 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Transferable Adversarial Attacks on Point Clouds from a Compact Subspace Perspective
Jan 30, 2026Transferable adversarial attacks on point clouds remain challenging, as existing methods often rely on model-specific gradients or heuristics that limit generalization to unseen architectures. In this paper, we rethink adversarial transferability from a compact subspace perspective and propose CoSA, a transferable attack framework that operates within a shared low-dimensional semantic space. Specifically, each point cloud is represented as a compact combination of class-specific prototypes that capture shared semantic structure, while adversarial perturbations are optimized within a low-rank subspace to induce coherent and architecture-agnostic variations. This design suppresses model-dependent noise and constrains perturbations to semantically meaningful directions, thereby improving cross-model transferability without relying on surrogate-specific artifacts. Extensive experiments on multiple datasets and network architectures demonstrate that CoSA consistently outperforms state-of-the-art transferable attacks, while maintaining competitive imperceptibility and robustness under common defense strategies. Codes will be made public upon paper acceptance.
Optimal Transport-Induced Samples against Out-of-Distribution Overconfidence
Jan 29, 2026Deep neural networks (DNNs) often produce overconfident predictions on out-of-distribution (OOD) inputs, undermining their reliability in open-world environments. Singularities in semi-discrete optimal transport (OT) mark regions of semantic ambiguity, where classifiers are particularly prone to unwarranted high-confidence predictions. Motivated by this observation, we propose a principled framework to mitigate OOD overconfidence by leveraging the geometry of OT-induced singular boundaries. Specifically, we formulate an OT problem between a continuous base distribution and the latent embeddings of training data, and identify the resulting singular boundaries. By sampling near these boundaries, we construct a class of OOD inputs, termed optimal transport-induced OOD samples (OTIS), which are geometrically grounded and inherently semantically ambiguous. During training, a confidence suppression loss is applied to OTIS to guide the model toward more calibrated predictions in structurally uncertain regions. Extensive experiments show that our method significantly alleviates OOD overconfidence and outperforms state-of-the-art methods.
SEER: Semantic Enhancement and Emotional Reasoning Network for Multimodal Fake News Detection
Jul 17, 2025Previous studies on multimodal fake news detection mainly focus on the alignment and integration of cross-modal features, as well as the application of text-image consistency. However, they overlook the semantic enhancement effects of large multimodal models and pay little attention to the emotional features of news. In addition, people find that fake news is more inclined to contain negative emotions than real ones. Therefore, we propose a novel Semantic Enhancement and Emotional Reasoning (SEER) Network for multimodal fake news detection. We generate summarized captions for image semantic understanding and utilize the products of large multimodal models for semantic enhancement. Inspired by the perceived relationship between news authenticity and emotional tendencies, we propose an expert emotional reasoning module that simulates real-life scenarios to optimize emotional features and infer the authenticity of news. Extensive experiments on two real-world datasets demonstrate the superiority of our SEER over state-of-the-art baselines.
HyperDet: Source Detection in Hypergraphs via Interactive Relationship Construction and Feature-rich Attention Fusion
May 19, 2025Hypergraphs offer superior modeling capabilities for social networks, particularly in capturing group phenomena that extend beyond pairwise interactions in rumor propagation. Existing approaches in rumor source detection predominantly focus on dyadic interactions, which inadequately address the complexity of more intricate relational structures. In this study, we present a novel approach for Source Detection in Hypergraphs (HyperDet) via Interactive Relationship Construction and Feature-rich Attention Fusion. Specifically, our methodology employs an Interactive Relationship Construction module to accurately model both the static topology and dynamic interactions among users, followed by the Feature-rich Attention Fusion module, which autonomously learns node features and discriminates between nodes using a self-attention mechanism, thereby effectively learning node representations under the framework of accurately modeled higher-order relationships. Extensive experimental validation confirms the efficacy of our HyperDet approach, showcasing its superiority relative to current state-of-the-art methods.
SourceDetMamba: A Graph-aware State Space Model for Source Detection in Sequential Hypergraphs
May 19, 2025Source detection on graphs has demonstrated high efficacy in identifying rumor origins. Despite advances in machine learning-based methods, many fail to capture intrinsic dynamics of rumor propagation. In this work, we present SourceDetMamba: A Graph-aware State Space Model for Source Detection in Sequential Hypergraphs, which harnesses the recent success of the state space model Mamba, known for its superior global modeling capabilities and computational efficiency, to address this challenge. Specifically, we first employ hypergraphs to model high-order interactions within social networks. Subsequently, temporal network snapshots generated during the propagation process are sequentially fed in reverse order into Mamba to infer underlying propagation dynamics. Finally, to empower the sequential model to effectively capture propagation patterns while integrating structural information, we propose a novel graph-aware state update mechanism, wherein the state of each node is propagated and refined by both temporal dependencies and topological context. Extensive evaluations on eight datasets demonstrate that SourceDetMamba consistently outperforms state-of-the-art approaches.
EOOD: Entropy-based Out-of-distribution Detection
Apr 04, 2025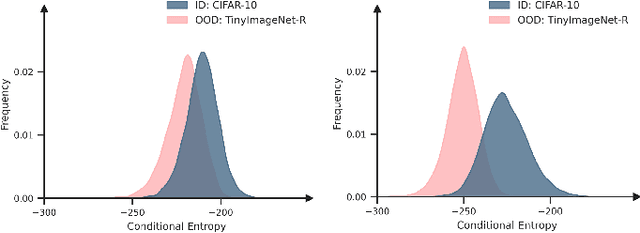
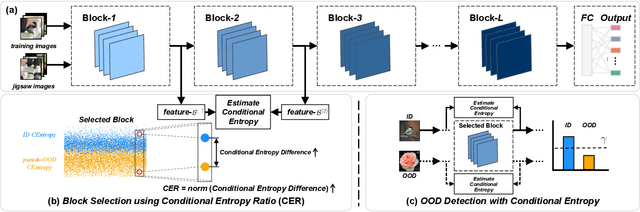
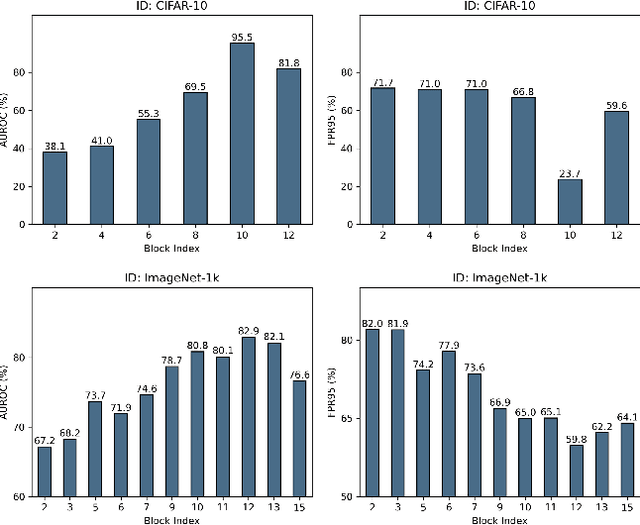
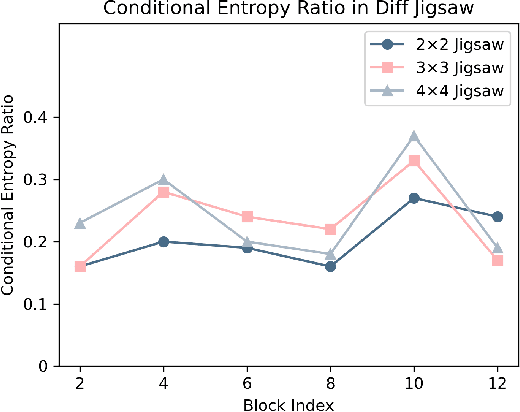
Deep neural networks (DNNs) often exhibit overconfidence when encountering out-of-distribution (OOD) samples, posing significant challenges for deployment. Since DNNs are trained on in-distribution (ID) datasets, the information flow of ID samples through DNNs inevitably differs from that of OOD samples. In this paper, we propose an Entropy-based Out-Of-distribution Detection (EOOD) framework. EOOD first identifies specific block where the information flow differences between ID and OOD samples are more pronounced, using both ID and pseudo-OOD samples. It then calculates the conditional entropy on the selected block as the OOD confidence score. Comprehensive experiments conducted across various ID and OOD settings demonstrate the effectiveness of EOOD in OOD detection and its superiority over state-of-the-art methods.
Imperceptible Adversarial Attacks on Point Clouds Guided by Point-to-Surface Field
Dec 26, 2024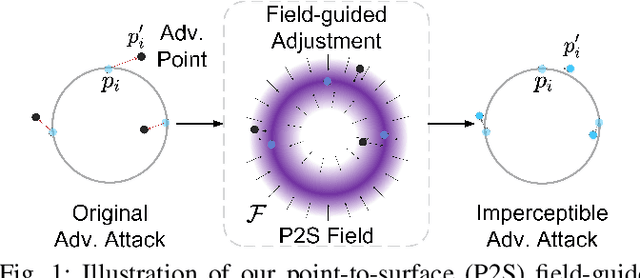


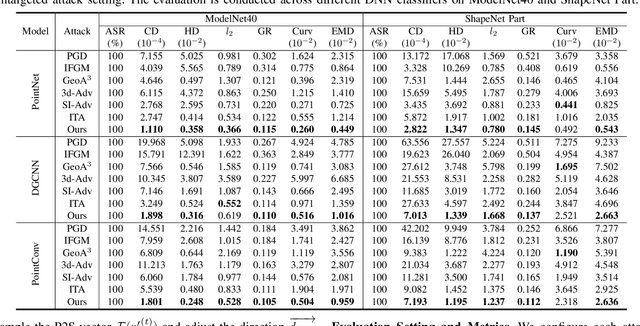
Adversarial attacks on point clouds are crucial for assessing and improving the adversarial robustness of 3D deep learning models. Traditional solutions strictly limit point displacement during attacks, making it challenging to balance imperceptibility with adversarial effectiveness. In this paper, we attribute the inadequate imperceptibility of adversarial attacks on point clouds to deviations from the underlying surface. To address this, we introduce a novel point-to-surface (P2S) field that adjusts adversarial perturbation directions by dragging points back to their original underlying surface. Specifically, we use a denoising network to learn the gradient field of the logarithmic density function encoding the shape's surface, and apply a distance-aware adjustment to perturbation directions during attacks, thereby enhancing imperceptibility. Extensive experiments show that adversarial attacks guided by our P2S field are more imperceptible, outperforming state-of-the-art methods.
Hypergraph Attacks via Injecting Homogeneous Nodes into Elite Hyperedges
Dec 24, 2024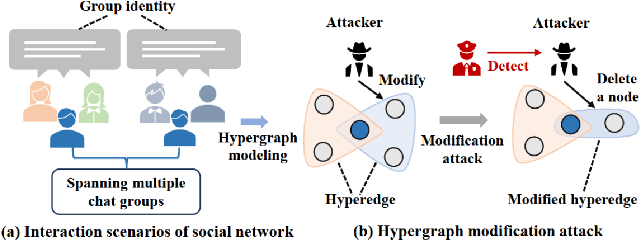
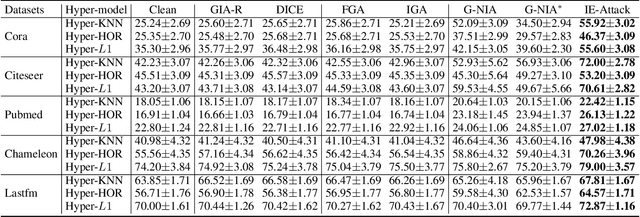


Recent studies have shown that Hypergraph Neural Networks (HGNNs) are vulnerable to adversarial attacks. Existing approaches focus on hypergraph modification attacks guided by gradients, overlooking node spanning in the hypergraph and the group identity of hyperedges, thereby resulting in limited attack performance and detectable attacks. In this manuscript, we present a novel framework, i.e., Hypergraph Attacks via Injecting Homogeneous Nodes into Elite Hyperedges (IE-Attack), to tackle these challenges. Initially, utilizing the node spanning in the hypergraph, we propose the elite hyperedges sampler to identify hyperedges to be injected. Subsequently, a node generator utilizing Kernel Density Estimation (KDE) is proposed to generate the homogeneous node with the group identity of hyperedges. Finally, by injecting the homogeneous node into elite hyperedges, IE-Attack improves the attack performance and enhances the imperceptibility of attacks. Extensive experiments are conducted on five authentic datasets to validate the effectiveness of IE-Attack and the corresponding superiority to state-of-the-art methods.
MHSA: A Multi-scale Hypergraph Network for Mild Cognitive Impairment Detection via Synchronous and Attentive Fusion
Dec 11, 2024The precise detection of mild cognitive impairment (MCI) is of significant importance in preventing the deterioration of patients in a timely manner. Although hypergraphs have enhanced performance by learning and analyzing brain networks, they often only depend on vector distances between features at a single scale to infer interactions. In this paper, we deal with a more arduous challenge, hypergraph modelling with synchronization between brain regions, and design a novel framework, i.e., A Multi-scale Hypergraph Network for MCI Detection via Synchronous and Attentive Fusion (MHSA), to tackle this challenge. Specifically, our approach employs the Phase-Locking Value (PLV) to calculate the phase synchronization relationship in the spectrum domain of regions of interest (ROIs) and designs a multi-scale feature fusion mechanism to integrate dynamic connectivity features of functional magnetic resonance imaging (fMRI) from both the temporal and spectrum domains. To evaluate and optimize the direct contribution of each ROI to phase synchronization in the temporal domain, we structure the PLV coefficients dynamically adjust strategy, and the dynamic hypergraph is modelled based on a comprehensive temporal-spectrum fusion matrix. Experiments on the real-world dataset indicate the effectiveness of our strategy. The code is available at https://github.com/Jia-Weiming/MHSA.
A General Black-box Adversarial Attack on Graph-based Fake News Detectors
Apr 26, 2024Graph Neural Network (GNN)-based fake news detectors apply various methods to construct graphs, aiming to learn distinctive news embeddings for classification. Since the construction details are unknown for attackers in a black-box scenario, it is unrealistic to conduct the classical adversarial attacks that require a specific adjacency matrix. In this paper, we propose the first general black-box adversarial attack framework, i.e., General Attack via Fake Social Interaction (GAFSI), against detectors based on different graph structures. Specifically, as sharing is an important social interaction for GNN-based fake news detectors to construct the graph, we simulate sharing behaviors to fool the detectors. Firstly, we propose a fraudster selection module to select engaged users leveraging local and global information. In addition, a post injection module guides the selected users to create shared relations by sending posts. The sharing records will be added to the social context, leading to a general attack against different detectors. Experimental results on empirical datasets demonstrate the effectiveness of GAFSI.