 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongHalQA: Long-Context Hallucination Evaluation for MultiModal Large Language Models
Paper and Code
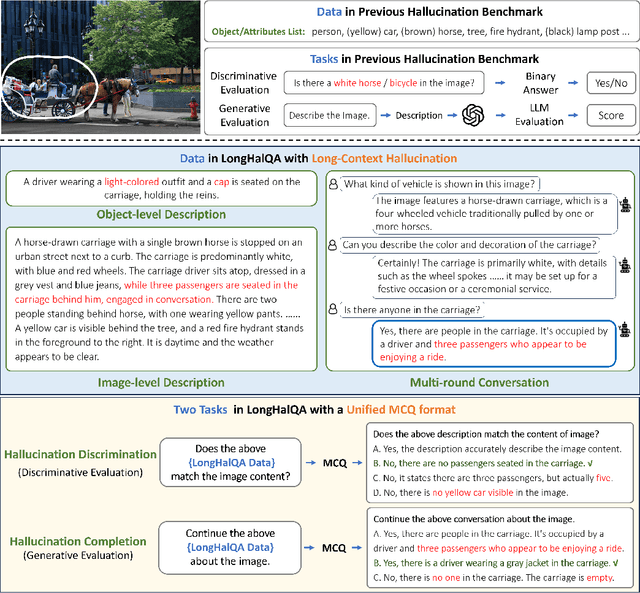



Hallucination, a phenomenon where multimodal large language models~(MLLMs) tend to generate textual responses that are plausible but unaligned with the image, has become one major hurdle in various MLLM-related applications. Several benchmarks have been created to gauge the hallucination levels of MLLMs, by either raising discriminative questions about the existence of objects or introducing LLM evaluators to score the generated text from MLLMs. However, the discriminative data largely involve simple questions that are not aligned with real-world text, while the generative data involve LLM evaluators that are computationally intensive and unstable due to their inherent randomness. We propose LongHalQA, an LLM-free hallucination benchmark that comprises 6K long and complex hallucination text. LongHalQA is featured by GPT4V-generated hallucinatory data that are well aligned with real-world scenarios, including object/image descriptions and multi-round conversations with 14/130 words and 189 words, respectively, on average. It introduces two new tasks, hallucination discrimination and hallucination completion, unifying both discriminative and generative evaluations in a single multiple-choice-question form and leading to more reliable and efficient evaluations without the need for LLM evaluators. Further, we propose an advanced pipeline that greatly facilitates the construction of future hallucination benchmarks with long and complex questions and descriptions. Extensive experiments over multiple recent MLLMs reveal various new challenges when they are handling hallucinations with long and complex textual data. Dataset and evaluation code are available at https://github.com/hanqiu-hq/LongHalQA.