 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTS-Mixer: Spatio-Temporal-Spectral Mixer for 4D Point Cloud Video Understanding
Apr 13, 20264D point cloud videos capture rich spatial and temporal dynamics of scenes which possess unique values in various 4D understanding tasks. However, most existing methods work in the spatiotemporal domain where the underlying geometric characteristics of 4D point cloud videos are hard to capture, leading to degraded representation learning and understanding of 4D point cloud videos. We address the above challenge from a complementary spectral perspective. By transforming 4D point cloud videos into graph spectral signals, we can decompose them into multiple frequency bands each of which captures distinct geometric structures of point cloud videos. Our spectral analysis reveals that the decomposed low-frequency signals capture more coarse shapes while high-frequency signals encode more fine-grained geometry details. Building on these observations, we design Spatio-Temporal-Spectral Mixer (STS-Mixer), a unified framework that mixes spatial, temporal, and spectral representations of point cloud videos. STS-Mixer integrates multi-band delineated spectral signals with spatiotemporal information to capture rich geometries and temporal dynamics, while enabling fine-grained and holistic understanding of 4D point cloud videos. Extensive experiments show that STS-Mixer achieves superior performance consistently across multiple widely adopted benchmarks on both 3D action recognition and 4D semantic segmentation tasks. Code and models are available at https://github.com/Vegetebird/STS-Mixer.
EPOFusion: Exposure aware Progressive Optimization Method for Infrared and Visible Image Fusion
Mar 17, 2026Overexposure frequently occurs in practical scenarios, causing the loss of critical visual information. However, existing infrared and visible fusion methods still exhibit unsatisfactory performance in highly bright regions. To address this, we propose EPOFusion, an exposure-aware fusion model. Specifically, a guidance module is introduced to facilitate the encoder in extracting fine-grained infrared features from overexposed regions. Meanwhile, an iterative decoder incorporating a multiscale context fusion module is designed to progressively enhance the fused image, ensuring consistent details and superior visual quality. Finally, an adaptive loss function dynamically constrains the fusion process, enabling an effective balance between the modalities under varying exposure conditions. To achieve better exposure awareness, we construct the first infrared and visible overexposure dataset (IVOE) with high quality infrared guided annotations for overexposed regions. Extensive experiments show that EPOFusion outperforms existing methods. It maintains infrared cues in overexposed regions while achieving visually faithful fusion in non-overexposed areas, thereby enhancing both visual fidelity and downstream task performance. Code, fusion results and IVOE dataset will be made available at https://github.com/warren-wzw/EPOFusion.git.
GeoMotion: Rethinking Motion Segmentation via Latent 4D Geometry
Feb 25, 2026Motion segmentation in dynamic scenes is highly challenging, as conventional methods heavily rely on estimating camera poses and point correspondences from inherently noisy motion cues. Existing statistical inference or iterative optimization techniques that struggle to mitigate the cumulative errors in multi-stage pipelines often lead to limited performance or high computational cost. In contrast, we propose a fully learning-based approach that directly infers moving objects from latent feature representations via attention mechanisms, thus enabling end-to-end feed-forward motion segmentation. Our key insight is to bypass explicit correspondence estimation and instead let the model learn to implicitly disentangle object and camera motion. Supported by recent advances in 4D scene geometry reconstruction (e.g., $π^3$), the proposed method leverages reliable camera poses and rich spatial-temporal priors, which ensure stable training and robust inference for the model. Extensive experiments demonstrate that by eliminating complex pre-processing and iterative refinement, our approach achieves state-of-the-art motion segmentation performance with high efficiency. The code is available at:https://github.com/zjutcvg/GeoMotion.
L3DR: 3D-aware LiDAR Diffusion and Rectification
Feb 22, 2026Range-view (RV) based LiDAR diffusion has recently made huge strides towards 2D photo-realism. However, it neglects 3D geometry realism and often generates various RV artifacts such as depth bleeding and wavy surfaces. We design L3DR, a 3D-aware LiDAR Diffusion and Rectification framework that can regress and cancel RV artifacts in 3D space and restore local geometry accurately. Our theoretical and empirical analysis reveals that 3D models are inherently superior to 2D models in generating sharp and authentic boundaries. Leveraging such analysis, we design a 3D residual regression network that rectifies RV artifacts and achieves superb geometry realism by predicting point-level offsets in 3D space. On top of that, we design a Welsch Loss that helps focus on local geometry and ignore anomalous regions effectively. Extensive experiments over multiple benchmarks including KITTI, KITTI360, nuScenes and Waymo show that the proposed L3DR achieves state-of-the-art generation and superior geometry-realism consistently. In addition, L3DR is generally applicable to different LiDAR diffusion models with little computational overhead.
A Comprehensive Study on Visual Token Redundancy for Discrete Diffusion-based Multimodal Large Language Models
Nov 19, 2025Discrete diffusion-based multimodal large language models (dMLLMs) have emerged as a promising alternative to autoregressive MLLMs thanks to their advantages in parallel decoding and bidirectional context modeling, but most existing dMLLMs incur significant computational overhead during inference due to the full-sequence attention computation in each denoising step. Pioneer studies attempt to resolve this issue from a modality-agnostic perspective via key-value cache optimization or efficient sampling but most of them overlook modality-specific visual token redundancy. In this work, we conduct a comprehensive study on how visual token redundancy evolves with different dMLLM architectures and tasks and how visual token pruning affects dMLLM responses and efficiency. Specifically, our study reveals that visual redundancy emerges only in from-scratch dMLLMs while handling long-answer tasks. In addition, we validate that visual token pruning introduces non-negligible information loss in dMLLMs and only from-scratch dMLLMs can recover the lost information progressively during late denoising steps. Furthermore, our study shows that layer-skipping is promising for accelerating AR-to-diffusion dMLLMs, whereas progressive or late-step pruning is more effective for from-scratch dMLLMs. Overall, this work offers a new perspective on efficiency optimization for dMLLMs, greatly advancing their applicability across various multimodal understanding tasks.
Spatial Preference Rewarding for MLLMs Spatial Understanding
Oct 16, 2025Multimodal large language models~(MLLMs) have demonstrated promising spatial understanding capabilities, such as referencing and grounding object descriptions. Despite their successes, MLLMs still fall short in fine-grained spatial perception abilities, such as generating detailed region descriptions or accurately localizing objects. Additionally, they often fail to respond to the user's requirements for desired fine-grained spatial understanding. This issue might arise because existing approaches primarily focus on tuning MLLMs to model pre-annotated instruction data to inject spatial knowledge, without direct supervision of MLLMs' actual responses. We address this issue by SPR, a Spatial Preference Rewarding~(SPR) approach that enhances MLLMs' spatial capabilities by rewarding MLLMs' detailed responses with precise object localization over vague or inaccurate responses. With randomly selected image regions and region descriptions from MLLMs, SPR introduces semantic and localization scores to comprehensively evaluate the text quality and localization quality in MLLM-generated descriptions. We also refine the MLLM descriptions with better localization accuracy and pair the best-scored refinement with the initial descriptions of the lowest score for direct preference optimization, thereby enhancing fine-grained alignment with visual input. Extensive experiments over standard referring and grounding benchmarks show that SPR improves MLLM spatial understanding capabilities effectively with minimal overhead in training. Data and code will be released at https://github.com/hanqiu-hq/SPR
PacGDC: Label-Efficient Generalizable Depth Completion with Projection Ambiguity and Consistency
Jul 10, 2025Generalizable depth completion enables the acquisition of dense metric depth maps for unseen environments, offering robust perception capabilities for various downstream tasks. However, training such models typically requires large-scale datasets with metric depth labels, which are often labor-intensive to collect. This paper presents PacGDC, a label-efficient technique that enhances data diversity with minimal annotation effort for generalizable depth completion. PacGDC builds on novel insights into inherent ambiguities and consistencies in object shapes and positions during 2D-to-3D projection, allowing the synthesis of numerous pseudo geometries for the same visual scene. This process greatly broadens available geometries by manipulating scene scales of the corresponding depth maps. To leverage this property, we propose a new data synthesis pipeline that uses multiple depth foundation models as scale manipulators. These models robustly provide pseudo depth labels with varied scene scales, affecting both local objects and global layouts, while ensuring projection consistency that supports generalization. To further diversify geometries, we incorporate interpolation and relocation strategies, as well as unlabeled images, extending the data coverage beyond the individual use of foundation models. Extensive experiments show that PacGDC achieves remarkable generalizability across multiple benchmarks, excelling in diverse scene semantics/scales and depth sparsity/patterns under both zero-shot and few-shot settings. Code: https://github.com/Wang-xjtu/PacGDC.
Exploring 3D Activity Reasoning and Planning: From Implicit Human Intentions to Route-Aware Planning
Mar 17, 20253D activity reasoning and planning has attracted increasing attention in human-robot interaction and embodied AI thanks to the recent advance in multimodal learning. However, most existing works share two constraints: 1) heavy reliance on explicit instructions with little reasoning on implicit user intention; 2) negligence of inter-step route planning on robot moves. To bridge the gaps, we propose 3D activity reasoning and planning, a novel 3D task that reasons the intended activities from implicit instructions and decomposes them into steps with inter-step routes and planning under the guidance of fine-grained 3D object shapes and locations from scene segmentation. We tackle the new 3D task from two perspectives. First, we construct ReasonPlan3D, a large-scale benchmark that covers diverse 3D scenes with rich implicit instructions and detailed annotations for multi-step task planning, inter-step route planning, and fine-grained segmentation. Second, we design a novel framework that introduces progressive plan generation with contextual consistency across multiple steps, as well as a scene graph that is updated dynamically for capturing critical objects and their spatial relations. Extensive experiments demonstrate the effectiveness of our benchmark and framework in reasoning activities from implicit human instructions, producing accurate stepwise task plans, and seamlessly integrating route planning for multi-step moves. The dataset and code will be released.
Data-Efficient Generalization for Zero-shot Composed Image Retrieval
Mar 07, 2025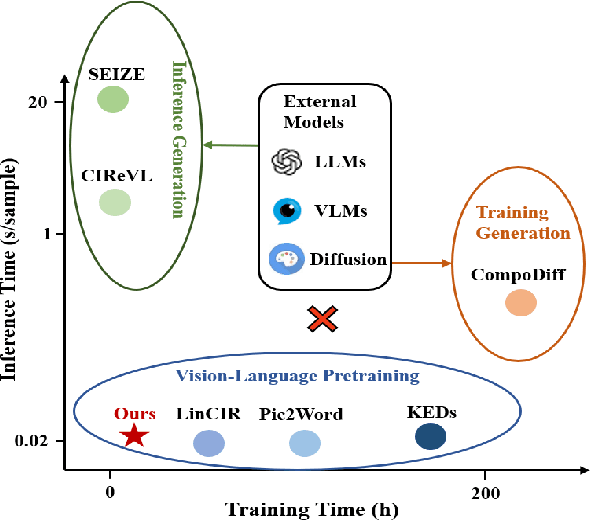
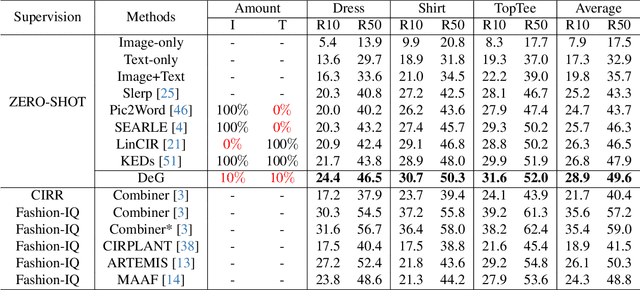
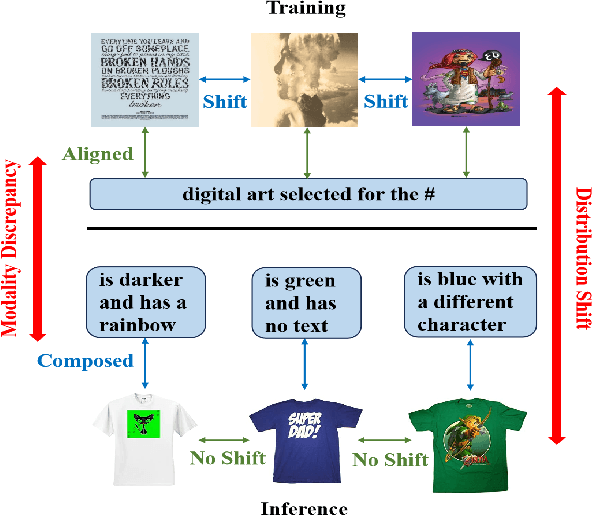
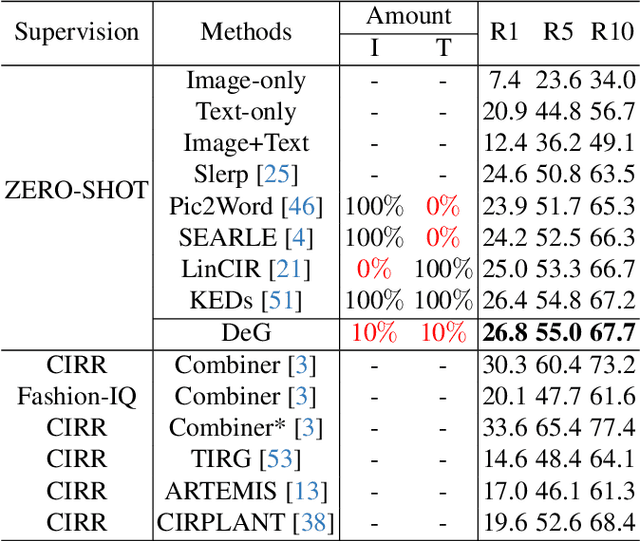
Zero-shot Composed Image Retrieval (ZS-CIR) aims to retrieve the target image based on a reference image and a text description without requiring in-distribution triplets for training. One prevalent approach follows the vision-language pretraining paradigm that employs a mapping network to transfer the image embedding to a pseudo-word token in the text embedding space. However, this approach tends to impede network generalization due to modality discrepancy and distribution shift between training and inference. To this end, we propose a Data-efficient Generalization (DeG) framework, including two novel designs, namely, Textual Supplement (TS) module and Semantic-Set (S-Set). The TS module exploits compositional textual semantics during training, enhancing the pseudo-word token with more linguistic semantics and thus mitigating the modality discrepancy effectively. The S-Set exploits the zero-shot capability of pretrained Vision-Language Models (VLMs), alleviating the distribution shift and mitigating the overfitting issue from the redundancy of the large-scale image-text data. Extensive experiments over four ZS-CIR benchmarks show that DeG outperforms the state-of-the-art (SOTA) methods with much less training data, and saves substantial training and inference time for practical usage.
Bringing RGB and IR Together: Hierarchical Multi-Modal Enhancement for Robust Transmission Line Detection
Jan 25, 2025Ensuring a stable power supply in rural areas relies heavily on effective inspection of power equipment, particularly transmission lines (TLs). However, detecting TLs from aerial imagery can be challenging when dealing with misalignments between visible light (RGB) and infrared (IR) images, as well as mismatched high- and low-level features in convolutional networks. To address these limitations, we propose a novel Hierarchical Multi-Modal Enhancement Network (HMMEN) that integrates RGB and IR data for robust and accurate TL detection. Our method introduces two key components: (1) a Mutual Multi-Modal Enhanced Block (MMEB), which fuses and enhances hierarchical RGB and IR feature maps in a coarse-to-fine manner, and (2) a Feature Alignment Block (FAB) that corrects misalignments between decoder outputs and IR feature maps by leveraging deformable convolutions. We employ MobileNet-based encoders for both RGB and IR inputs to accommodate edge-computing constraints and reduce computational overhead. Experimental results on diverse weather and lighting conditionsfog, night, snow, and daytimedemonstrate the superiority and robustness of our approach compared to state-of-the-art methods, resulting in fewer false positives, enhanced boundary delineation, and better overall detection performance. This framework thus shows promise for practical large-scale power line inspections with unmanned aerial vehicles.