 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Camera-Robust 3D Localization: Equation-Anchored Tool-Use for MLLMs
May 19, 20263D localization in Multimodal Large Language Models (MLLMs), including 3D object detection and 3D visual grounding, is fundamentally limited by camera intrinsic ambiguity: the same image admits different 3D scenes under different cameras. Existing MLLMs either ignore camera parameters and overfit to a canonical training intrinsic, or retrieve depth and 3D cues from external tools but treat the returned values as reference cues (numerical hints that the model is free to interpret implicitly), both preventing camera information from being deterministically propagated into the prediction. We propose an equation-anchored tool-use framework that re-purposes spatial tools as formula variables. The proposed framework proactively retrieves camera intrinsics and samples multi-point metric depths, writes the pinhole back-projection equation $\hat{X} = (u_c - c_x)\bar{Z}/f_x$ explicitly in Chain-of-Thought (CoT), and substitutes tool outputs into the formula before regressing the final 9-DoF bounding box. On both 3D object detection and 3D visual grounding tasks under rescaled camera intrinsics from $0.5\times$ to $1.5\times$, our method outperforms RGB-only and tool-augmented baselines, with significant gains where the camera deviates most from the training scale. Code and data will be released.
STS-Mixer: Spatio-Temporal-Spectral Mixer for 4D Point Cloud Video Understanding
Apr 13, 20264D point cloud videos capture rich spatial and temporal dynamics of scenes which possess unique values in various 4D understanding tasks. However, most existing methods work in the spatiotemporal domain where the underlying geometric characteristics of 4D point cloud videos are hard to capture, leading to degraded representation learning and understanding of 4D point cloud videos. We address the above challenge from a complementary spectral perspective. By transforming 4D point cloud videos into graph spectral signals, we can decompose them into multiple frequency bands each of which captures distinct geometric structures of point cloud videos. Our spectral analysis reveals that the decomposed low-frequency signals capture more coarse shapes while high-frequency signals encode more fine-grained geometry details. Building on these observations, we design Spatio-Temporal-Spectral Mixer (STS-Mixer), a unified framework that mixes spatial, temporal, and spectral representations of point cloud videos. STS-Mixer integrates multi-band delineated spectral signals with spatiotemporal information to capture rich geometries and temporal dynamics, while enabling fine-grained and holistic understanding of 4D point cloud videos. Extensive experiments show that STS-Mixer achieves superior performance consistently across multiple widely adopted benchmarks on both 3D action recognition and 4D semantic segmentation tasks. Code and models are available at https://github.com/Vegetebird/STS-Mixer.
Exploring 3D Activity Reasoning and Planning: From Implicit Human Intentions to Route-Aware Planning
Mar 17, 20253D activity reasoning and planning has attracted increasing attention in human-robot interaction and embodied AI thanks to the recent advance in multimodal learning. However, most existing works share two constraints: 1) heavy reliance on explicit instructions with little reasoning on implicit user intention; 2) negligence of inter-step route planning on robot moves. To bridge the gaps, we propose 3D activity reasoning and planning, a novel 3D task that reasons the intended activities from implicit instructions and decomposes them into steps with inter-step routes and planning under the guidance of fine-grained 3D object shapes and locations from scene segmentation. We tackle the new 3D task from two perspectives. First, we construct ReasonPlan3D, a large-scale benchmark that covers diverse 3D scenes with rich implicit instructions and detailed annotations for multi-step task planning, inter-step route planning, and fine-grained segmentation. Second, we design a novel framework that introduces progressive plan generation with contextual consistency across multiple steps, as well as a scene graph that is updated dynamically for capturing critical objects and their spatial relations. Extensive experiments demonstrate the effectiveness of our benchmark and framework in reasoning activities from implicit human instructions, producing accurate stepwise task plans, and seamlessly integrating route planning for multi-step moves. The dataset and code will be released.
Multimodal 3D Reasoning Segmentation with Complex Scenes
Nov 21, 2024

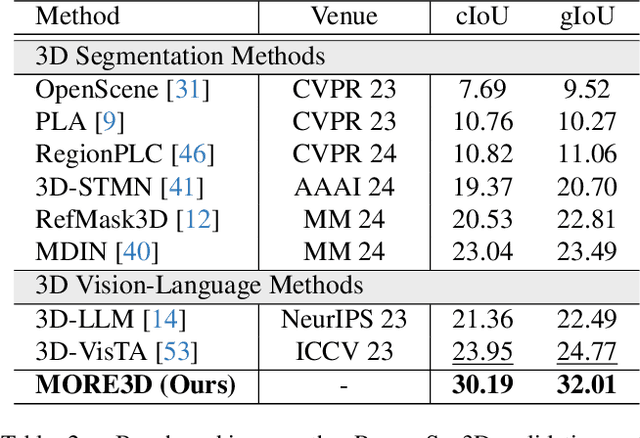

The recent development in multimodal learning has greatly advanced the research in 3D scene understanding in various real-world tasks such as embodied AI. However, most existing work shares two typical constraints: 1) they are short of reasoning ability for interaction and interpretation of human intension and 2) they focus on scenarios with single-category objects only which leads to over-simplified textual descriptions due to the negligence of multi-object scenarios and spatial relations among objects. We bridge the research gaps by proposing a 3D reasoning segmentation task for multiple objects in scenes. The task allows producing 3D segmentation masks and detailed textual explanations as enriched by 3D spatial relations among objects. To this end, we create ReasonSeg3D, a large-scale and high-quality benchmark that integrates 3D spatial relations with generated question-answer pairs and 3D segmentation masks. In addition, we design MORE3D, a simple yet effective method that enables multi-object 3D reasoning segmentation with user questions and textual outputs. Extensive experiments show that MORE3D excels in reasoning and segmenting complex multi-object 3D scenes, and the created ReasonSeg3D offers a valuable platform for future exploration of 3D reasoning segmentation. The dataset and code will be released.
MonoMAE: Enhancing Monocular 3D Detection through Depth-Aware Masked Autoencoders
May 13, 2024Monocular 3D object detection aims for precise 3D localization and identification of objects from a single-view image. Despite its recent progress, it often struggles while handling pervasive object occlusions that tend to complicate and degrade the prediction of object dimensions, depths, and orientations. We design MonoMAE, a monocular 3D detector inspired by Masked Autoencoders that addresses the object occlusion issue by masking and reconstructing objects in the feature space. MonoMAE consists of two novel designs. The first is depth-aware masking that selectively masks certain parts of non-occluded object queries in the feature space for simulating occluded object queries for network training. It masks non-occluded object queries by balancing the masked and preserved query portions adaptively according to the depth information. The second is lightweight query completion that works with the depth-aware masking to learn to reconstruct and complete the masked object queries. With the proposed object occlusion and completion, MonoMAE learns enriched 3D representations that achieve superior monocular 3D detection performance qualitatively and quantitatively for both occluded and non-occluded objects. Additionally, MonoMAE learns generalizable representations that can work well in new domains.
Weakly Supervised Monocular 3D Detection with a Single-View Image
Feb 29, 2024



Monocular 3D detection (M3D) aims for precise 3D object localization from a single-view image which usually involves labor-intensive annotation of 3D detection boxes. Weakly supervised M3D has recently been studied to obviate the 3D annotation process by leveraging many existing 2D annotations, but it often requires extra training data such as LiDAR point clouds or multi-view images which greatly degrades its applicability and usability in various applications. We propose SKD-WM3D, a weakly supervised monocular 3D detection framework that exploits depth information to achieve M3D with a single-view image exclusively without any 3D annotations or other training data. One key design in SKD-WM3D is a self-knowledge distillation framework, which transforms image features into 3D-like representations by fusing depth information and effectively mitigates the inherent depth ambiguity in monocular scenarios with little computational overhead in inference. In addition, we design an uncertainty-aware distillation loss and a gradient-targeted transfer modulation strategy which facilitate knowledge acquisition and knowledge transfer, respectively. Extensive experiments show that SKD-WM3D surpasses the state-of-the-art clearly and is even on par with many fully supervised methods.
LLMs Meet VLMs: Boost Open Vocabulary Object Detection with Fine-grained Descriptors
Feb 07, 2024Inspired by the outstanding zero-shot capability of vision language models (VLMs) in image classification tasks, open-vocabulary object detection has attracted increasing interest by distilling the broad VLM knowledge into detector training. However, most existing open-vocabulary detectors learn by aligning region embeddings with categorical labels (e.g., bicycle) only, disregarding the capability of VLMs on aligning visual embeddings with fine-grained text description of object parts (e.g., pedals and bells). This paper presents DVDet, a Descriptor-Enhanced Open Vocabulary Detector that introduces conditional context prompts and hierarchical textual descriptors that enable precise region-text alignment as well as open-vocabulary detection training in general. Specifically, the conditional context prompt transforms regional embeddings into image-like representations that can be directly integrated into general open vocabulary detection training. In addition, we introduce large language models as an interactive and implicit knowledge repository which enables iterative mining and refining visually oriented textual descriptors for precise region-text alignment. Extensive experiments over multiple large-scale benchmarks show that DVDet outperforms the state-of-the-art consistently by large margins.
Domain Generalization via Balancing Training Difficulty and Model Capability
Sep 02, 2023Domain generalization (DG) aims to learn domain-generalizable models from one or multiple source domains that can perform well in unseen target domains. Despite its recent progress, most existing work suffers from the misalignment between the difficulty level of training samples and the capability of contemporarily trained models, leading to over-fitting or under-fitting in the trained generalization model. We design MoDify, a Momentum Difficulty framework that tackles the misalignment by balancing the seesaw between the model's capability and the samples' difficulties along the training process. MoDify consists of two novel designs that collaborate to fight against the misalignment while learning domain-generalizable models. The first is MoDify-based Data Augmentation which exploits an RGB Shuffle technique to generate difficulty-aware training samples on the fly. The second is MoDify-based Network Optimization which dynamically schedules the training samples for balanced and smooth learning with appropriate difficulty. Without bells and whistles, a simple implementation of MoDify achieves superior performance across multiple benchmarks. In addition, MoDify can complement existing methods as a plug-in, and it is generic and can work for different visual recognition tasks.
Black-box Unsupervised Domain Adaptation with Bi-directional Atkinson-Shiffrin Memory
Aug 25, 2023Black-box unsupervised domain adaptation (UDA) learns with source predictions of target data without accessing either source data or source models during training, and it has clear superiority in data privacy and flexibility in target network selection. However, the source predictions of target data are often noisy and training with them is prone to learning collapses. We propose BiMem, a bi-directional memorization mechanism that learns to remember useful and representative information to correct noisy pseudo labels on the fly, leading to robust black-box UDA that can generalize across different visual recognition tasks. BiMem constructs three types of memory, including sensory memory, short-term memory, and long-term memory, which interact in a bi-directional manner for comprehensive and robust memorization of learnt features. It includes a forward memorization flow that identifies and stores useful features and a backward calibration flow that rectifies features' pseudo labels progressively. Extensive experiments show that BiMem achieves superior domain adaptation performance consistently across various visual recognition tasks such as image classification, semantic segmentation and object detection.