 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrisma-World: Camera-Controllable Multi-Agent Video World Model
Jun 08, 2026Video world models have made rapid progress in generating controllable visual experiences, but most of them still simulate the world from a single observer. Extending such models to multiple agents raises a central challenge: if each agent's future state is generated independently, overlapping views may instantiate different versions of the same scene, leading to inconsistent objects, layouts, and appearances across agents. Conventional camera conditioning controls individual trajectories, but it does not explicitly couple the generation of views that should agree under shared scene geometry. We introduce Prisma-World, a camera-controllable multi-agent world model that formulates multi-agent generation as a joint geometry-aware denoising process for cross-view consistency. Prisma-World processes all agent videos within one full-attention sequence, uses a multi-agent RoPE design to distinguish agent identities while preserving synchronized temporal coordinates, and injects relative camera geometry into attention to bias overlapping viewpoints toward shared scene evidence. To further strengthen multi-view consistency and enhance global spatial perception, we augment our framework with an overlap-decaying curriculum training paradigm alongside minimap-conditioned structural guidance. To facilitate the training and evaluation of multi-agent models, we introduce PrismaDataset, a large-scale UE5 dataset with panoramic acquisition across diverse scenes, composable multi-agent view groups with flexible agent counts and complex camera trajectories, and precise camera/action annotations for consistency training and evaluation. Experiments show that a single Prisma-World model can generate high-fidelity multi-agent videos with flexible agent numbers, camera controllability, improved cross-view consistency, and spatial grounding under minimap guidance.
Knowledge Index of Noah's Ark
Jun 04, 2026Knowledge benchmarks for LLMs face three issues: scaling-driven designs that do not operationalize disciplinary representativeness; flat-payment annotation that permits lazy consensus; and unaudited ranking instability under bounded test budgets. We introduce KINA, an 899-item benchmark across 261 fine-grained disciplines, with two formal results. First, we cast representativeness as a coverage-style objective over expert-elicited anchors and operationalize disciplinary representativeness through a proxy, yielding a (1-1/e) greedy approximation (Proposition 1); the guarantee applies to the proxy, not to population representativeness. Second, we prove a bonus-on-bar tournament weakly FOSD-dominates flat payment in released-review quality, with incentive-compatibility threshold B > Delta C / Delta p_min (Theorem 1). Evaluating 42 models from 13 labs, the top model, Gemini-3.1-Pro-Preview, reaches 53.17%, followed by Claude-Opus-4.6 at 49.92% and GPT-5.4 at 48.55%, leaving substantial headroom below saturation. The full leaderboard shows a tiered structure rather than a smooth total order: a small frontier tier lies above 48%, a dense strong-model tier spans roughly 38-45%, and low-performing models remain only modestly above the 10% chance baseline. Tool augmentation adds up to 5.17 points across the five tool-use evaluations, with gains varying substantially across models. We report bootstrap ranking-stability statistics to make bounded-budget variance explicit and to discourage over-interpretation of adjacent ranks.
UniCAD: A Unified Benchmark and Universal Model for Multi-Modal Multi-Task CAD
Jun 03, 2026Computer-Aided Design (CAD) underpins modern engineering and manufacturing by enabling the creation of precise, editable 3D models. However, CAD research typically studies tasks in isolation, and multi-modal, multi-task learning for CAD is hindered by the absence of a unified benchmark. To address this gap, we introduce UniCAD, a comprehensive benchmark for multi-modal CAD learning that covers point-to-CAD reconstruction, text/image-to-CAD generation, and CAD question answering across diverse input modalities. Alongside the benchmark, we present UniCAD-MLLM, a universal multi-modal large language model that ingests text, images, sketches, and point clouds and performs these heterogeneous tasks in an end-to-end fashion within a single framework. Extensive experiments on the UniCAD and Fusion360 benchmarks demonstrate that UniCAD-MLLM achieves state-of-the-art performance across all tasks, outperforming existing task-specific and multi-task baselines. We will release the dataset, code, and pretrained models to accelerate future research.
Knowledge Visualization: A Benchmark and Method for Knowledge-Intensive Text-to-Image Generation
Apr 24, 2026Recent text-to-image (T2I) models have demonstrated impressive capabilities in photorealistic synthesis and instruction following. However, their reliability in knowledge-intensive settings remains largely unexplored. Unlike natural image generation, knowledge visualization requires not only semantic alignment but also strict adherence to domain knowledge, structural constraints, and symbolic conventions, exposing a critical gap between visual plausibility and scientific correctness. To systematically study this problem, we introduce KVBench, a curriculum-grounded benchmark for evaluating knowledge-intensive T2I generation. KVBench covers six senior high-school subjects: Biology, Chemistry, Geography, History, Mathematics, and Physics. The benchmark consists of 1,800 expert-curated prompts derived from over 30 authoritative textbooks. Using this benchmark, we evaluate 14 state-of-the-art open- and closed-source models, revealing substantial deficiencies in logical reasoning, symbolic precision, and multilingual robustness, with open-source models consistently underperforming proprietary systems. To address these limitations, we further propose KE-Check, a two-stage framework that improves scientific fidelity via (1) Knowledge Elaboration for structured prompt enrichment, and (2) Checklist-Guided Refinement for explicit constraint enforcement through violation identification and constraint-guided editing. KE-Check effectively mitigates scientific hallucinations, narrowing the performance gap between open-source and leading closed-source models. Data and codes are publicly available at https://github.com/zhaoran66/KVBench.
Video-KTR: Reinforcing Video Reasoning via Key Token Attribution
Jan 27, 2026Reinforcement learning (RL) has shown strong potential for enhancing reasoning in multimodal large language models, yet existing video reasoning methods often rely on coarse sequence-level rewards or single-factor token selection, neglecting fine-grained links among visual inputs, temporal dynamics, and linguistic outputs, limiting both accuracy and interpretability. We propose Video-KTR, a modality-aware policy shaping framework that performs selective, token-level RL by combining three attribution signals: (1) visual-aware tokens identified via counterfactual masking to reveal perceptual dependence; (2) temporal-aware tokens detected through frame shuffling to expose temporal sensitivity; and (3) high-entropy tokens signaling predictive uncertainty. By reinforcing only these key tokens, Video-KTR focuses learning on semantically informative, modality-sensitive content while filtering out low-value tokens. Across five challenging benchmarks, Video-KTR achieves state-of-the-art or highly competitive results, achieving 42.7\% on Video-Holmes (surpassing GPT-4o) with consistent gains on both reasoning and general video understanding tasks. Ablation studies verify the complementary roles of the attribution signals and the robustness of targeted token-level updates. Overall, Video-KTR improves accuracy and interpretability, offering a simple, drop-in extension to RL for complex video reasoning. Our code and models are available at https://github.com/zywang0104/Video-KTR.
JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
Dec 28, 2025This paper presents JavisGPT, the first unified multimodal large language model (MLLM) for Joint Audio-Video (JAV) comprehension and generation. JavisGPT adopts a concise encoder-LLM-decoder architecture, featuring a SyncFusion module for spatio-temporal audio-video fusion and synchrony-aware learnable queries to bridge a pretrained JAV-DiT generator. This design enables temporally coherent video-audio understanding and generation from multimodal instructions. We design an effective three-stage training pipeline consisting of multimodal pretraining, audio-video fine-tuning, and large-scale instruction-tuning, to progressively build multimodal comprehension and generation from existing vision-language models. To support this, we further construct JavisInst-Omni, a high-quality instruction dataset with over 200K GPT-4o-curated audio-video-text dialogues that span diverse and multi-level comprehension and generation scenarios. Extensive experiments on JAV comprehension and generation benchmarks show that JavisGPT outperforms existing MLLMs, particularly in complex and temporally synchronized settings.
EduGuardBench: A Holistic Benchmark for Evaluating the Pedagogical Fidelity and Adversarial Safety of LLMs as Simulated Teachers
Nov 10, 2025Large Language Models for Simulating Professions (SP-LLMs), particularly as teachers, are pivotal for personalized education. However, ensuring their professional competence and ethical safety is a critical challenge, as existing benchmarks fail to measure role-playing fidelity or address the unique teaching harms inherent in educational scenarios. To address this, we propose EduGuardBench, a dual-component benchmark. It assesses professional fidelity using a Role-playing Fidelity Score (RFS) while diagnosing harms specific to the teaching profession. It also probes safety vulnerabilities using persona-based adversarial prompts targeting both general harms and, particularly, academic misconduct, evaluated with metrics including Attack Success Rate (ASR) and a three-tier Refusal Quality assessment. Our extensive experiments on 14 leading models reveal a stark polarization in performance. While reasoning-oriented models generally show superior fidelity, incompetence remains the dominant failure mode across most models. The adversarial tests uncovered a counterintuitive scaling paradox, where mid-sized models can be the most vulnerable, challenging monotonic safety assumptions. Critically, we identified a powerful Educational Transformation Effect: the safest models excel at converting harmful requests into teachable moments by providing ideal Educational Refusals. This capacity is strongly negatively correlated with ASR, revealing a new dimension of advanced AI safety. EduGuardBench thus provides a reproducible framework that moves beyond siloed knowledge tests toward a holistic assessment of professional, ethical, and pedagogical alignment, uncovering complex dynamics essential for deploying trustworthy AI in education. See https://github.com/YL1N/EduGuardBench for Materials.
EMNLP: Educator-role Moral and Normative Large Language Models Profiling
Aug 21, 2025Simulating Professions (SP) enables Large Language Models (LLMs) to emulate professional roles. However, comprehensive psychological and ethical evaluation in these contexts remains lacking. This paper introduces EMNLP, an Educator-role Moral and Normative LLMs Profiling framework for personality profiling, moral development stage measurement, and ethical risk under soft prompt injection. EMNLP extends existing scales and constructs 88 teacher-specific moral dilemmas, enabling profession-oriented comparison with human teachers. A targeted soft prompt injection set evaluates compliance and vulnerability in teacher SP. Experiments on 12 LLMs show teacher-role LLMs exhibit more idealized and polarized personalities than human teachers, excel in abstract moral reasoning, but struggle with emotionally complex situations. Models with stronger reasoning are more vulnerable to harmful prompt injection, revealing a paradox between capability and safety. The model temperature and other hyperparameters have limited influence except in some risk behaviors. This paper presents the first benchmark to assess ethical and psychological alignment of teacher-role LLMs for educational AI. Resources are available at https://e-m-n-l-p.github.io/.
OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation
May 29, 2025In this report, we present OpenUni, a simple, lightweight, and fully open-source baseline for unifying multimodal understanding and generation. Inspired by prevailing practices in unified model learning, we adopt an efficient training strategy that minimizes the training complexity and overhead by bridging the off-the-shelf multimodal large language models (LLMs) and diffusion models through a set of learnable queries and a light-weight transformer-based connector. With a minimalist choice of architecture, we demonstrate that OpenUni can: 1) generate high-quality and instruction-aligned images, and 2) achieve exceptional performance on standard benchmarks such as GenEval, DPG- Bench, and WISE, with only 1.1B and 3.1B activated parameters. To support open research and community advancement, we release all model weights, training code, and our curated training datasets (including 23M image-text pairs) at https://github.com/wusize/OpenUni.
Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
Mar 27, 2025
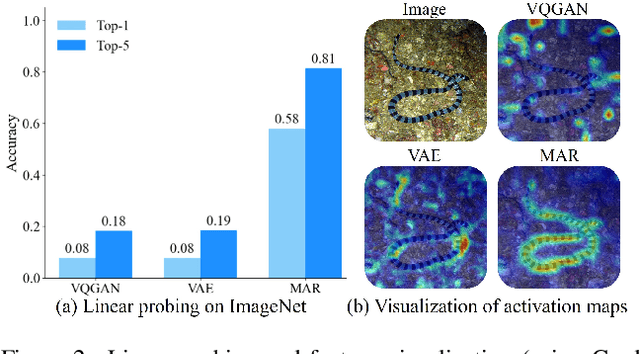
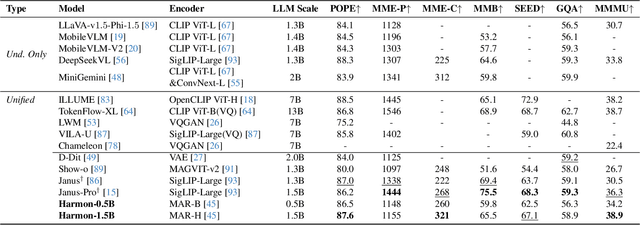
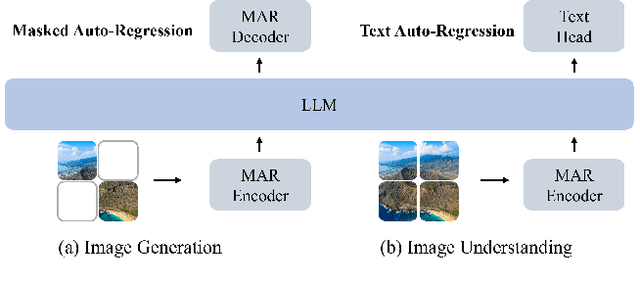
Unifying visual understanding and generation within a single multimodal framework remains a significant challenge, as the two inherently heterogeneous tasks require representations at different levels of granularity. Current approaches that utilize vector quantization (VQ) or variational autoencoders (VAE) for unified visual representation prioritize intrinsic imagery features over semantics, compromising understanding performance. In this work, we take inspiration from masked image modelling (MIM) that learns rich semantics via a mask-and-reconstruct pre-training and its successful extension to masked autoregressive (MAR) image generation. A preliminary study on the MAR encoder's representation reveals exceptional linear probing accuracy and precise feature response to visual concepts, which indicates MAR's potential for visual understanding tasks beyond its original generation role. Based on these insights, we present \emph{Harmon}, a unified autoregressive framework that harmonizes understanding and generation tasks with a shared MAR encoder. Through a three-stage training procedure that progressively optimizes understanding and generation capabilities, Harmon achieves state-of-the-art image generation results on the GenEval, MJHQ30K and WISE benchmarks while matching the performance of methods with dedicated semantic encoders (e.g., Janus) on image understanding benchmarks. Our code and models will be available at https://github.com/wusize/Harmon.