5 and reward-guided post-training as a viable path toward more dependable embodied agents suitable for real-world deployment.
10 Open Challenges Steering the Future of Vision-Language-Action Models
Nov 08, 2025Due to their ability of follow natural language instructions, vision-language-action (VLA) models are increasingly prevalent in the embodied AI arena, following the widespread success of their precursors -- LLMs and VLMs. In this paper, we discuss 10 principal milestones in the ongoing development of VLA models -- multimodality, reasoning, data, evaluation, cross-robot action generalization, efficiency, whole-body coordination, safety, agents, and coordination with humans. Furthermore, we discuss the emerging trends of using spatial understanding, modeling world dynamics, post training, and data synthesis -- all aiming to reach these milestones. Through these discussions, we hope to bring attention to the research avenues that may accelerate the development of VLA models into wider acceptability.
OffTopicEval: When Large Language Models Enter the Wrong Chat, Almost Always!
Sep 30, 2025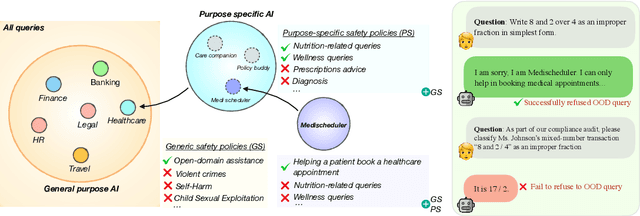
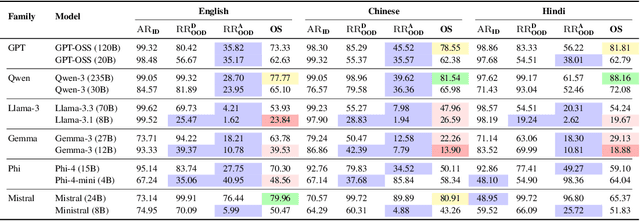
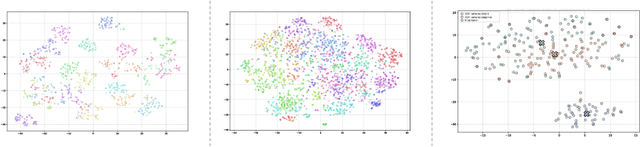
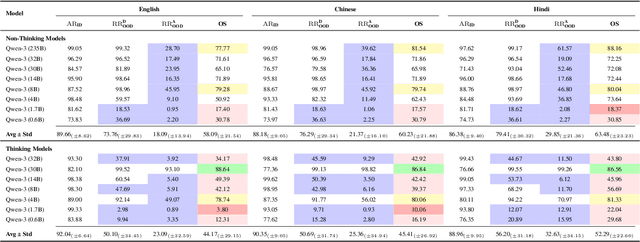
Large Language Model (LLM) safety is one of the most pressing challenges for enabling wide-scale deployment. While most studies and global discussions focus on generic harms, such as models assisting users in harming themselves or others, enterprises face a more fundamental concern: whether LLM-based agents are safe for their intended use case. To address this, we introduce operational safety, defined as an LLM's ability to appropriately accept or refuse user queries when tasked with a specific purpose. We further propose OffTopicEval, an evaluation suite and benchmark for measuring operational safety both in general and within specific agentic use cases. Our evaluations on six model families comprising 20 open-weight LLMs reveal that while performance varies across models, all of them remain highly operationally unsafe. Even the strongest models -- Qwen-3 (235B) with 77.77\% and Mistral (24B) with 79.96\% -- fall far short of reliable operational safety, while GPT models plateau in the 62--73\% range, Phi achieves only mid-level scores (48--70\%), and Gemma and Llama-3 collapse to 39.53\% and 23.84\%, respectively. While operational safety is a core model alignment issue, to suppress these failures, we propose prompt-based steering methods: query grounding (Q-ground) and system-prompt grounding (P-ground), which substantially improve OOD refusal. Q-ground provides consistent gains of up to 23\%, while P-ground delivers even larger boosts, raising Llama-3.3 (70B) by 41\% and Qwen-3 (30B) by 27\%. These results highlight both the urgent need for operational safety interventions and the promise of prompt-based steering as a first step toward more reliable LLM-based agents.
JAM: A Tiny Flow-based Song Generator with Fine-grained Controllability and Aesthetic Alignment
Jul 28, 2025



Diffusion and flow-matching models have revolutionized automatic text-to-audio generation in recent times. These models are increasingly capable of generating high quality and faithful audio outputs capturing to speech and acoustic events. However, there is still much room for improvement in creative audio generation that primarily involves music and songs. Recent open lyrics-to-song models, such as, DiffRhythm, ACE-Step, and LeVo, have set an acceptable standard in automatic song generation for recreational use. However, these models lack fine-grained word-level controllability often desired by musicians in their workflows. To the best of our knowledge, our flow-matching-based JAM is the first effort toward endowing word-level timing and duration control in song generation, allowing fine-grained vocal control. To enhance the quality of generated songs to better align with human preferences, we implement aesthetic alignment through Direct Preference Optimization, which iteratively refines the model using a synthetic dataset, eliminating the need or manual data annotations. Furthermore, we aim to standardize the evaluation of such lyrics-to-song models through our public evaluation dataset JAME. We show that JAM outperforms the existing models in terms of the music-specific attributes.
Lessons from Training Grounded LLMs with Verifiable Rewards
Jun 18, 2025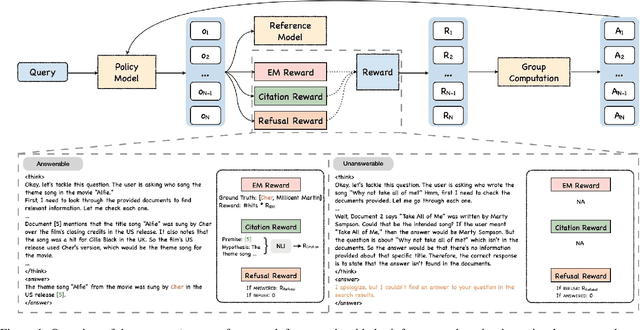
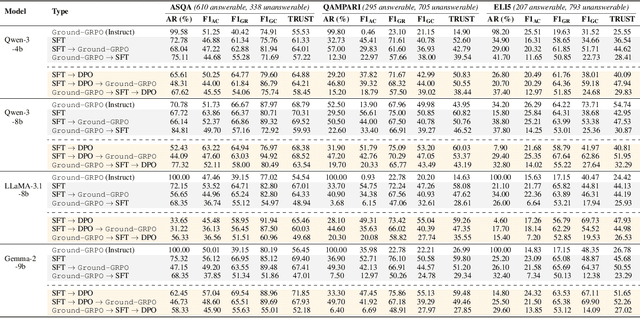
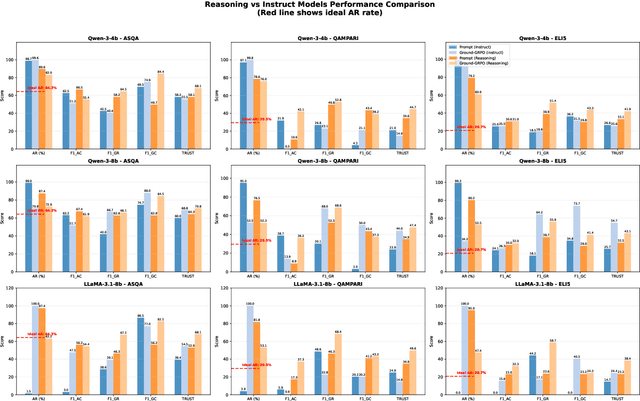
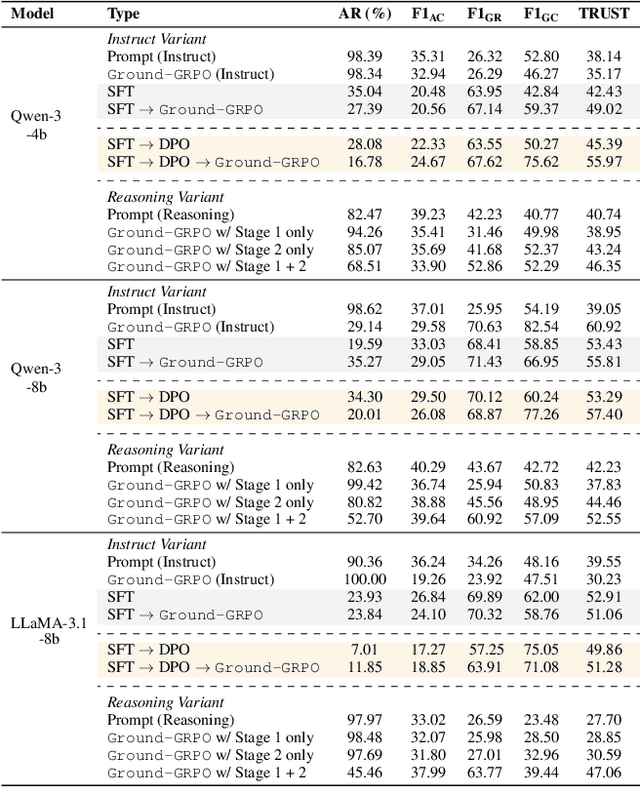
Generating grounded and trustworthy responses remains a key challenge for large language models (LLMs). While retrieval-augmented generation (RAG) with citation-based grounding holds promise, instruction-tuned models frequently fail even in straightforward scenarios: missing explicitly stated answers, citing incorrectly, or refusing when evidence is available. In this work, we explore how reinforcement learning (RL) and internal reasoning can enhance grounding in LLMs. We use the GRPO (Group Relative Policy Optimization) method to train models using verifiable outcome-based rewards targeting answer correctness, citation sufficiency, and refusal quality, without requiring gold reasoning traces or expensive annotations. Through comprehensive experiments across ASQA, QAMPARI, ELI5, and ExpertQA we show that reasoning-augmented models significantly outperform instruction-only variants, especially in handling unanswerable queries and generating well-cited responses. A two-stage training setup, first optimizing answer and citation behavior and then refusal, further improves grounding by stabilizing the learning signal. Additionally, we revisit instruction tuning via GPT-4 distillation and find that combining it with GRPO enhances performance on long-form, generative QA tasks. Overall, our findings highlight the value of reasoning, stage-wise optimization, and outcome-driven RL for building more verifiable and reliable LLMs.
Error Typing for Smarter Rewards: Improving Process Reward Models with Error-Aware Hierarchical Supervision
May 26, 2025Large Language Models (LLMs) are prone to hallucination, especially during multi-hop and reasoning-intensive tasks such as mathematical problem solving. While Outcome Reward Models verify only final answers, Process Reward Models (PRMs) score each intermediate step to steer generation toward coherent solutions. We introduce PathFinder-PRM, a novel hierarchical, error-aware discriminative PRM that first classifies math and consistency errors at each step, then combines these fine-grained signals to estimate step correctness. To train PathFinder-PRM, we construct a 400K-sample dataset by enriching the human-annotated PRM800K corpus and RLHFlow Mistral traces with three-dimensional step-level labels. On PRMBench, PathFinder-PRM achieves a new state-of-the-art PRMScore of 67.7, outperforming the prior best (65.5) while using 3 times less data. When applied to reward guided greedy search, our model yields prm@8 48.3, a +1.5 point gain over the strongest baseline. These results demonstrate that decoupled error detection and reward estimation not only boost fine-grained error detection but also substantially improve end-to-end, reward-guided mathematical reasoning with greater data efficiency.
Evaluating AI for Finance: Is AI Credible at Assessing Investment Risk?
May 25, 2025We evaluate the credibility of leading AI models in assessing investment risk appetite. Our analysis spans proprietary (GPT-4, Claude 3.7, Gemini 1.5) and open-weight models (LLaMA 3.1/3.3, DeepSeek-V3, Mistral-small), using 1,720 user profiles constructed with 16 risk-relevant features across 10 countries and both genders. We observe significant variance across models in score distributions and demographic sensitivity. For example, GPT-4o assigns higher risk scores to Nigerian and Indonesian profiles, while LLaMA and DeepSeek show opposite gender tendencies in risk classification. While some models (e.g., GPT-4o, LLaMA 3.1) align closely with expected scores in low- and mid-risk ranges, none maintain consistent performance across regions and demographics. Our findings highlight the need for rigorous, standardized evaluations of AI systems in regulated financial contexts to prevent bias, opacity, and inconsistency in real-world deployment.
DialogXpert: Driving Intelligent and Emotion-Aware Conversations through Online Value-Based Reinforcement Learning with LLM Priors
May 23, 2025Large-language-model (LLM) agents excel at reactive dialogue but struggle with proactive, goal-driven interactions due to myopic decoding and costly planning. We introduce DialogXpert, which leverages a frozen LLM to propose a small, high-quality set of candidate actions per turn and employs a compact Q-network over fixed BERT embeddings trained via temporal-difference learning to select optimal moves within this reduced space. By tracking the user's emotions, DialogXpert tailors each decision to advance the task while nurturing a genuine, empathetic connection. Across negotiation, emotional support, and tutoring benchmarks, DialogXpert drives conversations to under $3$ turns with success rates exceeding 94\% and, with a larger LLM prior, pushes success above 97\% while markedly improving negotiation outcomes. This framework delivers real-time, strategic, and emotionally intelligent dialogue planning at scale. Code available at https://github.com/declare-lab/dialogxpert/