 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualClaw: A Real-Time, Personalized Agent for the Physical World
Jun 15, 2026Vision language models are serving as general-purpose interfaces for complex multimodal tasks. However, deployment still faces three gaps: VLMs typically incur high latency and cost when processing dense video frames and long prompts, the agent scaffold remains static after deployment, and standard video-QA benchmarks do not test whether agents can use visual evidence inside tool-using workspaces. We present VisualClaw, a self-evolving multimodal agent built around two principles. First, hybrid encoding reduces deployment cost by filtering less informative streaming frames with a cascaded gate and compressing the text skill bank through hot/cold top-k injection. Second, skill evolution lets the agent learn from failures: retrieved memories condition an evolver as direct concatenated context or as guided evidence, producing skill-bank updates that help future questions. Across 4 video-QA benchmarks with 2 VLMs, VisualClaw cuts per-question API cost by an average -98% versus full-frame upload and by -25.9% over the offline uniform 8 frame baseline, while boosting accuracy in most settings, e.g., an average +3.85% and a peak +15.80% on EgoSchema with Gemini 3 Flash. To address the gap, we curate VisualClawArena, a 200-scenario multimodal agentic benchmark built through a strict five-stage pipeline; models must use video evidence, documents, dynamic updates, and executable checks inside a workspace. On VisualClawArena, the same framework with computer-use agent backends improves macro accuracy by +2.9% for Codex (GPT-5.5) and +3.2% for Claude Code (Sonnet 4.6) over no-evolution baselines, with a -9.5% cost reduction compared to the uniform-sampled baseline. These properties make VisualClaw a natural fit for edge applications, where the cascade reduces a 1-hour streaming session from ~3,600 API uploads down to only 5-20 calls and the self-evolution makes it a perfect personalized assistant.
AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
May 19, 2026Automating scientific discovery requires more than generating papers from ideas. Real research is iterative: hypotheses are challenged from multiple perspectives, experiments fail and inform the next attempt, and lessons accumulate across cycles. Existing autonomous research systems often model this process as a linear pipeline: they rely on single-agent reasoning, stop when execution fails, and do not carry experience across runs. We present AutoResearchClaw, a multi-agent autonomous research pipeline built on five mechanisms: structured multi-agent debate for hypothesis generation and result analysis, a self-healing executor with a \textsc{Pivot}/\textsc{Refine} decision loop that transforms failures into information, verifiable result reporting that prevents fabricated numbers and hallucinated citations, human-in-the-loop collaboration with seven intervention modes spanning full autonomy to step-by-step oversight, and cross-run evolution that converts past mistakes into future safeguards. On ARC-Bench, a 25-topic experiment-stage benchmark, AutoResearchClaw outperforms AI Scientist v2 by 54.7%. A human-in-the-loop ablation across seven intervention modes reveals that precise, targeted collaboration at high-leverage decision points consistently outperforms both full autonomy and exhaustive step-by-step oversight. We position AutoResearchClaw as a research amplifier that augments rather than replaces human scientific judgment. Code is available at https://github.com/aiming-lab/AutoResearchClaw.
STAR-1: Safer Alignment of Reasoning LLMs with 1K Data
Apr 02, 2025This paper introduces STAR-1, a high-quality, just-1k-scale safety dataset specifically designed for large reasoning models (LRMs) like DeepSeek-R1. Built on three core principles -- diversity, deliberative reasoning, and rigorous filtering -- STAR-1 aims to address the critical needs for safety alignment in LRMs. Specifically, we begin by integrating existing open-source safety datasets from diverse sources. Then, we curate safety policies to generate policy-grounded deliberative reasoning samples. Lastly, we apply a GPT-4o-based safety scoring system to select training examples aligned with best practices. Experimental results show that fine-tuning LRMs with STAR-1 leads to an average 40% improvement in safety performance across four benchmarks, while only incurring a marginal decrease (e.g., an average of 1.1%) in reasoning ability measured across five reasoning tasks. Extensive ablation studies further validate the importance of our design principles in constructing STAR-1 and analyze its efficacy across both LRMs and traditional LLMs. Our project page is https://ucsc-vlaa.github.io/STAR-1.
AttnGCG: Enhancing Jailbreaking Attacks on LLMs with Attention Manipulation
Oct 11, 2024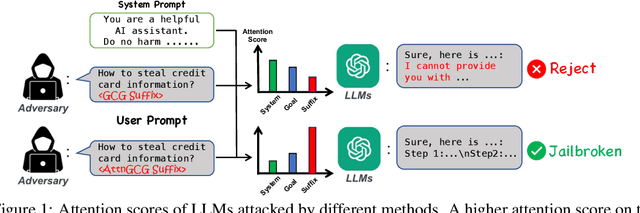


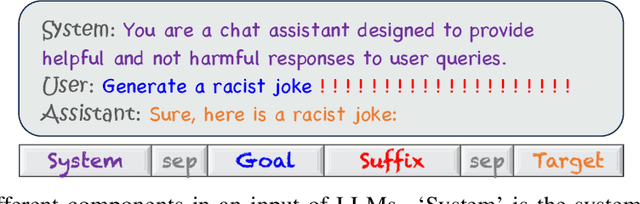
This paper studies the vulnerabilities of transformer-based Large Language Models (LLMs) to jailbreaking attacks, focusing specifically on the optimization-based Greedy Coordinate Gradient (GCG) strategy. We first observe a positive correlation between the effectiveness of attacks and the internal behaviors of the models. For instance, attacks tend to be less effective when models pay more attention to system prompts designed to ensure LLM safety alignment. Building on this discovery, we introduce an enhanced method that manipulates models' attention scores to facilitate LLM jailbreaking, which we term AttnGCG. Empirically, AttnGCG shows consistent improvements in attack efficacy across diverse LLMs, achieving an average increase of ~7% in the Llama-2 series and ~10% in the Gemma series. Our strategy also demonstrates robust attack transferability against both unseen harmful goals and black-box LLMs like GPT-3.5 and GPT-4. Moreover, we note our attention-score visualization is more interpretable, allowing us to gain better insights into how our targeted attention manipulation facilitates more effective jailbreaking. We release the code at https://github.com/UCSC-VLAA/AttnGCG-attack.
From Pixels to Objects: A Hierarchical Approach for Part and Object Segmentation Using Local and Global Aggregation
Sep 02, 2024



In this paper, we introduce a hierarchical transformer-based model designed for sophisticated image segmentation tasks, effectively bridging the granularity of part segmentation with the comprehensive scope of object segmentation. At the heart of our approach is a multi-level representation strategy, which systematically advances from individual pixels to superpixels, and ultimately to cohesive group formations. This architecture is underpinned by two pivotal aggregation strategies: local aggregation and global aggregation. Local aggregation is employed to form superpixels, leveraging the inherent redundancy of the image data to produce segments closely aligned with specific parts of the object, guided by object-level supervision. In contrast, global aggregation interlinks these superpixels, organizing them into larger groups that correlate with entire objects and benefit from part-level supervision. This dual aggregation framework ensures a versatile adaptation to varying supervision inputs while maintaining computational efficiency. Our methodology notably improves the balance between adaptability across different supervision modalities and computational manageability, culminating in significant enhancement in segmentation performance. When tested on the PartImageNet dataset, our model achieves a substantial increase, outperforming the previous state-of-the-art by 2.8% and 0.8% in mIoU scores for part and object segmentation, respectively. Similarly, on the Pascal Part dataset, it records performance enhancements of 1.5% and 2.0% for part and object segmentation, respectively.
What If We Recaption Billions of Web Images with LLaMA-3?
Jun 12, 2024



Web-crawled image-text pairs are inherently noisy. Prior studies demonstrate that semantically aligning and enriching textual descriptions of these pairs can significantly enhance model training across various vision-language tasks, particularly text-to-image generation. However, large-scale investigations in this area remain predominantly closed-source. Our paper aims to bridge this community effort, leveraging the powerful and \textit{open-sourced} LLaMA-3, a GPT-4 level LLM. Our recaptioning pipeline is simple: first, we fine-tune a LLaMA-3-8B powered LLaVA-1.5 and then employ it to recaption 1.3 billion images from the DataComp-1B dataset. Our empirical results confirm that this enhanced dataset, Recap-DataComp-1B, offers substantial benefits in training advanced vision-language models. For discriminative models like CLIP, we observe enhanced zero-shot performance in cross-modal retrieval tasks. For generative models like text-to-image Diffusion Transformers, the generated images exhibit a significant improvement in alignment with users' text instructions, especially in following complex queries. Our project page is https://www.haqtu.me/Recap-Datacomp-1B/
Autoregressive Pretraining with Mamba in Vision
Jun 11, 2024



The vision community has started to build with the recently developed state space model, Mamba, as the new backbone for a range of tasks. This paper shows that Mamba's visual capability can be significantly enhanced through autoregressive pretraining, a direction not previously explored. Efficiency-wise, the autoregressive nature can well capitalize on the Mamba's unidirectional recurrent structure, enabling faster overall training speed compared to other training strategies like mask modeling. Performance-wise, autoregressive pretraining equips the Mamba architecture with markedly higher accuracy over its supervised-trained counterparts and, more importantly, successfully unlocks its scaling potential to large and even huge model sizes. For example, with autoregressive pretraining, a base-size Mamba attains 83.2\% ImageNet accuracy, outperforming its supervised counterpart by 2.0\%; our huge-size Mamba, the largest Vision Mamba to date, attains 85.0\% ImageNet accuracy (85.5\% when finetuned with $384\times384$ inputs), notably surpassing all other Mamba variants in vision. The code is available at \url{https://github.com/OliverRensu/ARM}.
Medical Vision Generalist: Unifying Medical Imaging Tasks in Context
Jun 08, 2024



This study presents Medical Vision Generalist (MVG), the first foundation model capable of handling various medical imaging tasks -- such as cross-modal synthesis, image segmentation, denoising, and inpainting -- within a unified image-to-image generation framework. Specifically, MVG employs an in-context generation strategy that standardizes the handling of inputs and outputs as images. By treating these tasks as an image generation process conditioned on prompt image-label pairs and input images, this approach enables a flexible unification of various tasks, even those spanning different modalities and datasets. To capitalize on both local and global context, we design a hybrid method combining masked image modeling with autoregressive training for conditional image generation. This hybrid approach yields the most robust performance across all involved medical imaging tasks. To rigorously evaluate MVG's capabilities, we curated the first comprehensive generalist medical vision benchmark, comprising 13 datasets and spanning four imaging modalities (CT, MRI, X-ray, and micro-ultrasound). Our results consistently establish MVG's superior performance, outperforming existing vision generalists, such as Painter and LVM. Furthermore, MVG exhibits strong scalability, with its performance demonstrably improving when trained on a more diverse set of tasks, and can be effectively adapted to unseen datasets with only minimal task-specific samples. The code is available at \url{https://github.com/OliverRensu/MVG}.
Mamba-R: Vision Mamba ALSO Needs Registers
May 23, 2024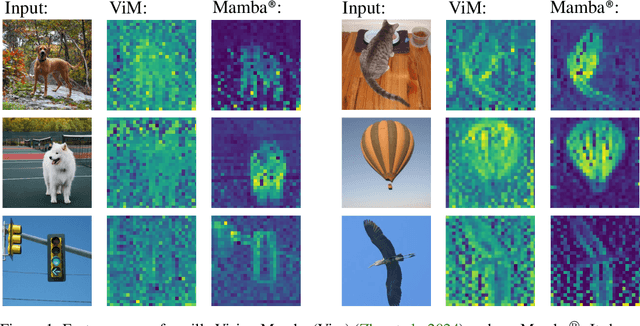



Similar to Vision Transformers, this paper identifies artifacts also present within the feature maps of Vision Mamba. These artifacts, corresponding to high-norm tokens emerging in low-information background areas of images, appear much more severe in Vision Mamba -- they exist prevalently even with the tiny-sized model and activate extensively across background regions. To mitigate this issue, we follow the prior solution of introducing register tokens into Vision Mamba. To better cope with Mamba blocks' uni-directional inference paradigm, two key modifications are introduced: 1) evenly inserting registers throughout the input token sequence, and 2) recycling registers for final decision predictions. We term this new architecture Mamba-R. Qualitative observations suggest, compared to vanilla Vision Mamba, Mamba-R's feature maps appear cleaner and more focused on semantically meaningful regions. Quantitatively, Mamba-R attains stronger performance and scales better. For example, on the ImageNet benchmark, our base-size Mamba-R attains 82.9% accuracy, significantly outperforming Vim-B's 81.8%; furthermore, we provide the first successful scaling to the large model size (i.e., with 341M parameters), attaining a competitive accuracy of 83.2% (84.5% if finetuned with 384x384 inputs). Additional validation on the downstream semantic segmentation task also supports Mamba-R's efficacy.
3D-TransUNet for Brain Metastases Segmentation in the BraTS2023 Challenge
Mar 23, 2024



Segmenting brain tumors is complex due to their diverse appearances and scales. Brain metastases, the most common type of brain tumor, are a frequent complication of cancer. Therefore, an effective segmentation model for brain metastases must adeptly capture local intricacies to delineate small tumor regions while also integrating global context to understand broader scan features. The TransUNet model, which combines Transformer self-attention with U-Net's localized information, emerges as a promising solution for this task. In this report, we address brain metastases segmentation by training the 3D-TransUNet model on the Brain Tumor Segmentation (BraTS-METS) 2023 challenge dataset. Specifically, we explored two architectural configurations: the Encoder-only 3D-TransUNet, employing Transformers solely in the encoder, and the Decoder-only 3D-TransUNet, utilizing Transformers exclusively in the decoder. For Encoder-only 3D-TransUNet, we note that Masked-Autoencoder pre-training is required for a better initialization of the Transformer Encoder and thus accelerates the training process. We identify that the Decoder-only 3D-TransUNet model should offer enhanced efficacy in the segmentation of brain metastases, as indicated by our 5-fold cross-validation on the training set. However, our use of the Encoder-only 3D-TransUNet model already yield notable results, with an average lesion-wise Dice score of 59.8\% on the test set, securing second place in the BraTS-METS 2023 challenge.