 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Apr 27, 2026Unified multimodal models typically rely on pretrained vision encoders and use separate visual representations for understanding and generation, creating misalignment between the two tasks and preventing fully end-to-end optimization from raw pixels. We introduce Tuna-2, a native unified multimodal model that performs visual understanding and generation directly based on pixel embeddings. Tuna-2 drastically simplifies the model architecture by employing simple patch embedding layers to encode visual input, completely discarding the modular vision encoder designs such as the VAE or the representation encoder. Experiments show that Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modelling can fully compete with latent-space approaches for high-quality image generation. Moreover, while the encoder-based variant converges faster in early pretraining, Tuna-2's encoder-free design achieves stronger multimodal understanding at scale, particularly on tasks requiring fine-grained visual perception. These results show that pretrained vision encoders are not necessary for multimodal modelling, and end-to-end pixel-space learning offers a scalable path toward stronger visual representations for both generation and perception.
VecGlypher: Unified Vector Glyph Generation with Language Models
Feb 25, 2026Vector glyphs are the atomic units of digital typography, yet most learning-based pipelines still depend on carefully curated exemplar sheets and raster-to-vector postprocessing, which limits accessibility and editability. We introduce VecGlypher, a single multimodal language model that generates high-fidelity vector glyphs directly from text descriptions or image exemplars. Given a style prompt, optional reference glyph images, and a target character, VecGlypher autoregressively emits SVG path tokens, avoiding raster intermediates and producing editable, watertight outlines in one pass. A typography-aware data and training recipe makes this possible: (i) a large-scale continuation stage on 39K noisy Envato fonts to master SVG syntax and long-horizon geometry, followed by (ii) post-training on 2.5K expert-annotated Google Fonts with descriptive tags and exemplars to align language and imagery with geometry; preprocessing normalizes coordinate frames, canonicalizes paths, de-duplicates families, and quantizes coordinates for stable long-sequence decoding. On cross-family OOD evaluation, VecGlypher substantially outperforms both general-purpose LLMs and specialized vector-font baselines for text-only generation, while image-referenced generation reaches a state-of-the-art performance, with marked gains over DeepVecFont-v2 and DualVector. Ablations show that model scale and the two-stage recipe are critical and that absolute-coordinate serialization yields the best geometry. VecGlypher lowers the barrier to font creation by letting users design with words or exemplars, and provides a scalable foundation for future multimodal design tools.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
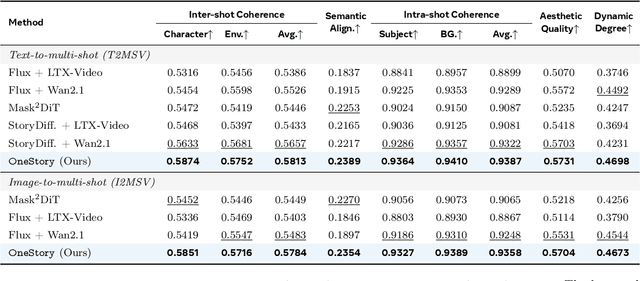
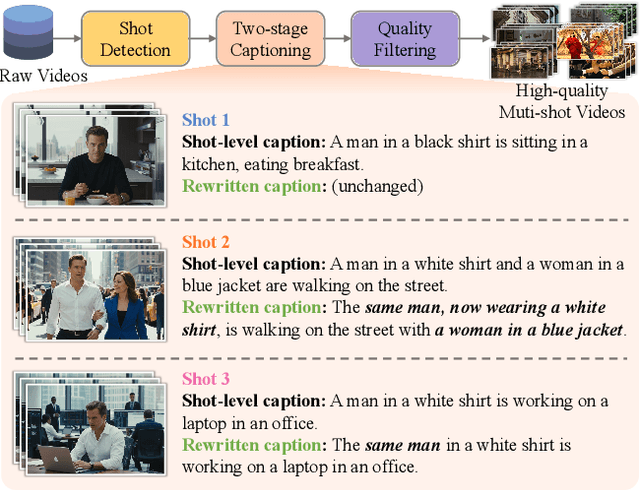

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
MedVLSynther: Synthesizing High-Quality Visual Question Answering from Medical Documents with Generator-Verifier LMMs
Oct 29, 2025Large Multimodal Models (LMMs) are increasingly capable of answering medical questions that require joint reasoning over images and text, yet training general medical VQA systems is impeded by the lack of large, openly usable, high-quality corpora. We present MedVLSynther, a rubric-guided generator-verifier framework that synthesizes high-quality multiple-choice VQA items directly from open biomedical literature by conditioning on figures, captions, and in-text references. The generator produces self-contained stems and parallel, mutually exclusive options under a machine-checkable JSON schema; a multi-stage verifier enforces essential gates (self-containment, single correct answer, clinical validity, image-text consistency), awards fine-grained positive points, and penalizes common failure modes before acceptance. Applying this pipeline to PubMed Central yields MedSynVQA: 13,087 audited questions over 14,803 images spanning 13 imaging modalities and 28 anatomical regions. Training open-weight LMMs with reinforcement learning using verifiable rewards improves accuracy across six medical VQA benchmarks, achieving averages of 55.85 (3B) and 58.15 (7B), with up to 77.57 on VQA-RAD and 67.76 on PathVQA, outperforming strong medical LMMs. A Ablations verify that both generation and verification are necessary and that more verified data consistently helps, and a targeted contamination analysis detects no leakage from evaluation suites. By operating entirely on open literature and open-weight models, MedVLSynther offers an auditable, reproducible, and privacy-preserving path to scalable medical VQA training data.
m1: Unleash the Potential of Test-Time Scaling for Medical Reasoning with Large Language Models
Apr 01, 2025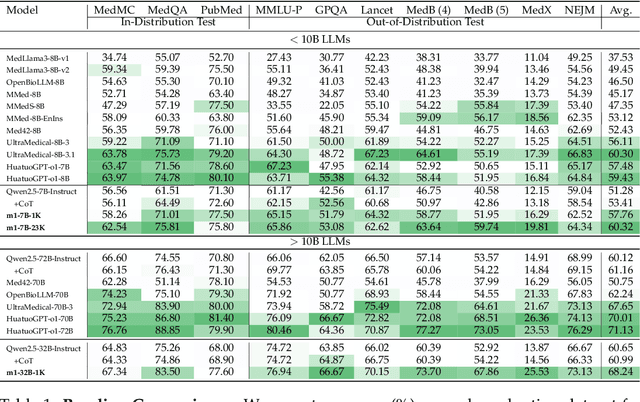
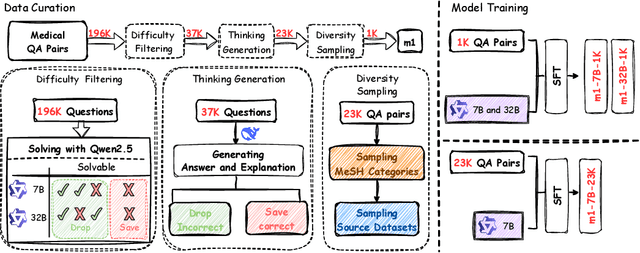
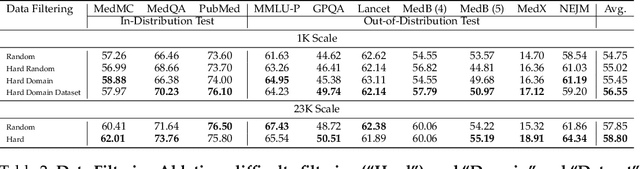
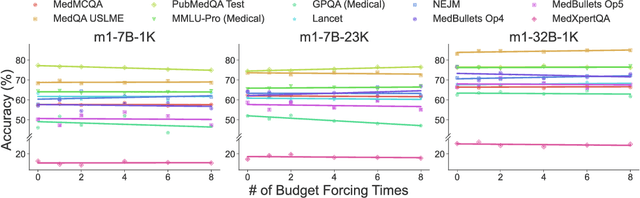
Test-time scaling has emerged as a powerful technique for enhancing the reasoning capabilities of large language models. However, its effectiveness in medical reasoning remains uncertain, as the medical domain fundamentally differs from mathematical tasks in terms of knowledge representation and decision-making processes. In this paper, we provide the first comprehensive investigation of test-time scaling for medical reasoning and present m1, a simple yet effective approach that increases a model's medical reasoning capability at inference. Our evaluation across diverse medical tasks demonstrates that test-time scaling consistently enhances medical reasoning, enabling lightweight fine-tuned models under 10B parameters to establish new state-of-the-art performance, while our 32B model rivals previous 70B-scale medical LLMs. However, we identify an optimal reasoning token budget of approximately 4K, beyond which performance may degrade due to overthinking. Budget forcing, which extends test-time computation through iterative prompts, helps models double-check answers but does not necessarily improve the overall medical QA performance and, in some cases, even introduces errors into previously correct responses. Our case-by-case analysis identifies insufficient medical knowledge as a key bottleneck that prevents further performance gains through test-time scaling. We find that increasing data scale, improving data quality, and expanding model capacity consistently enhance medical knowledge grounding, enabling continued performance improvements, particularly on challenging medical benchmarks where smaller models reach saturation. These findings underscore fundamental differences between medical and mathematical reasoning in LLMs, highlighting that enriched medical knowledge, other than increased reasoning depth alone, is essential for realizing the benefits of test-time scaling.
Story-Adapter: A Training-free Iterative Framework for Long Story Visualization
Oct 08, 2024



Story visualization, the task of generating coherent images based on a narrative, has seen significant advancements with the emergence of text-to-image models, particularly diffusion models. However, maintaining semantic consistency, generating high-quality fine-grained interactions, and ensuring computational feasibility remain challenging, especially in long story visualization (i.e., up to 100 frames). In this work, we propose a training-free and computationally efficient framework, termed Story-Adapter, to enhance the generative capability of long stories. Specifically, we propose an iterative paradigm to refine each generated image, leveraging both the text prompt and all generated images from the previous iteration. Central to our framework is a training-free global reference cross-attention module, which aggregates all generated images from the previous iteration to preserve semantic consistency across the entire story, while minimizing computational costs with global embeddings. This iterative process progressively optimizes image generation by repeatedly incorporating text constraints, resulting in more precise and fine-grained interactions. Extensive experiments validate the superiority of Story-Adapter in improving both semantic consistency and generative capability for fine-grained interactions, particularly in long story scenarios. The project page and associated code can be accessed via https://jwmao1.github.io/storyadapter .
VoCo-LLaMA: Towards Vision Compression with Large Language Models
Jun 18, 2024



Vision-Language Models (VLMs) have achieved remarkable success in various multi-modal tasks, but they are often bottlenecked by the limited context window and high computational cost of processing high-resolution image inputs and videos. Vision compression can alleviate this problem by reducing the vision token count. Previous approaches compress vision tokens with external modules and force LLMs to understand the compressed ones, leading to visual information loss. However, the LLMs' understanding paradigm of vision tokens is not fully utilised in the compression learning process. We propose VoCo-LLaMA, the first approach to compress vision tokens using LLMs. By introducing Vision Compression tokens during the vision instruction tuning phase and leveraging attention distillation, our method distill how LLMs comprehend vision tokens into their processing of VoCo tokens. VoCo-LLaMA facilitates effective vision compression and improves the computational efficiency during the inference stage. Specifically, our method achieves minimal performance loss with a compression ratio of 576$\times$, resulting in up to 94.8$\%$ fewer FLOPs and 69.6$\%$ acceleration in inference time. Furthermore, through continuous training using time-series compressed token sequences of video frames, VoCo-LLaMA demonstrates the ability to understand temporal correlations, outperforming previous methods on popular video question-answering benchmarks. Our approach presents a promising way to unlock the full potential of VLMs' contextual window, enabling more scalable multi-modal applications. The project page, along with the associated code, can be accessed via $\href{https://yxxxb.github.io/VoCo-LLaMA-page/}{\text{this https URL}}$.
Medical Vision Generalist: Unifying Medical Imaging Tasks in Context
Jun 08, 2024



This study presents Medical Vision Generalist (MVG), the first foundation model capable of handling various medical imaging tasks -- such as cross-modal synthesis, image segmentation, denoising, and inpainting -- within a unified image-to-image generation framework. Specifically, MVG employs an in-context generation strategy that standardizes the handling of inputs and outputs as images. By treating these tasks as an image generation process conditioned on prompt image-label pairs and input images, this approach enables a flexible unification of various tasks, even those spanning different modalities and datasets. To capitalize on both local and global context, we design a hybrid method combining masked image modeling with autoregressive training for conditional image generation. This hybrid approach yields the most robust performance across all involved medical imaging tasks. To rigorously evaluate MVG's capabilities, we curated the first comprehensive generalist medical vision benchmark, comprising 13 datasets and spanning four imaging modalities (CT, MRI, X-ray, and micro-ultrasound). Our results consistently establish MVG's superior performance, outperforming existing vision generalists, such as Painter and LVM. Furthermore, MVG exhibits strong scalability, with its performance demonstrably improving when trained on a more diverse set of tasks, and can be effectively adapted to unseen datasets with only minimal task-specific samples. The code is available at \url{https://github.com/OliverRensu/MVG}.
Segment and Caption Anything
Dec 01, 2023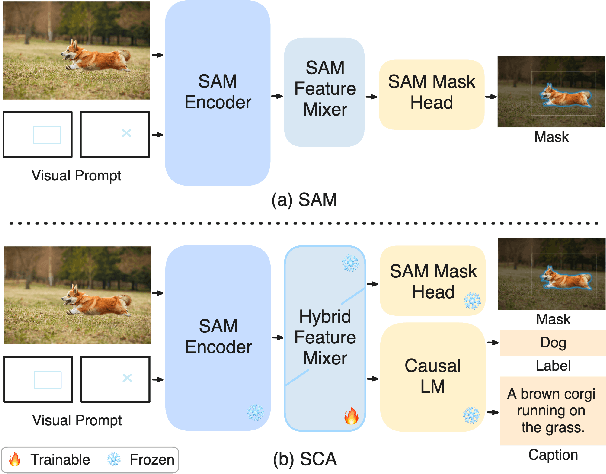
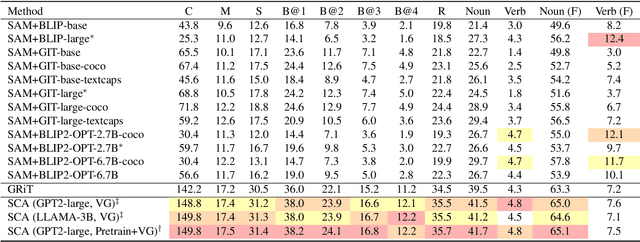
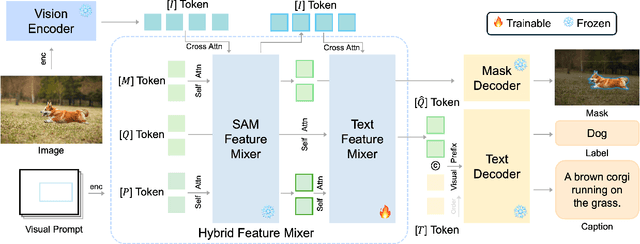
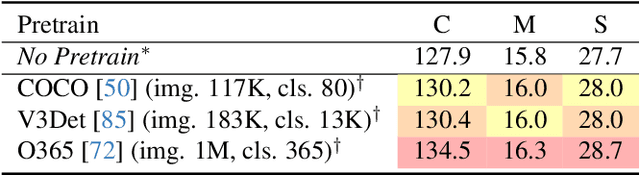
We propose a method to efficiently equip the Segment Anything Model (SAM) with the ability to generate regional captions. SAM presents strong generalizability to segment anything while is short for semantic understanding. By introducing a lightweight query-based feature mixer, we align the region-specific features with the embedding space of language models for later caption generation. As the number of trainable parameters is small (typically in the order of tens of millions), it costs less computation, less memory usage, and less communication bandwidth, resulting in both fast and scalable training. To address the scarcity problem of regional caption data, we propose to first pre-train our model on objection detection and segmentation tasks. We call this step weak supervision pretraining since the pre-training data only contains category names instead of full-sentence descriptions. The weak supervision pretraining allows us to leverage many publicly available object detection and segmentation datasets. We conduct extensive experiments to demonstrate the superiority of our method and validate each design choice. This work serves as a stepping stone towards scaling up regional captioning data and sheds light on exploring efficient ways to augment SAM with regional semantics. The project page, along with the associated code, can be accessed via the following https://xk-huang.github.io/segment-caption-anything/.
Exploring Multimodal Approaches for Alzheimer's Disease Detection Using Patient Speech Transcript and Audio Data
Jul 05, 2023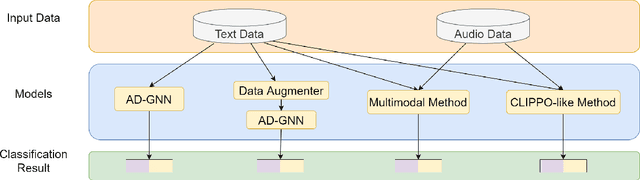

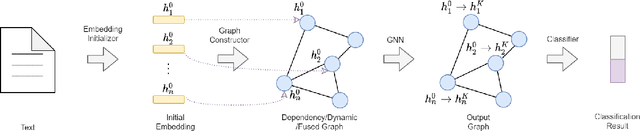
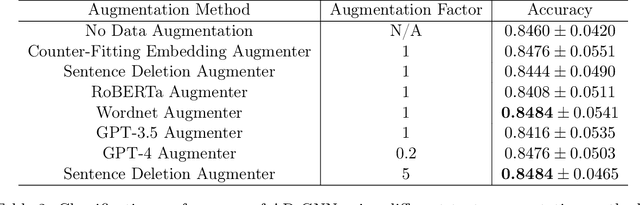
Alzheimer's disease (AD) is a common form of dementia that severely impacts patient health. As AD impairs the patient's language understanding and expression ability, the speech of AD patients can serve as an indicator of this disease. This study investigates various methods for detecting AD using patients' speech and transcripts data from the DementiaBank Pitt database. The proposed approach involves pre-trained language models and Graph Neural Network (GNN) that constructs a graph from the speech transcript, and extracts features using GNN for AD detection. Data augmentation techniques, including synonym replacement, GPT-based augmenter, and so on, were used to address the small dataset size. Audio data was also introduced, and WavLM model was used to extract audio features. These features were then fused with text features using various methods. Finally, a contrastive learning approach was attempted by converting speech transcripts back to audio and using it for contrastive learning with the original audio. We conducted intensive experiments and analysis on the above methods. Our findings shed light on the challenges and potential solutions in AD detection using speech and audio data.