 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Theorem Proving for Verification Conditions: A Real-World Benchmark
Jan 26, 2026Theorem proving is fundamental to program verification, where the automated proof of Verification Conditions (VCs) remains a primary bottleneck. Real-world program verification frequently encounters hard VCs that existing Automated Theorem Provers (ATPs) cannot prove, leading to a critical need for extensive manual proofs that burden practical application. While Neural Theorem Proving (NTP) has achieved significant success in mathematical competitions, demonstrating the potential of machine learning approaches to formal reasoning, its application to program verification--particularly VC proving--remains largely unexplored. Despite existing work on annotation synthesis and verification-related theorem proving, no benchmark has specifically targeted this fundamental bottleneck: automated VC proving. This work introduces Neural Theorem Proving for Verification Conditions (NTP4VC), presenting the first real-world multi-language benchmark for this task. From real-world projects such as Linux and Contiki-OS kernel, our benchmark leverages industrial pipelines (Why3 and Frama-C) to generate semantically equivalent test cases across formal languages of Isabelle, Lean, and Rocq. We evaluate large language models (LLMs), both general-purpose and those fine-tuned for theorem proving, on NTP4VC. Results indicate that although LLMs show promise in VC proving, significant challenges remain for program verification, highlighting a large gap and opportunity for future research.
TorchTraceAP: A New Benchmark Dataset for Detecting Performance Anti-Patterns in Computer Vision Models
Dec 16, 2025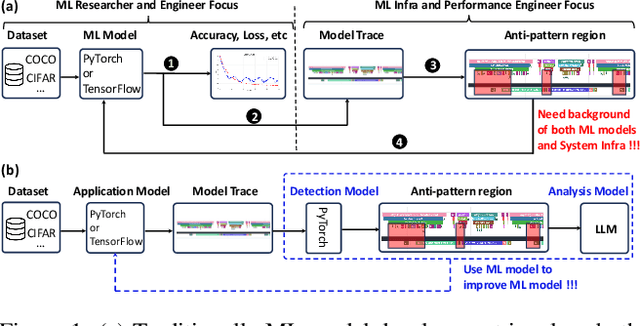
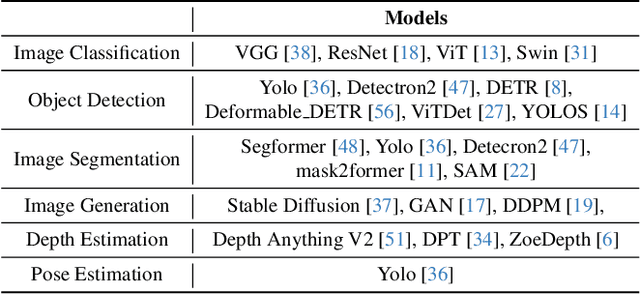
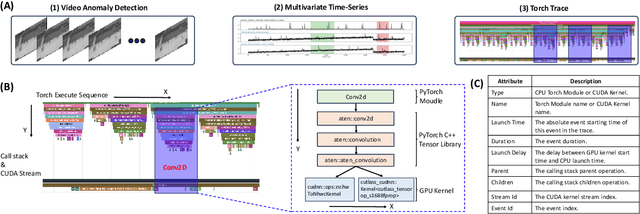

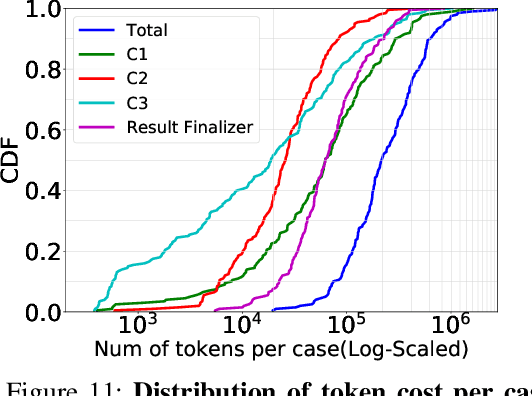
Identifying and addressing performance anti-patterns in machine learning (ML) models is critical for efficient training and inference, but it typically demands deep expertise spanning system infrastructure, ML models and kernel development. While large tech companies rely on dedicated ML infrastructure engineers to analyze torch traces and benchmarks, such resource-intensive workflows are largely inaccessible to computer vision researchers in general. Among the challenges, pinpointing problematic trace segments within lengthy execution traces remains the most time-consuming task, and is difficult to automate with current ML models, including LLMs. In this work, we present the first benchmark dataset specifically designed to evaluate and improve ML models' ability to detect anti patterns in traces. Our dataset contains over 600 PyTorch traces from diverse computer vision models classification, detection, segmentation, and generation collected across multiple hardware platforms. We also propose a novel iterative approach: a lightweight ML model first detects trace segments with anti patterns, followed by a large language model (LLM) for fine grained classification and targeted feedback. Experimental results demonstrate that our method significantly outperforms unsupervised clustering and rule based statistical techniques for detecting anti pattern regions. Our method also effectively compensates LLM's limited context length and reasoning inefficiencies.
LLMBisect: Breaking Barriers in Bug Bisection with A Comparative Analysis Pipeline
Oct 30, 2025
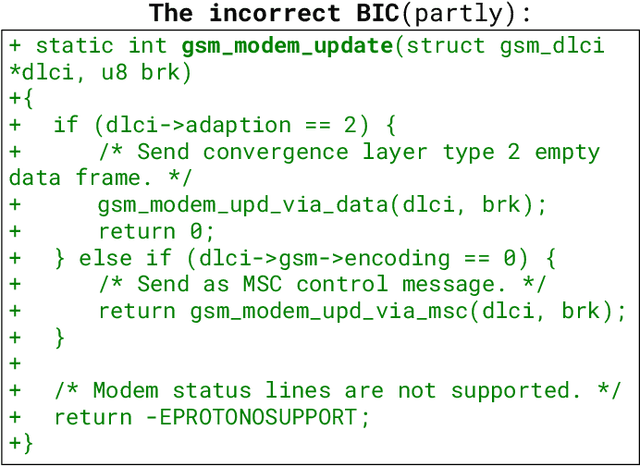
Bug bisection has been an important security task that aims to understand the range of software versions impacted by a bug, i.e., identifying the commit that introduced the bug. However, traditional patch-based bisection methods are faced with several significant barriers: For example, they assume that the bug-inducing commit (BIC) and the patch commit modify the same functions, which is not always true. They often rely solely on code changes, while the commit message frequently contains a wealth of vulnerability-related information. They are also based on simple heuristics (e.g., assuming the BIC initializes lines deleted in the patch) and lack any logical analysis of the vulnerability. In this paper, we make the observation that Large Language Models (LLMs) are well-positioned to break the barriers of existing solutions, e.g., comprehend both textual data and code in patches and commits. Unlike previous BIC identification approaches, which yield poor results, we propose a comprehensive multi-stage pipeline that leverages LLMs to: (1) fully utilize patch information, (2) compare multiple candidate commits in context, and (3) progressively narrow down the candidates through a series of down-selection steps. In our evaluation, we demonstrate that our approach achieves significantly better accuracy than the state-of-the-art solution by more than 38\%. Our results further confirm that the comprehensive multi-stage pipeline is essential, as it improves accuracy by 60\% over a baseline LLM-based bisection method.
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
BALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025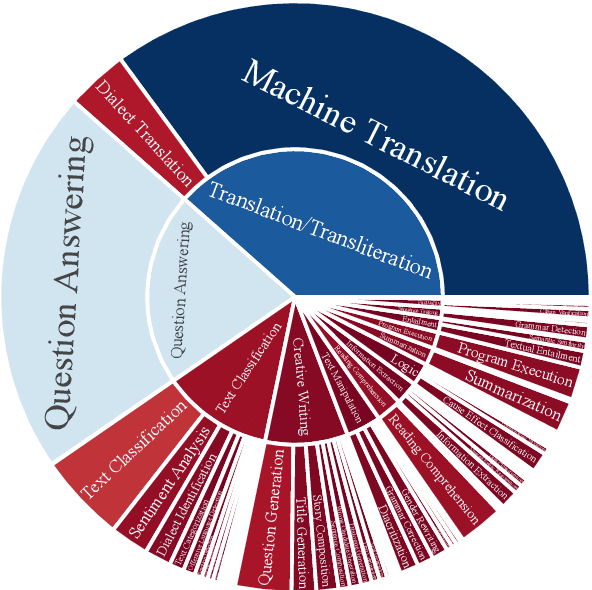



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025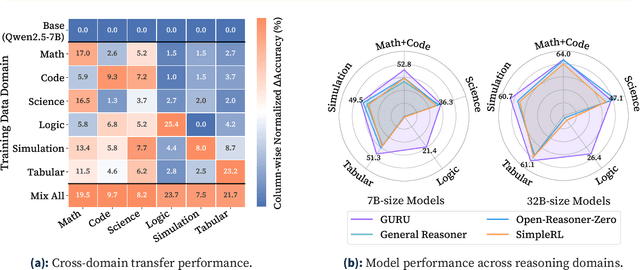
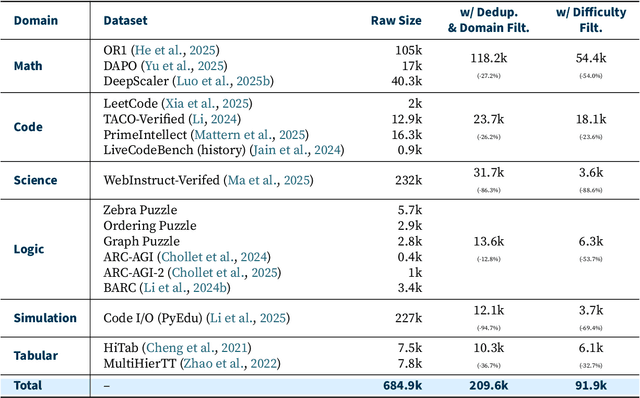
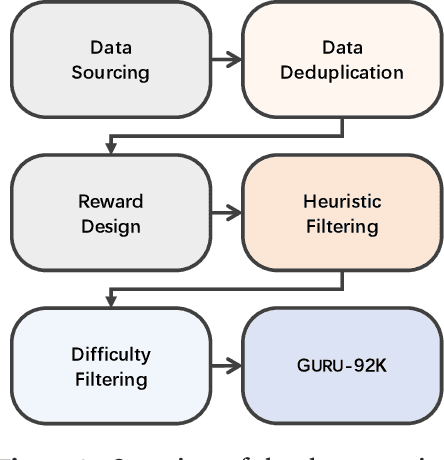

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
The Hitchhiker's Guide to Program Analysis, Part II: Deep Thoughts by LLMs
Apr 16, 2025Static analysis is a cornerstone for software vulnerability detection, yet it often struggles with the classic precision-scalability trade-off. In practice, such tools often produce high false positive rates, particularly in large codebases like the Linux kernel. This imprecision can arise from simplified vulnerability modeling and over-approximation of path and data constraints. While large language models (LLMs) show promise in code understanding, their naive application to program analysis yields unreliable results due to inherent reasoning limitations. We introduce BugLens, a post-refinement framework that significantly improves static analysis precision. BugLens guides an LLM to follow traditional analysis steps by assessing buggy code patterns for security impact and validating the constraints associated with static warnings. Evaluated on real-world Linux kernel bugs, BugLens raises precision from 0.10 (raw) and 0.50 (semi-automated refinement) to 0.72, substantially reducing false positives and revealing four previously unreported vulnerabilities. Our results suggest that a structured LLM-based workflow can meaningfully enhance the effectiveness of static analysis tools.
Llama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Apr 08, 2025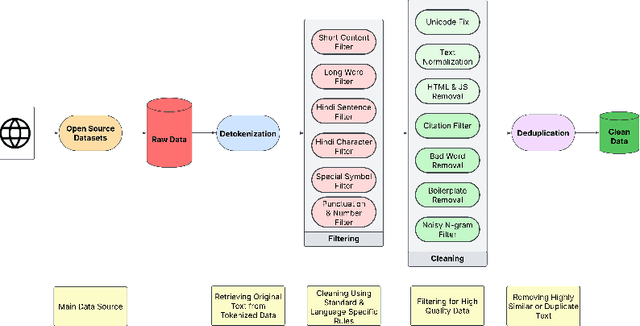

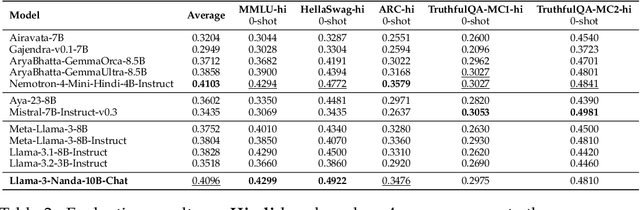

Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
Hawkeye:Efficient Reasoning with Model Collaboration
Apr 01, 2025Chain-of-Thought (CoT) reasoning has demonstrated remarkable effectiveness in enhancing the reasoning abilities of large language models (LLMs). However, its efficiency remains a challenge due to the generation of excessive intermediate reasoning tokens, which introduce semantic redundancy and overly detailed reasoning steps. Moreover, computational expense and latency are significant concerns, as the cost scales with the number of output tokens, including those intermediate steps. In this work, we observe that most CoT tokens are unnecessary, and retaining only a small portion of them is sufficient for producing high-quality responses. Inspired by this, we propose HAWKEYE, a novel post-training and inference framework where a large model produces concise CoT instructions to guide a smaller model in response generation. HAWKEYE quantifies redundancy in CoT reasoning and distills high-density information via reinforcement learning. By leveraging these concise CoTs, HAWKEYE is able to expand responses while reducing token usage and computational cost significantly. Our evaluation shows that HAWKEYE can achieve comparable response quality using only 35% of the full CoTs, while improving clarity, coherence, and conciseness by approximately 10%. Furthermore, HAWKEYE can accelerate end-to-end reasoning by up to 3.4x on complex math tasks while reducing inference cost by up to 60%. HAWKEYE will be open-sourced and the models will be available soon.
Kaiwu: A Multimodal Manipulation Dataset and Framework for Robot Learning and Human-Robot Interaction
Mar 07, 2025



Cutting-edge robot learning techniques including foundation models and imitation learning from humans all pose huge demands on large-scale and high-quality datasets which constitute one of the bottleneck in the general intelligent robot fields. This paper presents the Kaiwu multimodal dataset to address the missing real-world synchronized multimodal data problems in the sophisticated assembling scenario,especially with dynamics information and its fine-grained labelling. The dataset first provides an integration of human,environment and robot data collection framework with 20 subjects and 30 interaction objects resulting in totally 11,664 instances of integrated actions. For each of the demonstration,hand motions,operation pressures,sounds of the assembling process,multi-view videos, high-precision motion capture information,eye gaze with first-person videos,electromyography signals are all recorded. Fine-grained multi-level annotation based on absolute timestamp,and semantic segmentation labelling are performed. Kaiwu dataset aims to facilitate robot learning,dexterous manipulation,human intention investigation and human-robot collaboration research.