 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunduSAM: A Specialized Deep Learning Model for Enhanced Optic Disc and Cup Segmentation in Fundus Images
Feb 10, 2025The Segment Anything Model (SAM) has gained popularity as a versatile image segmentation method, thanks to its strong generalization capabilities across various domains. However, when applied to optic disc (OD) and optic cup (OC) segmentation tasks, SAM encounters challenges due to the complex structures, low contrast, and blurred boundaries typical of fundus images, leading to suboptimal performance. To overcome these challenges, we introduce a novel model, FunduSAM, which incorporates several Adapters into SAM to create a deep network specifically designed for OD and OC segmentation. The FunduSAM utilizes Adapter into each transformer block after encoder for parameter fine-tuning (PEFT). It enhances SAM's feature extraction capabilities by designing a Convolutional Block Attention Module (CBAM), addressing issues related to blurred boundaries and low contrast. Given the unique requirements of OD and OC segmentation, polar transformation is used to convert the original fundus OD images into a format better suited for training and evaluating FunduSAM. A joint loss is used to achieve structure preservation between the OD and OC, while accurate segmentation. Extensive experiments on the REFUGE dataset, comprising 1,200 fundus images, demonstrate the superior performance of FunduSAM compared to five mainstream approaches.
Reasoning before Comparison: LLM-Enhanced Semantic Similarity Metrics for Domain Specialized Text Analysis
Feb 20, 2024



In this study, we leverage LLM to enhance the semantic analysis and develop similarity metrics for texts, addressing the limitations of traditional unsupervised NLP metrics like ROUGE and BLEU. We develop a framework where LLMs such as GPT-4 are employed for zero-shot text identification and label generation for radiology reports, where the labels are then used as measurements for text similarity. By testing the proposed framework on the MIMIC data, we find that GPT-4 generated labels can significantly improve the semantic similarity assessment, with scores more closely aligned with clinical ground truth than traditional NLP metrics. Our work demonstrates the possibility of conducting semantic analysis of the text data using semi-quantitative reasoning results by the LLMs for highly specialized domains. While the framework is implemented for radiology report similarity analysis, its concept can be extended to other specialized domains as well.
The Radiation Oncology NLP Database
Jan 19, 2024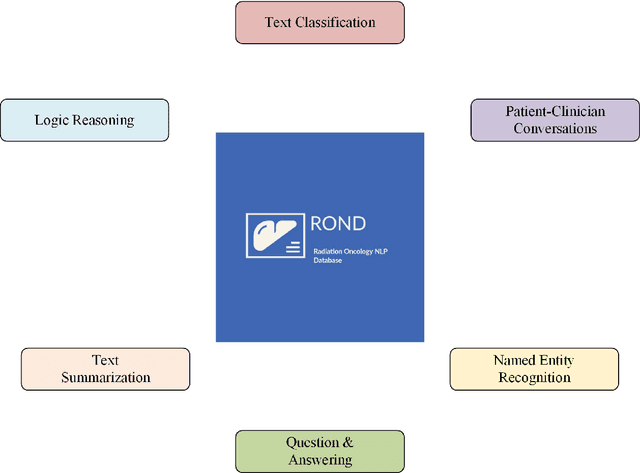


We present the Radiation Oncology NLP Database (ROND), the first dedicated Natural Language Processing (NLP) dataset for radiation oncology, an important medical specialty that has received limited attention from the NLP community in the past. With the advent of Artificial General Intelligence (AGI), there is an increasing need for specialized datasets and benchmarks to facilitate research and development. ROND is specifically designed to address this gap in the domain of radiation oncology, a field that offers many opportunities for NLP exploration. It encompasses various NLP tasks including Logic Reasoning, Text Classification, Named Entity Recognition (NER), Question Answering (QA), Text Summarization, and Patient-Clinician Conversations, each with a distinct focus on radiation oncology concepts and application cases. In addition, we have developed an instruction-tuning dataset consisting of over 20k instruction pairs (based on ROND) and trained a large language model, CancerChat. This serves to demonstrate the potential of instruction-tuning large language models within a highly-specialized medical domain. The evaluation results in this study could serve as baseline results for future research. ROND aims to stimulate advancements in radiation oncology and clinical NLP by offering a platform for testing and improving algorithms and models in a domain-specific context. The ROND dataset is a joint effort of multiple U.S. health institutions. The data is available at https://github.com/zl-liu/Radiation-Oncology-NLP-Database.
Exploring Multimodal Approaches for Alzheimer's Disease Detection Using Patient Speech Transcript and Audio Data
Jul 05, 2023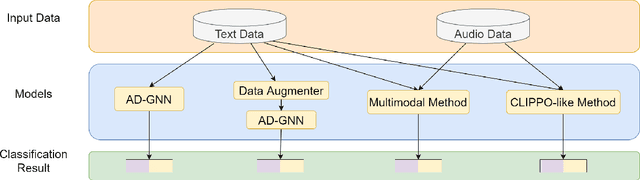

Alzheimer's disease (AD) is a common form of dementia that severely impacts patient health. As AD impairs the patient's language understanding and expression ability, the speech of AD patients can serve as an indicator of this disease. This study investigates various methods for detecting AD using patients' speech and transcripts data from the DementiaBank Pitt database. The proposed approach involves pre-trained language models and Graph Neural Network (GNN) that constructs a graph from the speech transcript, and extracts features using GNN for AD detection. Data augmentation techniques, including synonym replacement, GPT-based augmenter, and so on, were used to address the small dataset size. Audio data was also introduced, and WavLM model was used to extract audio features. These features were then fused with text features using various methods. Finally, a contrastive learning approach was attempted by converting speech transcripts back to audio and using it for contrastive learning with the original audio. We conducted intensive experiments and analysis on the above methods. Our findings shed light on the challenges and potential solutions in AD detection using speech and audio data.
Differentiate ChatGPT-generated and Human-written Medical Texts
Apr 23, 2023



Background: Large language models such as ChatGPT are capable of generating grammatically perfect and human-like text content, and a large number of ChatGPT-generated texts have appeared on the Internet. However, medical texts such as clinical notes and diagnoses require rigorous validation, and erroneous medical content generated by ChatGPT could potentially lead to disinformation that poses significant harm to healthcare and the general public. Objective: This research is among the first studies on responsible and ethical AIGC (Artificial Intelligence Generated Content) in medicine. We focus on analyzing the differences between medical texts written by human experts and generated by ChatGPT, and designing machine learning workflows to effectively detect and differentiate medical texts generated by ChatGPT. Methods: We first construct a suite of datasets containing medical texts written by human experts and generated by ChatGPT. In the next step, we analyze the linguistic features of these two types of content and uncover differences in vocabulary, part-of-speech, dependency, sentiment, perplexity, etc. Finally, we design and implement machine learning methods to detect medical text generated by ChatGPT. Results: Medical texts written by humans are more concrete, more diverse, and typically contain more useful information, while medical texts generated by ChatGPT pay more attention to fluency and logic, and usually express general terminologies rather than effective information specific to the context of the problem. A BERT-based model can effectively detect medical texts generated by ChatGPT, and the F1 exceeds 95%.
AugGPT: Leveraging ChatGPT for Text Data Augmentation
Mar 20, 2023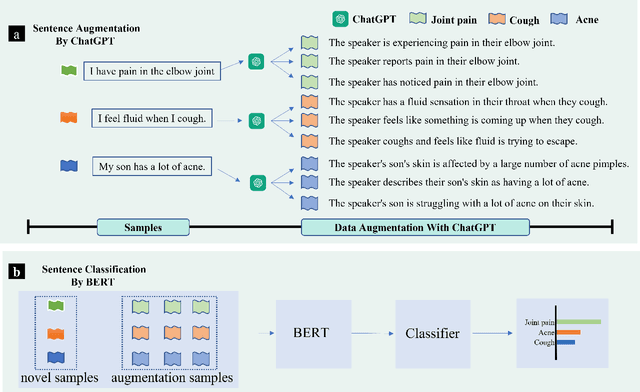
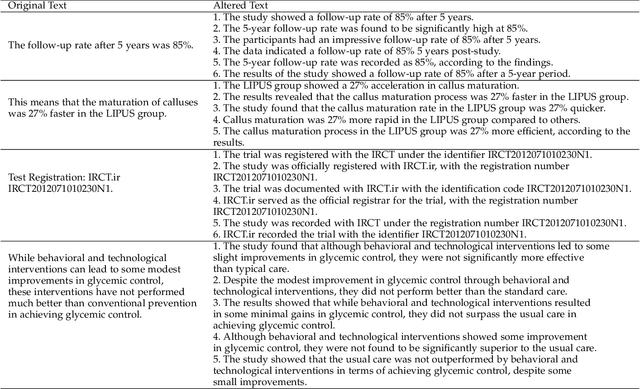
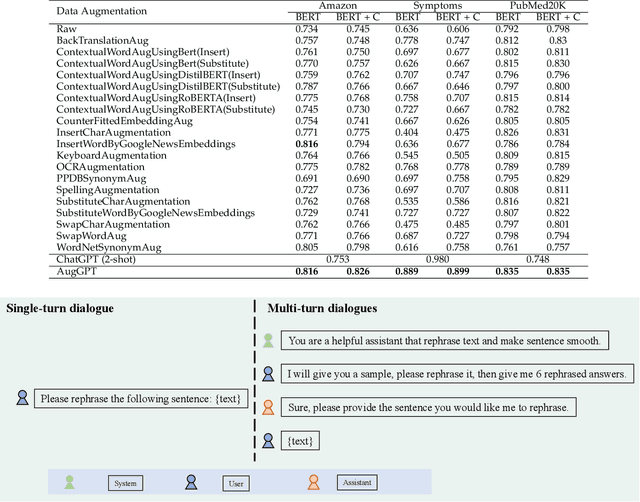
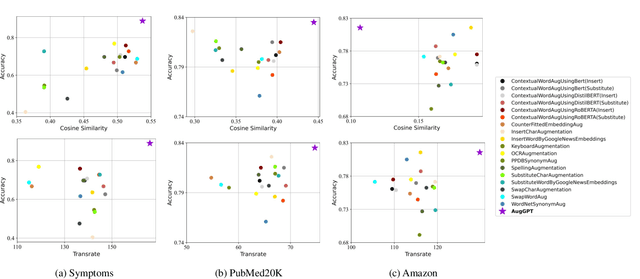
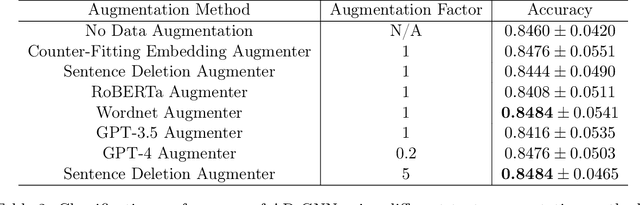
Text data augmentation is an effective strategy for overcoming the challenge of limited sample sizes in many natural language processing (NLP) tasks. This challenge is especially prominent in the few-shot learning scenario, where the data in the target domain is generally much scarcer and of lowered quality. A natural and widely-used strategy to mitigate such challenges is to perform data augmentation to better capture the data invariance and increase the sample size. However, current text data augmentation methods either can't ensure the correct labeling of the generated data (lacking faithfulness) or can't ensure sufficient diversity in the generated data (lacking compactness), or both. Inspired by the recent success of large language models, especially the development of ChatGPT, which demonstrated improved language comprehension abilities, in this work, we propose a text data augmentation approach based on ChatGPT (named AugGPT). AugGPT rephrases each sentence in the training samples into multiple conceptually similar but semantically different samples. The augmented samples can then be used in downstream model training. Experiment results on few-shot learning text classification tasks show the superior performance of the proposed AugGPT approach over state-of-the-art text data augmentation methods in terms of testing accuracy and distribution of the augmented samples.
Mask-guided BERT for Few Shot Text Classification
Mar 09, 2023Transformer-based language models have achieved significant success in various domains. However, the data-intensive nature of the transformer architecture requires much labeled data, which is challenging in low-resource scenarios (i.e., few-shot learning (FSL)). The main challenge of FSL is the difficulty of training robust models on small amounts of samples, which frequently leads to overfitting. Here we present Mask-BERT, a simple and modular framework to help BERT-based architectures tackle FSL. The proposed approach fundamentally differs from existing FSL strategies such as prompt tuning and meta-learning. The core idea is to selectively apply masks on text inputs and filter out irrelevant information, which guides the model to focus on discriminative tokens that influence prediction results. In addition, to make the text representations from different categories more separable and the text representations from the same category more compact, we introduce a contrastive learning loss function. Experimental results on public-domain benchmark datasets demonstrate the effectiveness of Mask-BERT.
Coarse-to-fine Knowledge Graph Domain Adaptation based on Distantly-supervised Iterative Training
Nov 05, 2022Modern supervised learning neural network models require a large amount of manually labeled data, which makes the construction of domain-specific knowledge graphs time-consuming and labor-intensive. In parallel, although there has been much research on named entity recognition and relation extraction based on distantly supervised learning, constructing a domain-specific knowledge graph from large collections of textual data without manual annotations is still an urgent problem to be solved. In response, we propose an integrated framework for adapting and re-learning knowledge graphs from one coarse domain (biomedical) to a finer-define domain (oncology). In this framework, we apply distant-supervision on cross-domain knowledge graph adaptation. Consequently, no manual data annotation is required to train the model. We introduce a novel iterative training strategy to facilitate the discovery of domain-specific named entities and triples. Experimental results indicate that the proposed framework can perform domain adaptation and construction of knowledge graph efficiently.
Joint Intent Detection and Slot Filling with Wheel-Graph Attention Networks
Feb 09, 2021
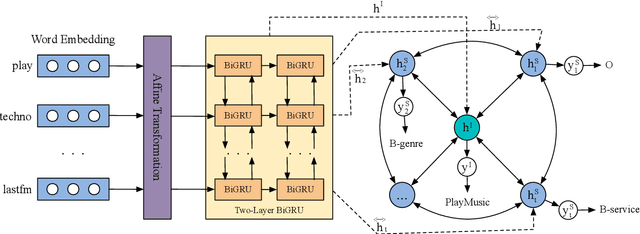
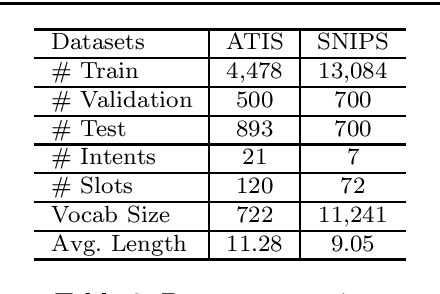

Intent detection and slot filling are two fundamental tasks for building a spoken language understanding (SLU) system. Multiple deep learning-based joint models have demonstrated excellent results on the two tasks. In this paper, we propose a new joint model with a wheel-graph attention network (Wheel-GAT) which is able to model interrelated connections directly for intent detection and slot filling. To construct a graph structure for utterances, we create intent nodes, slot nodes, and directed edges. Intent nodes can provide utterance-level semantic information for slot filling, while slot nodes can also provide local keyword information for intent. Experiments show that our model outperforms multiple baselines on two public datasets. Besides, we also demonstrate that using Bidirectional Encoder Representation from Transformer (BERT) model further boosts the performance in the SLU task.