 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongHalQA: Long-Context Hallucination Evaluation for MultiModal Large Language Models
Oct 15, 2024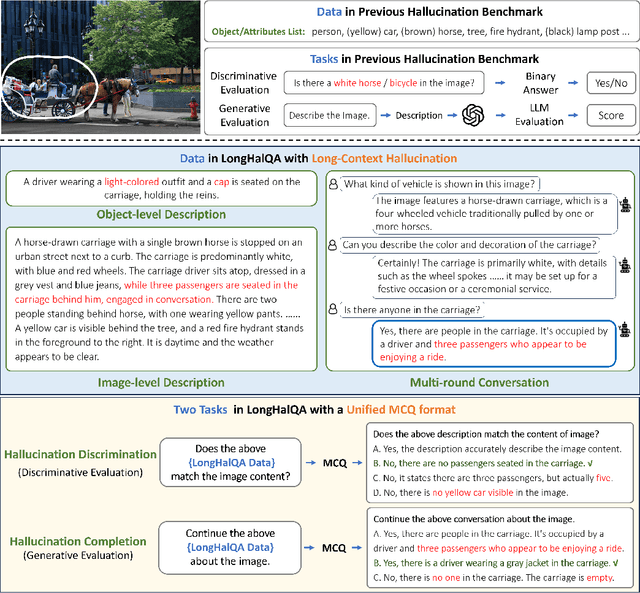



Hallucination, a phenomenon where multimodal large language models~(MLLMs) tend to generate textual responses that are plausible but unaligned with the image, has become one major hurdle in various MLLM-related applications. Several benchmarks have been created to gauge the hallucination levels of MLLMs, by either raising discriminative questions about the existence of objects or introducing LLM evaluators to score the generated text from MLLMs. However, the discriminative data largely involve simple questions that are not aligned with real-world text, while the generative data involve LLM evaluators that are computationally intensive and unstable due to their inherent randomness. We propose LongHalQA, an LLM-free hallucination benchmark that comprises 6K long and complex hallucination text. LongHalQA is featured by GPT4V-generated hallucinatory data that are well aligned with real-world scenarios, including object/image descriptions and multi-round conversations with 14/130 words and 189 words, respectively, on average. It introduces two new tasks, hallucination discrimination and hallucination completion, unifying both discriminative and generative evaluations in a single multiple-choice-question form and leading to more reliable and efficient evaluations without the need for LLM evaluators. Further, we propose an advanced pipeline that greatly facilitates the construction of future hallucination benchmarks with long and complex questions and descriptions. Extensive experiments over multiple recent MLLMs reveal various new challenges when they are handling hallucinations with long and complex textual data. Dataset and evaluation code are available at https://github.com/hanqiu-hq/LongHalQA.
I-Max: Maximize the Resolution Potential of Pre-trained Rectified Flow Transformers with Projected Flow
Oct 10, 2024

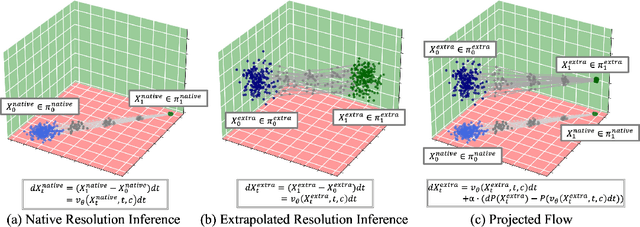
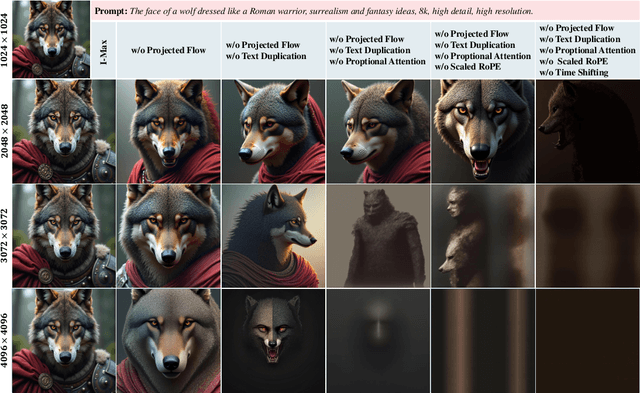
Rectified Flow Transformers (RFTs) offer superior training and inference efficiency, making them likely the most viable direction for scaling up diffusion models. However, progress in generation resolution has been relatively slow due to data quality and training costs. Tuning-free resolution extrapolation presents an alternative, but current methods often reduce generative stability, limiting practical application. In this paper, we review existing resolution extrapolation methods and introduce the I-Max framework to maximize the resolution potential of Text-to-Image RFTs. I-Max features: (i) a novel Projected Flow strategy for stable extrapolation and (ii) an advanced inference toolkit for generalizing model knowledge to higher resolutions. Experiments with Lumina-Next-2K and Flux.1-dev demonstrate I-Max's ability to enhance stability in resolution extrapolation and show that it can bring image detail emergence and artifact correction, confirming the practical value of tuning-free resolution extrapolation.
Reinforcement Learning to Optimize Lifetime Value in Cold-Start Recommendation
Aug 20, 2021
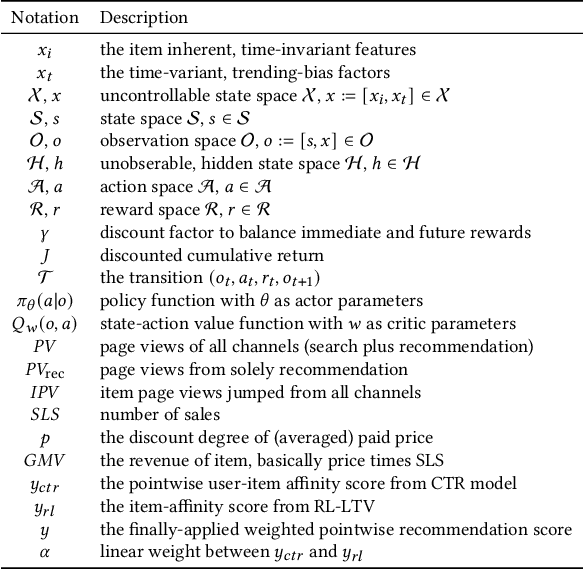


Recommender system plays a crucial role in modern E-commerce platform. Due to the lack of historical interactions between users and items, cold-start recommendation is a challenging problem. In order to alleviate the cold-start issue, most existing methods introduce content and contextual information as the auxiliary information. Nevertheless, these methods assume the recommended items behave steadily over time, while in a typical E-commerce scenario, items generally have very different performances throughout their life period. In such a situation, it would be beneficial to consider the long-term return from the item perspective, which is usually ignored in conventional methods. Reinforcement learning (RL) naturally fits such a long-term optimization problem, in which the recommender could identify high potential items, proactively allocate more user impressions to boost their growth, therefore improve the multi-period cumulative gains. Inspired by this idea, we model the process as a Partially Observable and Controllable Markov Decision Process (POC-MDP), and propose an actor-critic RL framework (RL-LTV) to incorporate the item lifetime values (LTV) into the recommendation. In RL-LTV, the critic studies historical trajectories of items and predict the future LTV of fresh item, while the actor suggests a score-based policy which maximizes the future LTV expectation. Scores suggested by the actor are then combined with classical ranking scores in a dual-rank framework, therefore the recommendation is balanced with the LTV consideration. Our method outperforms the strong live baseline with a relative improvement of 8.67% and 18.03% on IPV and GMV of cold-start items, on one of the largest E-commerce platform.