 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE.M.Ground: A Temporal Grounding Vid-LLM with Holistic Event Perception and Matching
Feb 05, 2026Despite recent advances in Video Large Language Models (Vid-LLMs), Temporal Video Grounding (TVG), which aims to precisely localize time segments corresponding to query events, remains a significant challenge. Existing methods often match start and end frames by comparing frame features with two separate tokens, relying heavily on exact timestamps. However, this approach fails to capture the event's semantic continuity and integrity, leading to ambiguities. To address this, we propose E.M.Ground, a novel Vid-LLM for TVG that focuses on holistic and coherent event perception. E.M.Ground introduces three key innovations: (i) a special <event> token that aggregates information from all frames of a query event, preserving semantic continuity for accurate event matching; (ii) Savitzky-Golay smoothing to reduce noise in token-to-frame similarities across timestamps, improving prediction accuracy; (iii) multi-grained frame feature aggregation to enhance matching reliability and temporal understanding, compensating for compression-induced information loss. Extensive experiments on benchmark datasets show that E.M.Ground consistently outperforms state-of-the-art Vid-LLMs by significant margins.
Cross-Domain Few-Shot Segmentation via Multi-view Progressive Adaptation
Feb 05, 2026Cross-Domain Few-Shot Segmentation aims to segment categories in data-scarce domains conditioned on a few exemplars. Typical methods first establish few-shot capability in a large-scale source domain and then adapt it to target domains. However, due to the limited quantity and diversity of target samples, existing methods still exhibit constrained performance. Moreover, the source-trained model's initially weak few-shot capability in target domains, coupled with substantial domain gaps, severely hinders the effective utilization of target samples and further impedes adaptation. To this end, we propose Multi-view Progressive Adaptation, which progressively adapts few-shot capability to target domains from both data and strategy perspectives. (i) From the data perspective, we introduce Hybrid Progressive Augmentation, which progressively generates more diverse and complex views through cumulative strong augmentations, thereby creating increasingly challenging learning scenarios. (ii) From the strategy perspective, we design Dual-chain Multi-view Prediction, which fully leverages these progressively complex views through sequential and parallel learning paths under extensive supervision. By jointly enforcing prediction consistency across diverse and complex views, MPA achieves both robust and accurate adaptation to target domains. Extensive experiments demonstrate that MPA effectively adapts few-shot capability to target domains, outperforming state-of-the-art methods by a large margin (+7.0%).
Boosting SAM for Cross-Domain Few-Shot Segmentation via Conditional Point Sparsification
Feb 05, 2026Motivated by the success of the Segment Anything Model (SAM) in promptable segmentation, recent studies leverage SAM to develop training-free solutions for few-shot segmentation, which aims to predict object masks in the target image based on a few reference exemplars. These SAM-based methods typically rely on point matching between reference and target images and use the matched dense points as prompts for mask prediction. However, we observe that dense points perform poorly in Cross-Domain Few-Shot Segmentation (CD-FSS), where target images are from medical or satellite domains. We attribute this issue to large domain shifts that disrupt the point-image interactions learned by SAM, and find that point density plays a crucial role under such conditions. To address this challenge, we propose Conditional Point Sparsification (CPS), a training-free approach that adaptively guides SAM interactions for cross-domain images based on reference exemplars. Leveraging ground-truth masks, the reference images provide reliable guidance for adaptively sparsifying dense matched points, enabling more accurate segmentation results. Extensive experiments demonstrate that CPS outperforms existing training-free SAM-based methods across diverse CD-FSS datasets.
A Comprehensive Study on Visual Token Redundancy for Discrete Diffusion-based Multimodal Large Language Models
Nov 19, 2025Discrete diffusion-based multimodal large language models (dMLLMs) have emerged as a promising alternative to autoregressive MLLMs thanks to their advantages in parallel decoding and bidirectional context modeling, but most existing dMLLMs incur significant computational overhead during inference due to the full-sequence attention computation in each denoising step. Pioneer studies attempt to resolve this issue from a modality-agnostic perspective via key-value cache optimization or efficient sampling but most of them overlook modality-specific visual token redundancy. In this work, we conduct a comprehensive study on how visual token redundancy evolves with different dMLLM architectures and tasks and how visual token pruning affects dMLLM responses and efficiency. Specifically, our study reveals that visual redundancy emerges only in from-scratch dMLLMs while handling long-answer tasks. In addition, we validate that visual token pruning introduces non-negligible information loss in dMLLMs and only from-scratch dMLLMs can recover the lost information progressively during late denoising steps. Furthermore, our study shows that layer-skipping is promising for accelerating AR-to-diffusion dMLLMs, whereas progressive or late-step pruning is more effective for from-scratch dMLLMs. Overall, this work offers a new perspective on efficiency optimization for dMLLMs, greatly advancing their applicability across various multimodal understanding tasks.
Spatial Preference Rewarding for MLLMs Spatial Understanding
Oct 16, 2025Multimodal large language models~(MLLMs) have demonstrated promising spatial understanding capabilities, such as referencing and grounding object descriptions. Despite their successes, MLLMs still fall short in fine-grained spatial perception abilities, such as generating detailed region descriptions or accurately localizing objects. Additionally, they often fail to respond to the user's requirements for desired fine-grained spatial understanding. This issue might arise because existing approaches primarily focus on tuning MLLMs to model pre-annotated instruction data to inject spatial knowledge, without direct supervision of MLLMs' actual responses. We address this issue by SPR, a Spatial Preference Rewarding~(SPR) approach that enhances MLLMs' spatial capabilities by rewarding MLLMs' detailed responses with precise object localization over vague or inaccurate responses. With randomly selected image regions and region descriptions from MLLMs, SPR introduces semantic and localization scores to comprehensively evaluate the text quality and localization quality in MLLM-generated descriptions. We also refine the MLLM descriptions with better localization accuracy and pair the best-scored refinement with the initial descriptions of the lowest score for direct preference optimization, thereby enhancing fine-grained alignment with visual input. Extensive experiments over standard referring and grounding benchmarks show that SPR improves MLLM spatial understanding capabilities effectively with minimal overhead in training. Data and code will be released at https://github.com/hanqiu-hq/SPR
UniMRSeg: Unified Modality-Relax Segmentation via Hierarchical Self-Supervised Compensation
Sep 19, 2025Multi-modal image segmentation faces real-world deployment challenges from incomplete/corrupted modalities degrading performance. While existing methods address training-inference modality gaps via specialized per-combination models, they introduce high deployment costs by requiring exhaustive model subsets and model-modality matching. In this work, we propose a unified modality-relax segmentation network (UniMRSeg) through hierarchical self-supervised compensation (HSSC). Our approach hierarchically bridges representation gaps between complete and incomplete modalities across input, feature and output levels. % First, we adopt modality reconstruction with the hybrid shuffled-masking augmentation, encouraging the model to learn the intrinsic modality characteristics and generate meaningful representations for missing modalities through cross-modal fusion. % Next, modality-invariant contrastive learning implicitly compensates the feature space distance among incomplete-complete modality pairs. Furthermore, the proposed lightweight reverse attention adapter explicitly compensates for the weak perceptual semantics in the frozen encoder. Last, UniMRSeg is fine-tuned under the hybrid consistency constraint to ensure stable prediction under all modality combinations without large performance fluctuations. Without bells and whistles, UniMRSeg significantly outperforms the state-of-the-art methods under diverse missing modality scenarios on MRI-based brain tumor segmentation, RGB-D semantic segmentation, RGB-D/T salient object segmentation. The code will be released at https://github.com/Xiaoqi-Zhao-DLUT/UniMRSeg.
H$_{2}$OT: Hierarchical Hourglass Tokenizer for Efficient Video Pose Transformers
Sep 08, 2025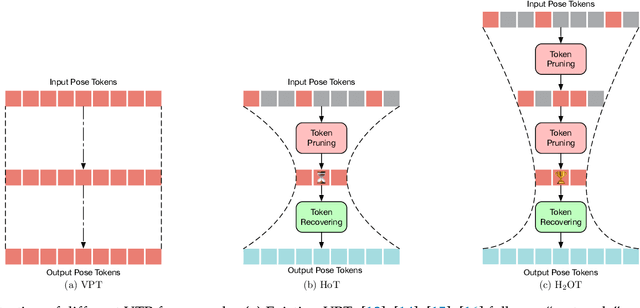

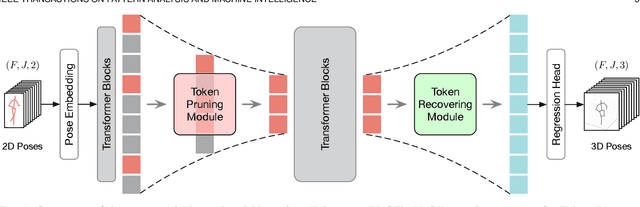

Transformers have been successfully applied in the field of video-based 3D human pose estimation. However, the high computational costs of these video pose transformers (VPTs) make them impractical on resource-constrained devices. In this paper, we present a hierarchical plug-and-play pruning-and-recovering framework, called Hierarchical Hourglass Tokenizer (H$_{2}$OT), for efficient transformer-based 3D human pose estimation from videos. H$_{2}$OT begins with progressively pruning pose tokens of redundant frames and ends with recovering full-length sequences, resulting in a few pose tokens in the intermediate transformer blocks and thus improving the model efficiency. It works with two key modules, namely, a Token Pruning Module (TPM) and a Token Recovering Module (TRM). TPM dynamically selects a few representative tokens to eliminate the redundancy of video frames, while TRM restores the detailed spatio-temporal information based on the selected tokens, thereby expanding the network output to the original full-length temporal resolution for fast inference. Our method is general-purpose: it can be easily incorporated into common VPT models on both seq2seq and seq2frame pipelines while effectively accommodating different token pruning and recovery strategies. In addition, our H$_{2}$OT reveals that maintaining the full pose sequence is unnecessary, and a few pose tokens of representative frames can achieve both high efficiency and estimation accuracy. Extensive experiments on multiple benchmark datasets demonstrate both the effectiveness and efficiency of the proposed method. Code and models are available at https://github.com/NationalGAILab/HoT.
PacGDC: Label-Efficient Generalizable Depth Completion with Projection Ambiguity and Consistency
Jul 10, 2025Generalizable depth completion enables the acquisition of dense metric depth maps for unseen environments, offering robust perception capabilities for various downstream tasks. However, training such models typically requires large-scale datasets with metric depth labels, which are often labor-intensive to collect. This paper presents PacGDC, a label-efficient technique that enhances data diversity with minimal annotation effort for generalizable depth completion. PacGDC builds on novel insights into inherent ambiguities and consistencies in object shapes and positions during 2D-to-3D projection, allowing the synthesis of numerous pseudo geometries for the same visual scene. This process greatly broadens available geometries by manipulating scene scales of the corresponding depth maps. To leverage this property, we propose a new data synthesis pipeline that uses multiple depth foundation models as scale manipulators. These models robustly provide pseudo depth labels with varied scene scales, affecting both local objects and global layouts, while ensuring projection consistency that supports generalization. To further diversify geometries, we incorporate interpolation and relocation strategies, as well as unlabeled images, extending the data coverage beyond the individual use of foundation models. Extensive experiments show that PacGDC achieves remarkable generalizability across multiple benchmarks, excelling in diverse scene semantics/scales and depth sparsity/patterns under both zero-shot and few-shot settings. Code: https://github.com/Wang-xjtu/PacGDC.
UniDet-D: A Unified Dynamic Spectral Attention Model for Object Detection under Adverse Weathers
Jun 14, 2025Real-world object detection is a challenging task where the captured images/videos often suffer from complex degradations due to various adverse weather conditions such as rain, fog, snow, low-light, etc. Despite extensive prior efforts, most existing methods are designed for one specific type of adverse weather with constraints of poor generalization, under-utilization of visual features while handling various image degradations. Leveraging a theoretical analysis on how critical visual details are lost in adverse-weather images, we design UniDet-D, a unified framework that tackles the challenge of object detection under various adverse weather conditions, and achieves object detection and image restoration within a single network. Specifically, the proposed UniDet-D incorporates a dynamic spectral attention mechanism that adaptively emphasizes informative spectral components while suppressing irrelevant ones, enabling more robust and discriminative feature representation across various degradation types. Extensive experiments show that UniDet-D achieves superior detection accuracy across different types of adverse-weather degradation. Furthermore, UniDet-D demonstrates superior generalization towards unseen adverse weather conditions such as sandstorms and rain-fog mixtures, highlighting its great potential for real-world deployment.
ToDRE: Visual Token Pruning via Diversity and Task Awareness for Efficient Large Vision-Language Models
May 24, 2025
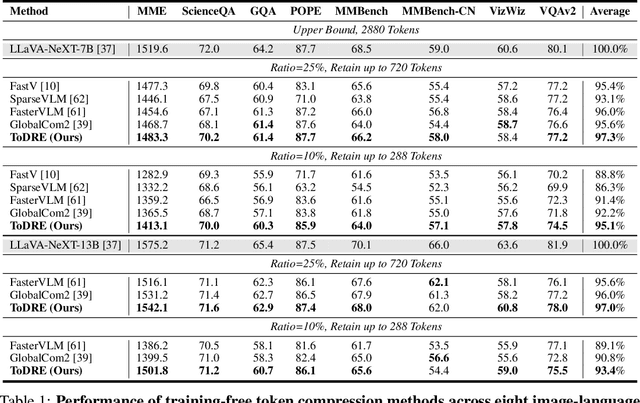
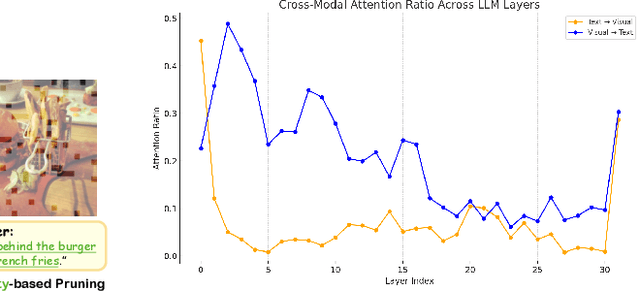
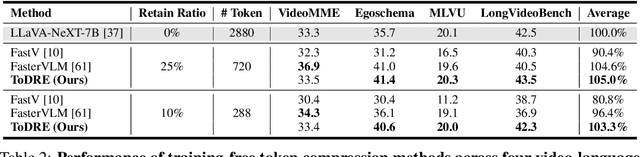
The representation of visual inputs of large vision-language models (LVLMs) usually involves substantially more tokens than that of textual inputs, leading to significant computational overhead. Several recent studies strive to mitigate this issue by either conducting token compression to prune redundant visual tokens or guiding them to bypass certain computational stages. While most existing work exploits token importance as the redundancy indicator, our study reveals that two largely neglected factors, namely, the diversity of retained visual tokens and their task relevance, often offer more robust criteria in token pruning. To this end, we design ToDRE, a two-stage and training-free token compression framework that achieves superior performance by pruning Tokens based on token Diversity and token-task RElevance. Instead of pruning redundant tokens, ToDRE introduces a greedy k-center algorithm to select and retain a small subset of diverse visual tokens after the vision encoder. Additionally, ToDRE addresses the "information migration" by further eliminating task-irrelevant visual tokens within the decoder of large language model (LLM). Extensive experiments show that ToDRE effectively reduces 90% of visual tokens after vision encoder and adaptively prunes all visual tokens within certain LLM's decoder layers, leading to a 2.6x speed-up in total inference time while maintaining 95.1% of model performance and excellent compatibility with efficient attention operators.