 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Patient Education as Multi-turn Multi-modal Interaction
Apr 16, 2026Most medical multimodal benchmarks focus on static tasks such as image question answering, report generation, and plain-language rewriting. Patient education is more demanding: systems must identify relevant evidence across images, show patients where to look, explain findings in accessible language, and handle confusion or distress. Yet most patient education work remains text-only, even though combined image-and-text explanations may better support understanding. We introduce MedImageEdu, a benchmark for multi-turn, evidence-grounded radiology patient education. Each case provides a radiology report with report text and case images. A DoctorAgent interacts with a PatientAgent, conditioned on a hidden profile that captures factors such as education level, health literacy, and personality. When a patient question would benefit from visual support, the DoctorAgent can issue drawing instructions grounded in the report, case images, and the current question to a benchmark-provided drawing tool. The tool returns image(s), after which the DoctorAgent produces a final multimodal response consisting of the image(s) and a grounded plain-language explanation. MedImageEdu contains 150 cases from three sources and evaluates both the consultation process and the final multimodal response along five dimensions: Consultation, Safety and Scope, Language Quality, Drawing Quality, and Image-Text Response Quality. Across representative open- and closed-source vision-language model agents, we find three consistent gaps: fluent language often outpaces faithful visual grounding, safety is the weakest dimension across disease categories, and emotionally tense interactions are harder than low education or low health literacy. MedImageEdu provides a controlled testbed for assessing whether multimodal agents can teach from evidence rather than merely answer from text.
MHSA: A Multi-scale Hypergraph Network for Mild Cognitive Impairment Detection via Synchronous and Attentive Fusion
Dec 11, 2024The precise detection of mild cognitive impairment (MCI) is of significant importance in preventing the deterioration of patients in a timely manner. Although hypergraphs have enhanced performance by learning and analyzing brain networks, they often only depend on vector distances between features at a single scale to infer interactions. In this paper, we deal with a more arduous challenge, hypergraph modelling with synchronization between brain regions, and design a novel framework, i.e., A Multi-scale Hypergraph Network for MCI Detection via Synchronous and Attentive Fusion (MHSA), to tackle this challenge. Specifically, our approach employs the Phase-Locking Value (PLV) to calculate the phase synchronization relationship in the spectrum domain of regions of interest (ROIs) and designs a multi-scale feature fusion mechanism to integrate dynamic connectivity features of functional magnetic resonance imaging (fMRI) from both the temporal and spectrum domains. To evaluate and optimize the direct contribution of each ROI to phase synchronization in the temporal domain, we structure the PLV coefficients dynamically adjust strategy, and the dynamic hypergraph is modelled based on a comprehensive temporal-spectrum fusion matrix. Experiments on the real-world dataset indicate the effectiveness of our strategy. The code is available at https://github.com/Jia-Weiming/MHSA.
Graph Learning under Distribution Shifts: A Comprehensive Survey on Domain Adaptation, Out-of-distribution, and Continual Learning
Mar 07, 2024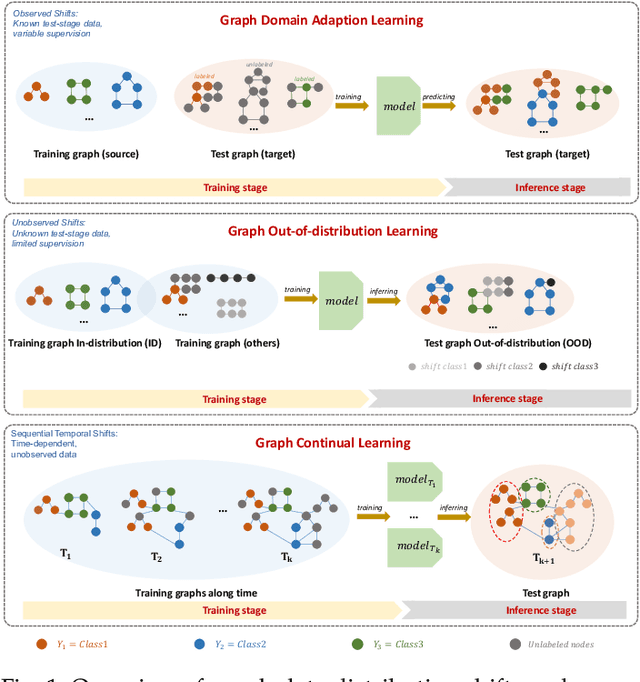

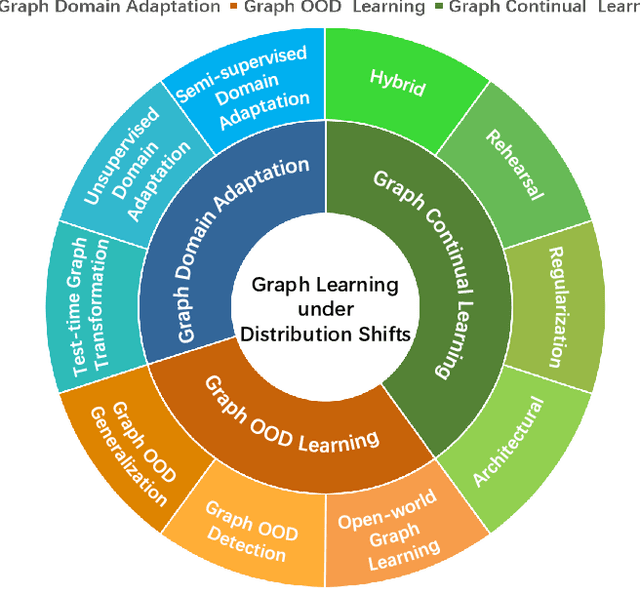
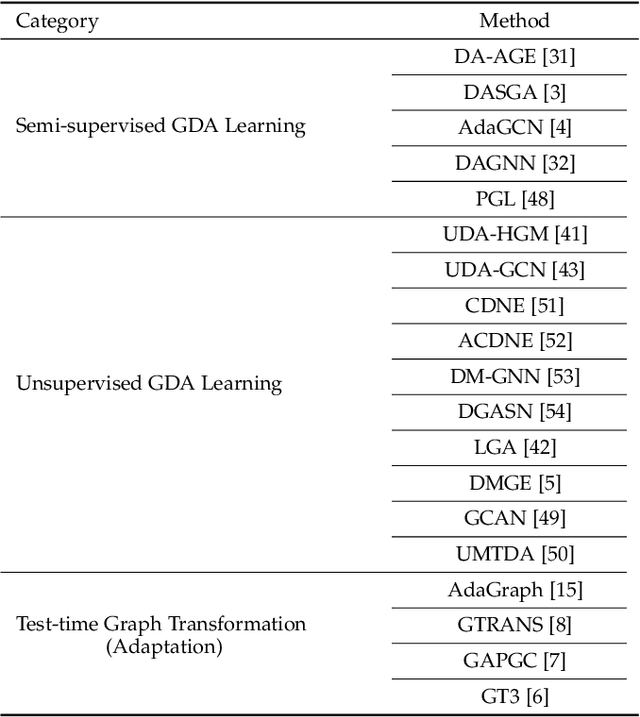
Graph learning plays a pivotal role and has gained significant attention in various application scenarios, from social network analysis to recommendation systems, for its effectiveness in modeling complex data relations represented by graph structural data. In reality, the real-world graph data typically show dynamics over time, with changing node attributes and edge structure, leading to the severe graph data distribution shift issue. This issue is compounded by the diverse and complex nature of distribution shifts, which can significantly impact the performance of graph learning methods in degraded generalization and adaptation capabilities, posing a substantial challenge to their effectiveness. In this survey, we provide a comprehensive review and summary of the latest approaches, strategies, and insights that address distribution shifts within the context of graph learning. Concretely, according to the observability of distributions in the inference stage and the availability of sufficient supervision information in the training stage, we categorize existing graph learning methods into several essential scenarios, including graph domain adaptation learning, graph out-of-distribution learning, and graph continual learning. For each scenario, a detailed taxonomy is proposed, with specific descriptions and discussions of existing progress made in distribution-shifted graph learning. Additionally, we discuss the potential applications and future directions for graph learning under distribution shifts with a systematic analysis of the current state in this field. The survey is positioned to provide general guidance for the development of effective graph learning algorithms in handling graph distribution shifts, and to stimulate future research and advancements in this area.
SIMPL: Generating Synthetic Overhead Imagery to Address Zero-shot and Few-Shot Detection Problems
Jun 29, 2021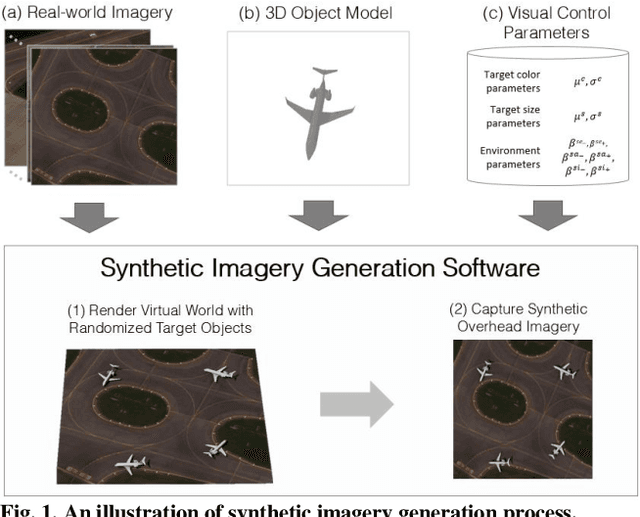
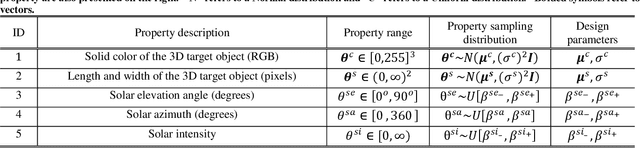

Recently deep neural networks (DNNs) have achieved tremendous success for object detection in overhead (e.g., satellite) imagery. One ongoing challenge however is the acquisition of training data, due to high costs of obtaining satellite imagery and annotating objects in it. In this work we present a simple approach - termed Synthetic object IMPLantation (SIMPL) - to easily and rapidly generate large quantities of synthetic overhead training data for custom target objects. We demonstrate the effectiveness of using SIMPL synthetic imagery for training DNNs in zero-shot scenarios where no real imagery is available; and few-shot learning scenarios, where limited real-world imagery is available. We also conduct experiments to study the sensitivity of SIMPL's effectiveness to some key design parameters, providing users for insights when designing synthetic imagery for custom objects. We release a software implementation of our SIMPL approach so that others can build upon it, or use it for their own custom problems.
BERT-based Chinese Text Classification for Emergency Domain with a Novel Loss Function
Apr 09, 2021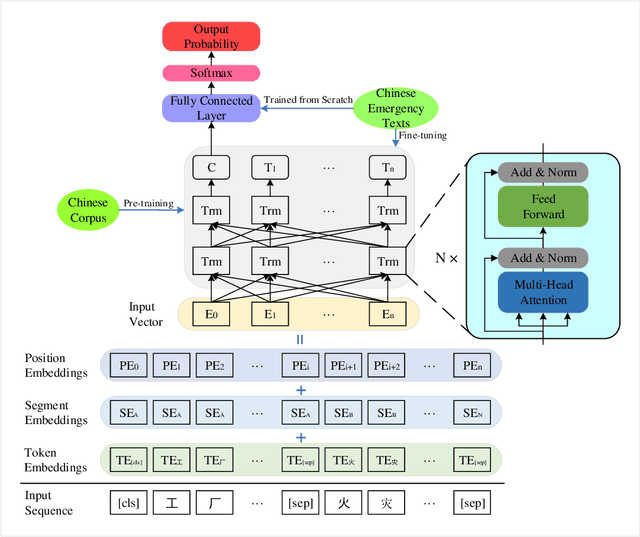
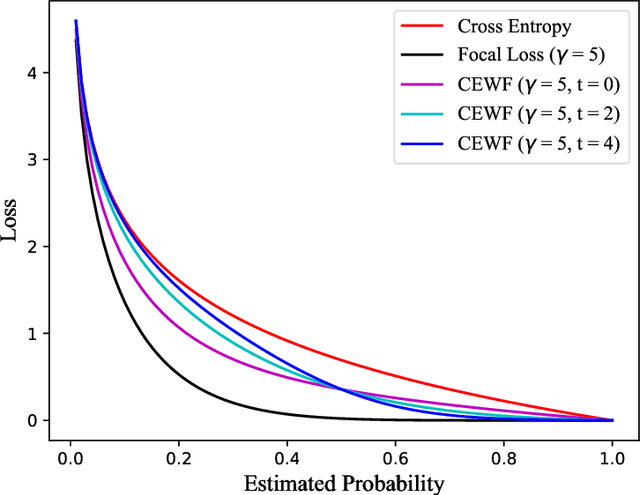
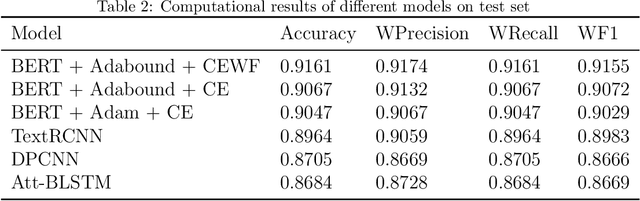
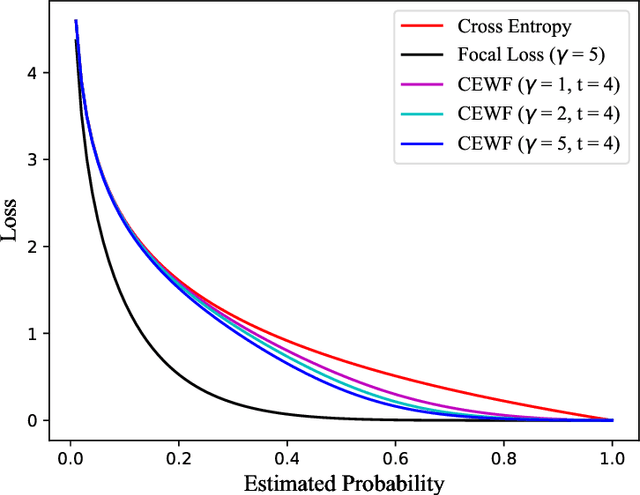
This paper proposes an automatic Chinese text categorization method for solving the emergency event report classification problem. Since bidirectional encoder representations from transformers (BERT) has achieved great success in natural language processing domain, it is employed to derive emergency text features in this study. To overcome the data imbalance problem in the distribution of emergency event categories, a novel loss function is proposed to improve the performance of the BERT-based model. Meanwhile, to avoid the impact of the extreme learning rate, the Adabound optimization algorithm that achieves a gradual smooth transition from Adam to SGD is employed to learn parameters of the model. To verify the feasibility and effectiveness of the proposed method, a Chinese emergency text dataset collected from the Internet is employed. Compared with benchmarking methods, the proposed method has achieved the best performance in terms of accuracy, weighted-precision, weighted-recall, and weighted-F1 values. Therefore, it is promising to employ the proposed method for real applications in smart emergency management systems.
Pretrain Soft Q-Learning with Imperfect Demonstrations
May 09, 2019

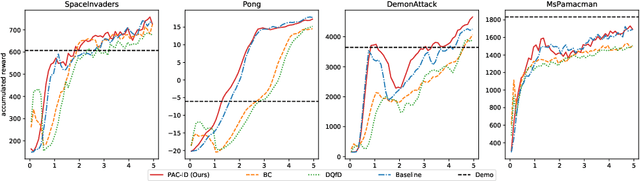
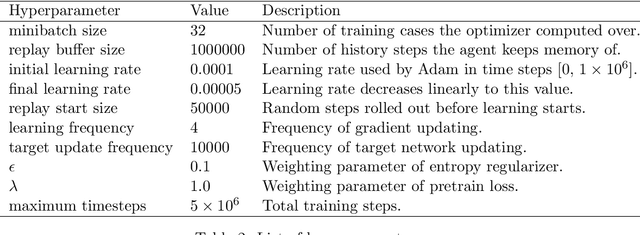
Pretraining reinforcement learning methods with demonstrations has been an important concept in the study of reinforcement learning since a large amount of computing power is spent on online simulations with existing reinforcement learning algorithms. Pretraining reinforcement learning remains a significant challenge in exploiting expert demonstrations whilst keeping exploration potentials, especially for value based methods. In this paper, we propose a pretraining method for soft Q-learning. Our work is inspired by pretraining methods for actor-critic algorithms since soft Q-learning is a value based algorithm that is equivalent to policy gradient. The proposed method is based on $\gamma$-discounted biased policy evaluation with entropy regularization, which is also the updating target of soft Q-learning. Our method is evaluated on various tasks from Atari 2600. Experiments show that our method effectively learns from imperfect demonstrations, and outperforms other state-of-the-art methods that learn from expert demonstrations.