 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient Reinforcement for Reasoning Large Language Models via Dynamic One-Shot Policy Refinement
Jan 31, 2026Large language models (LLMs) have exhibited remarkable performance on complex reasoning tasks, with reinforcement learning under verifiable rewards (RLVR) emerging as a principled framework for aligning model behavior with reasoning chains. Despite its promise, RLVR remains prohibitively resource-intensive, requiring extensive reward signals and incurring substantial rollout costs during training. In this work, we revisit the fundamental question of data and compute efficiency in RLVR. We first establish a theoretical lower bound on the sample complexity required to unlock reasoning capabilities, and empirically validate that strong performance can be achieved with a surprisingly small number of training instances. To tackle the computational burden, we propose Dynamic One-Shot Policy Refinement (DoPR), an uncertainty-aware RL strategy that dynamically selects a single informative training sample per batch for policy updates, guided by reward volatility and exploration-driven acquisition. DoPR reduces rollout overhead by nearly an order of magnitude while preserving competitive reasoning accuracy, offering a scalable and resource-efficient solution for LLM post-training. This approach offers a practical path toward more efficient and accessible RL-based training for reasoning-intensive LLM applications.
Weakly-Supervised Affordance Grounding Guided by Part-Level Semantic Priors
May 30, 2025In this work, we focus on the task of weakly supervised affordance grounding, where a model is trained to identify affordance regions on objects using human-object interaction images and egocentric object images without dense labels. Previous works are mostly built upon class activation maps, which are effective for semantic segmentation but may not be suitable for locating actions and functions. Leveraging recent advanced foundation models, we develop a supervised training pipeline based on pseudo labels. The pseudo labels are generated from an off-the-shelf part segmentation model, guided by a mapping from affordance to part names. Furthermore, we introduce three key enhancements to the baseline model: a label refining stage, a fine-grained feature alignment process, and a lightweight reasoning module. These techniques harness the semantic knowledge of static objects embedded in off-the-shelf foundation models to improve affordance learning, effectively bridging the gap between objects and actions. Extensive experiments demonstrate that the performance of the proposed model has achieved a breakthrough improvement over existing methods. Our codes are available at https://github.com/woyut/WSAG-PLSP .
Hawkeye:Efficient Reasoning with Model Collaboration
Apr 01, 2025Chain-of-Thought (CoT) reasoning has demonstrated remarkable effectiveness in enhancing the reasoning abilities of large language models (LLMs). However, its efficiency remains a challenge due to the generation of excessive intermediate reasoning tokens, which introduce semantic redundancy and overly detailed reasoning steps. Moreover, computational expense and latency are significant concerns, as the cost scales with the number of output tokens, including those intermediate steps. In this work, we observe that most CoT tokens are unnecessary, and retaining only a small portion of them is sufficient for producing high-quality responses. Inspired by this, we propose HAWKEYE, a novel post-training and inference framework where a large model produces concise CoT instructions to guide a smaller model in response generation. HAWKEYE quantifies redundancy in CoT reasoning and distills high-density information via reinforcement learning. By leveraging these concise CoTs, HAWKEYE is able to expand responses while reducing token usage and computational cost significantly. Our evaluation shows that HAWKEYE can achieve comparable response quality using only 35% of the full CoTs, while improving clarity, coherence, and conciseness by approximately 10%. Furthermore, HAWKEYE can accelerate end-to-end reasoning by up to 3.4x on complex math tasks while reducing inference cost by up to 60%. HAWKEYE will be open-sourced and the models will be available soon.
FedConv: Enhancing Convolutional Neural Networks for Handling Data Heterogeneity in Federated Learning
Oct 06, 2023


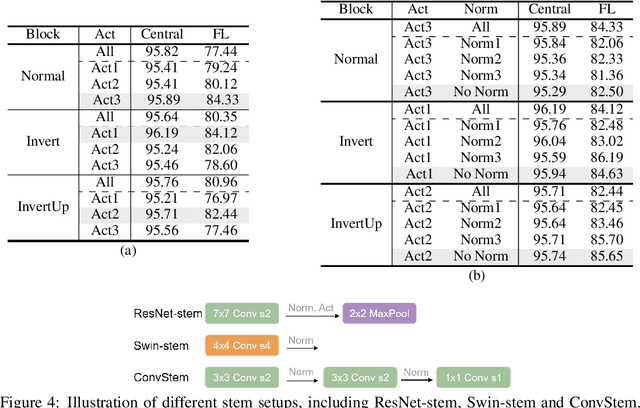
Federated learning (FL) is an emerging paradigm in machine learning, where a shared model is collaboratively learned using data from multiple devices to mitigate the risk of data leakage. While recent studies posit that Vision Transformer (ViT) outperforms Convolutional Neural Networks (CNNs) in addressing data heterogeneity in FL, the specific architectural components that underpin this advantage have yet to be elucidated. In this paper, we systematically investigate the impact of different architectural elements, such as activation functions and normalization layers, on the performance within heterogeneous FL. Through rigorous empirical analyses, we are able to offer the first-of-its-kind general guidance on micro-architecture design principles for heterogeneous FL. Intriguingly, our findings indicate that with strategic architectural modifications, pure CNNs can achieve a level of robustness that either matches or even exceeds that of ViTs when handling heterogeneous data clients in FL. Additionally, our approach is compatible with existing FL techniques and delivers state-of-the-art solutions across a broad spectrum of FL benchmarks. The code is publicly available at https://github.com/UCSC-VLAA/FedConv
Co-Salient Object Detection with Semantic-Level Consensus Extraction and Dispersion
Sep 14, 2023



Given a group of images, co-salient object detection (CoSOD) aims to highlight the common salient object in each image. There are two factors closely related to the success of this task, namely consensus extraction, and the dispersion of consensus to each image. Most previous works represent the group consensus using local features, while we instead utilize a hierarchical Transformer module for extracting semantic-level consensus. Therefore, it can obtain a more comprehensive representation of the common object category, and exclude interference from other objects that share local similarities with the target object. In addition, we propose a Transformer-based dispersion module that takes into account the variation of the co-salient object in different scenes. It distributes the consensus to the image feature maps in an image-specific way while making full use of interactions within the group. These two modules are integrated with a ViT encoder and an FPN-like decoder to form an end-to-end trainable network, without additional branch and auxiliary loss. The proposed method is evaluated on three commonly used CoSOD datasets and achieves state-of-the-art performance.