 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAR-TVG: Enhancing VLMs with Timestamp Anchor-Constrained Reasoning for Temporal Video Grounding
Aug 11, 2025Temporal Video Grounding (TVG) aims to precisely localize video segments corresponding to natural language queries, which is a critical capability for long-form video understanding. Although existing reinforcement learning approaches encourage models to generate reasoning chains before predictions, they fail to explicitly constrain the reasoning process to ensure the quality of the final temporal predictions. To address this limitation, we propose Timestamp Anchor-constrained Reasoning for Temporal Video Grounding (TAR-TVG), a novel framework that introduces timestamp anchors within the reasoning process to enforce explicit supervision to the thought content. These anchors serve as intermediate verification points. More importantly, we require each reasoning step to produce increasingly accurate temporal estimations, thereby ensuring that the reasoning process contributes meaningfully to the final prediction. To address the challenge of low-probability anchor generation in models (e.g., Qwen2.5-VL-3B), we develop an efficient self-distillation training strategy: (1) initial GRPO training to collect 30K high-quality reasoning traces containing multiple timestamp anchors, (2) supervised fine-tuning (SFT) on distilled data, and (3) final GRPO optimization on the SFT-enhanced model. This three-stage training strategy enables robust anchor generation while maintaining reasoning quality. Experiments show that our model achieves state-of-the-art performance while producing interpretable, verifiable reasoning chains with progressively refined temporal estimations.
Invert4TVG: A Temporal Video Grounding Framework with Inversion Tasks for Enhanced Action Understanding
Aug 10, 2025Temporal Video Grounding (TVG) seeks to localize video segments matching a given textual query. Current methods, while optimizing for high temporal Intersection-over-Union (IoU), often overfit to this metric, compromising semantic action understanding in the video and query, a critical factor for robust TVG. To address this, we introduce Inversion Tasks for TVG (Invert4TVG), a novel framework that enhances both localization accuracy and action understanding without additional data. Our approach leverages three inversion tasks derived from existing TVG annotations: (1) Verb Completion, predicting masked action verbs in queries from video segments; (2) Action Recognition, identifying query-described actions; and (3) Video Description, generating descriptions of video segments that explicitly embed query-relevant actions. These tasks, integrated with TVG via a reinforcement learning framework with well-designed reward functions, ensure balanced optimization of localization and semantics. Experiments show our method outperforms state-of-the-art approaches, achieving a 7.1\% improvement in R1@0.7 on Charades-STA for a 3B model compared to Time-R1. By inverting TVG to derive query-related actions from segments, our approach strengthens semantic understanding, significantly raising the ceiling of localization accuracy.
EOOD: Entropy-based Out-of-distribution Detection
Apr 04, 2025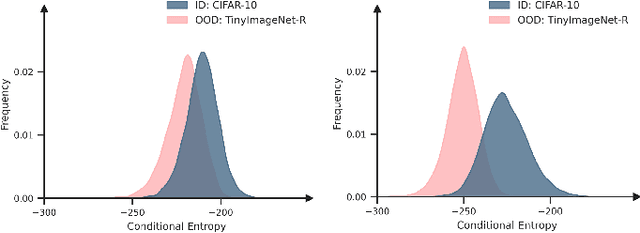
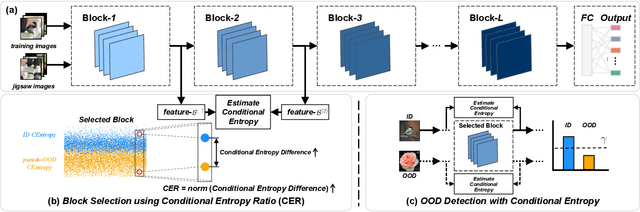
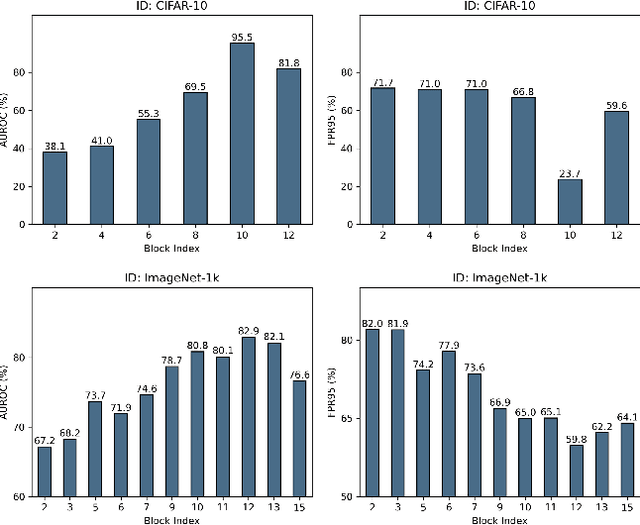
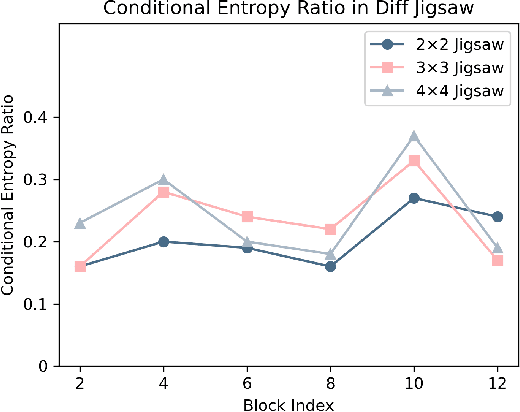
Deep neural networks (DNNs) often exhibit overconfidence when encountering out-of-distribution (OOD) samples, posing significant challenges for deployment. Since DNNs are trained on in-distribution (ID) datasets, the information flow of ID samples through DNNs inevitably differs from that of OOD samples. In this paper, we propose an Entropy-based Out-Of-distribution Detection (EOOD) framework. EOOD first identifies specific block where the information flow differences between ID and OOD samples are more pronounced, using both ID and pseudo-OOD samples. It then calculates the conditional entropy on the selected block as the OOD confidence score. Comprehensive experiments conducted across various ID and OOD settings demonstrate the effectiveness of EOOD in OOD detection and its superiority over state-of-the-art methods.
RecDreamer: Consistent Text-to-3D Generation via Uniform Score Distillation
Feb 18, 2025Current text-to-3D generation methods based on score distillation often suffer from geometric inconsistencies, leading to repeated patterns across different poses of 3D assets. This issue, known as the Multi-Face Janus problem, arises because existing methods struggle to maintain consistency across varying poses and are biased toward a canonical pose. While recent work has improved pose control and approximation, these efforts are still limited by this inherent bias, which skews the guidance during generation. To address this, we propose a solution called RecDreamer, which reshapes the underlying data distribution to achieve a more consistent pose representation. The core idea behind our method is to rectify the prior distribution, ensuring that pose variation is uniformly distributed rather than biased toward a canonical form. By modifying the prescribed distribution through an auxiliary function, we can reconstruct the density of the distribution to ensure compliance with specific marginal constraints. In particular, we ensure that the marginal distribution of poses follows a uniform distribution, thereby eliminating the biases introduced by the prior knowledge. We incorporate this rectified data distribution into existing score distillation algorithms, a process we refer to as uniform score distillation. To efficiently compute the posterior distribution required for the auxiliary function, RecDreamer introduces a training-free classifier that estimates pose categories in a plug-and-play manner. Additionally, we utilize various approximation techniques for noisy states, significantly improving system performance. Our experimental results demonstrate that RecDreamer effectively mitigates the Multi-Face Janus problem, leading to more consistent 3D asset generation across different poses.
FunduSAM: A Specialized Deep Learning Model for Enhanced Optic Disc and Cup Segmentation in Fundus Images
Feb 10, 2025The Segment Anything Model (SAM) has gained popularity as a versatile image segmentation method, thanks to its strong generalization capabilities across various domains. However, when applied to optic disc (OD) and optic cup (OC) segmentation tasks, SAM encounters challenges due to the complex structures, low contrast, and blurred boundaries typical of fundus images, leading to suboptimal performance. To overcome these challenges, we introduce a novel model, FunduSAM, which incorporates several Adapters into SAM to create a deep network specifically designed for OD and OC segmentation. The FunduSAM utilizes Adapter into each transformer block after encoder for parameter fine-tuning (PEFT). It enhances SAM's feature extraction capabilities by designing a Convolutional Block Attention Module (CBAM), addressing issues related to blurred boundaries and low contrast. Given the unique requirements of OD and OC segmentation, polar transformation is used to convert the original fundus OD images into a format better suited for training and evaluating FunduSAM. A joint loss is used to achieve structure preservation between the OD and OC, while accurate segmentation. Extensive experiments on the REFUGE dataset, comprising 1,200 fundus images, demonstrate the superior performance of FunduSAM compared to five mainstream approaches.
Multiple-Crop Human Mesh Recovery with Contrastive Learning and Camera Consistency in A Single Image
Feb 03, 2024



We tackle the problem of single-image Human Mesh Recovery (HMR). Previous approaches are mostly based on a single crop. In this paper, we shift the single-crop HMR to a novel multiple-crop HMR paradigm. Cropping a human from image multiple times by shifting and scaling the original bounding box is feasible in practice, easy to implement, and incurs neglectable cost, but immediately enriches available visual details. With multiple crops as input, we manage to leverage the relation among these crops to extract discriminative features and reduce camera ambiguity. Specifically, (1) we incorporate a contrastive learning scheme to enhance the similarity between features extracted from crops of the same human. (2) We also propose a crop-aware fusion scheme to fuse the features of multiple crops for regressing the target mesh. (3) We compute local cameras for all the input crops and build a camera-consistency loss between the local cameras, which reward us with less ambiguous cameras. Based on the above innovations, our proposed method outperforms previous approaches as demonstrated by the extensive experiments.
Incorporating Exemplar Optimization into Training with Dual Networks for Human Mesh Recovery
Jan 25, 2024



We propose a novel optimization-based human mesh recovery method from a single image. Given a test exemplar, previous approaches optimize the pre-trained regression network to minimize the 2D re-projection loss, which however suffer from over-/under-fitting problems. This is because the ``exemplar optimization'' at testing time has too weak relation to the pre-training process, and the exemplar optimization loss function is different from the training loss function. (1) We incorporate exemplar optimization into the training stage. During training, our method first executes exemplar optimization and subsequently proceeds with training-time optimization. The exemplar optimization may run into a wrong direction, while the subsequent training optimization serves to correct the deviation. Involved in training, the exemplar optimization learns to adapt its behavior to training data, thereby acquires generalibility to test exemplars. (2) We devise a dual-network architecture to convey the novel training paradigm, which is composed of a main regression network and an auxiliary network, in which we can formulate the exemplar optimization loss function in the same form as the training loss function. This further enhances the compatibility between the exemplar and training optimizations. Experiments demonstrate that our exemplar optimization after the novel training scheme significantly outperforms state-of-the-art approaches.
Interleaving One-Class and Weakly-Supervised Models with Adaptive Thresholding for Unsupervised Video Anomaly Detection
Jan 24, 2024



Without human annotations, a typical Unsupervised Video Anomaly Detection (UVAD) method needs to train two models that generate pseudo labels for each other. In previous work, the two models are closely entangled with each other, and it is not known how to upgrade their method without modifying their training framework significantly. Second, previous work usually adopts fixed thresholding to obtain pseudo labels, however the user-specified threshold is not reliable which inevitably introduces errors into the training process. To alleviate these two problems, we propose a novel interleaved framework that alternately trains a One-Class Classification (OCC) model and a Weakly-Supervised (WS) model for UVAD. The OCC or WS models in our method can be easily replaced with other OCC or WS models, which facilitates our method to upgrade with the most recent developments in both fields. For handling the fixed thresholding problem, we break through the conventional cognitive boundary and propose a weighted OCC model that can be trained on both normal and abnormal data. We also propose an adaptive mechanism for automatically finding the optimal threshold for the WS model in a loose to strict manner. Experiments demonstrate that the proposed UVAD method outperforms previous approaches.
Disentangled Representation Learning for Controllable Person Image Generation
Dec 10, 2023



In this paper, we propose a novel framework named DRL-CPG to learn disentangled latent representation for controllable person image generation, which can produce realistic person images with desired poses and human attributes (e.g., pose, head, upper clothes, and pants) provided by various source persons. Unlike the existing works leveraging the semantic masks to obtain the representation of each component, we propose to generate disentangled latent code via a novel attribute encoder with transformers trained in a manner of curriculum learning from a relatively easy step to a gradually hard one. A random component mask-agnostic strategy is introduced to randomly remove component masks from the person segmentation masks, which aims at increasing the difficulty of training and promoting the transformer encoder to recognize the underlying boundaries between each component. This enables the model to transfer both the shape and texture of the components. Furthermore, we propose a novel attribute decoder network to integrate multi-level attributes (e.g., the structure feature and the attribute representation) with well-designed Dual Adaptive Denormalization (DAD) residual blocks. Extensive experiments strongly demonstrate that the proposed approach is able to transfer both the texture and shape of different human parts and yield realistic results. To our knowledge, we are the first to learn disentangled latent representations with transformers for person image generation.
E4S: Fine-grained Face Swapping via Editing With Regional GAN Inversion
Oct 23, 2023
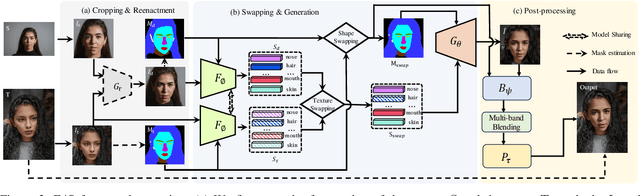
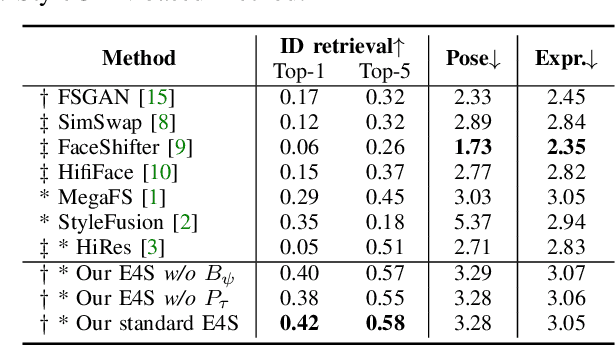
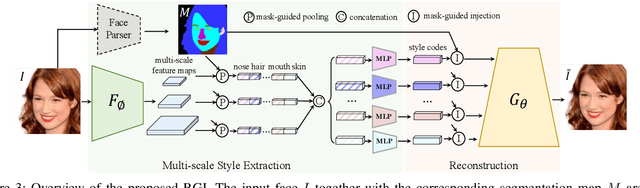
This paper proposes a novel approach to face swapping from the perspective of fine-grained facial editing, dubbed "editing for swapping" (E4S). The traditional face swapping methods rely on global feature extraction and often fail to preserve the source identity. In contrast, our framework proposes a Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. Specifically, our E4S performs face swapping in the latent space of a pretrained StyleGAN, where a multi-scale mask-guided encoder is applied to project the texture of each facial component into regional style codes and a mask-guided injection module then manipulates feature maps with the style codes. Based on this disentanglement, face swapping can be simplified as style and mask swapping. Besides, since reconstructing the source face in the target image may lead to disharmony lighting, we propose to train a re-coloring network to make the swapped face maintain the lighting condition on the target face. Further, to deal with the potential mismatch area during mask exchange, we designed a face inpainting network as post-processing. The extensive comparisons with state-of-the-art methods demonstrate that our E4S outperforms existing methods in preserving texture, shape, and lighting. Our implementation is available at https://github.com/e4s2023/E4S2023.