 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal 3D Reasoning Segmentation with Complex Scenes
Paper and Code
Nov 21, 2024

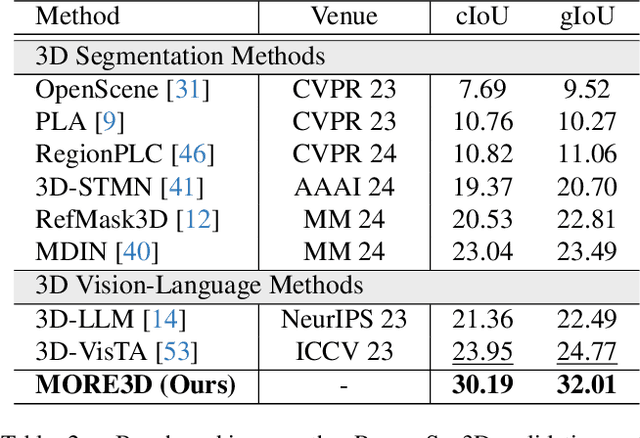

The recent development in multimodal learning has greatly advanced the research in 3D scene understanding in various real-world tasks such as embodied AI. However, most existing work shares two typical constraints: 1) they are short of reasoning ability for interaction and interpretation of human intension and 2) they focus on scenarios with single-category objects only which leads to over-simplified textual descriptions due to the negligence of multi-object scenarios and spatial relations among objects. We bridge the research gaps by proposing a 3D reasoning segmentation task for multiple objects in scenes. The task allows producing 3D segmentation masks and detailed textual explanations as enriched by 3D spatial relations among objects. To this end, we create ReasonSeg3D, a large-scale and high-quality benchmark that integrates 3D spatial relations with generated question-answer pairs and 3D segmentation masks. In addition, we design MORE3D, a simple yet effective method that enables multi-object 3D reasoning segmentation with user questions and textual outputs. Extensive experiments show that MORE3D excels in reasoning and segmenting complex multi-object 3D scenes, and the created ReasonSeg3D offers a valuable platform for future exploration of 3D reasoning segmentation. The dataset and code will be released.