 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSparse: Training-Aware Fine-Grained Sparse Attention for Long-Video MLLMs
Nov 18, 2025Existing sparse attention methods primarily target inference-time acceleration by selecting critical tokens under predefined sparsity patterns. However, they often fail to bridge the training-inference gap and lack the capacity for fine-grained token selection across multiple dimensions such as queries, key-values (KV), and heads, leading to suboptimal performance and limited acceleration gains. In this paper, we introduce OmniSparse, a training-aware fine-grained sparse attention framework for long-video MLLMs, which operates in both training and inference with dynamic token budget allocation. Specifically, OmniSparse contains three adaptive and complementary mechanisms: (1) query selection via lazy-active classification, retaining active queries that capture broad semantic similarity while discarding most lazy ones that focus on limited local context and exhibit high functional redundancy; (2) KV selection with head-level dynamic budget allocation, where a shared budget is determined based on the flattest head and applied uniformly across all heads to ensure attention recall; and (3) KV cache slimming to reduce head-level redundancy by selectively fetching visual KV cache according to the head-level decoding query pattern. Experimental results show that OmniSparse matches the performance of full attention while achieving up to 2.7x speedup during prefill and 2.4x memory reduction during decoding.
ACT as Human: Multimodal Large Language Model Data Annotation with Critical Thinking
Nov 13, 2025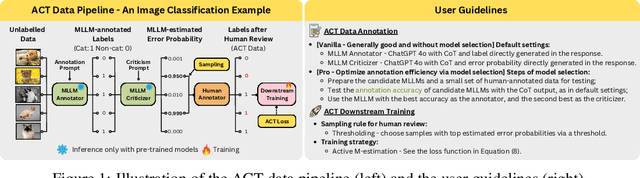



Supervised learning relies on high-quality labeled data, but obtaining such data through human annotation is both expensive and time-consuming. Recent work explores using large language models (LLMs) for annotation, but LLM-generated labels still fall short of human-level quality. To address this problem, we propose the Annotation with Critical Thinking (ACT) data pipeline, where LLMs serve not only as annotators but also as judges to critically identify potential errors. Human effort is then directed towards reviewing only the most "suspicious" cases, significantly improving the human annotation efficiency. Our major contributions are as follows: (1) ACT is applicable to a wide range of domains, including natural language processing (NLP), computer vision (CV), and multimodal understanding, by leveraging multimodal-LLMs (MLLMs). (2) Through empirical studies, we derive 7 insights on how to enhance annotation quality while efficiently reducing the human cost, and then translate these findings into user-friendly guidelines. (3) We theoretically analyze how to modify the loss function so that models trained on ACT data achieve similar performance to those trained on fully human-annotated data. Our experiments show that the performance gap can be reduced to less than 2% on most benchmark datasets while saving up to 90% of human costs.
Agent-Centric Personalized Multiple Clustering with Multi-Modal LLMs
Mar 31, 2025Personalized multiple clustering aims to generate diverse partitions of a dataset based on different user-specific aspects, rather than a single clustering. It has recently drawn research interest for accommodating varying user preferences. Recent approaches primarily use CLIP embeddings with proxy learning to extract representations biased toward user clustering preferences. However, CLIP primarily focuses on coarse image-text alignment, lacking a deep contextual understanding of user interests. To overcome these limitations, we propose an agent-centric personalized clustering framework that leverages multi-modal large language models (MLLMs) as agents to comprehensively traverse a relational graph to search for clusters based on user interests. Due to the advanced reasoning mechanism of MLLMs, the obtained clusters align more closely with user-defined criteria than those obtained from CLIP-based representations. To reduce computational overhead, we shorten the agents' traversal path by constructing a relational graph using user-interest-biased embeddings extracted by MLLMs. A large number of weakly connected edges can be filtered out based on embedding similarity, facilitating an efficient traversal search for agents. Experimental results show that the proposed method achieves NMI scores of 0.9667 and 0.9481 on the Card Order and Card Suits benchmarks, respectively, largely improving the SOTA model by over 140%.
Exploring the Role of Explicit Temporal Modeling in Multimodal Large Language Models for Video Understanding
Jan 28, 2025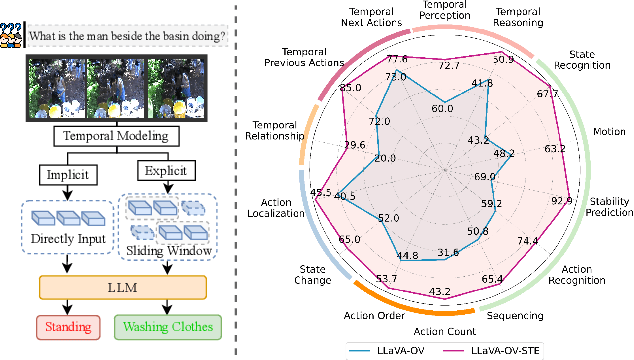
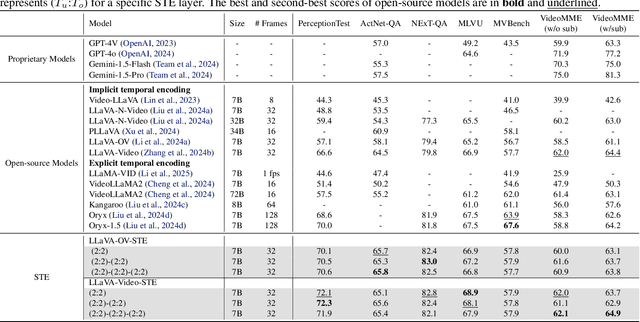
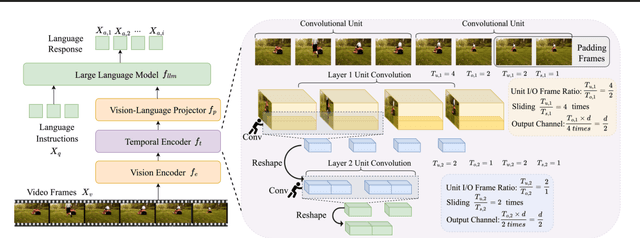
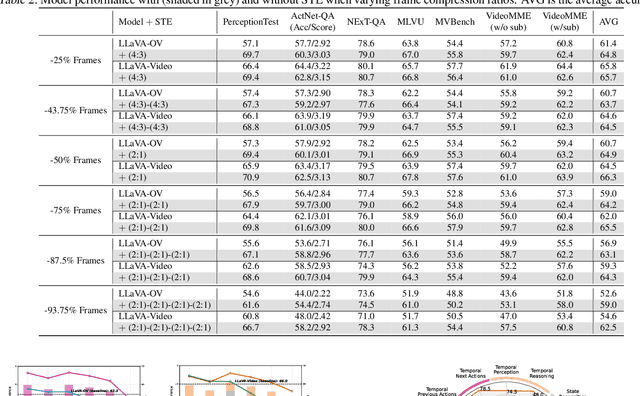
Applying Multimodal Large Language Models (MLLMs) to video understanding presents significant challenges due to the need to model temporal relations across frames. Existing approaches adopt either implicit temporal modeling, relying solely on the LLM decoder, or explicit temporal modeling, employing auxiliary temporal encoders. To investigate this debate between the two paradigms, we propose the Stackable Temporal Encoder (STE). STE enables flexible explicit temporal modeling with adjustable temporal receptive fields and token compression ratios. Using STE, we systematically compare implicit and explicit temporal modeling across dimensions such as overall performance, token compression effectiveness, and temporal-specific understanding. We also explore STE's design considerations and broader impacts as a plug-in module and in image modalities. Our findings emphasize the critical role of explicit temporal modeling, providing actionable insights to advance video MLLMs.
Evaluating and Advancing Multimodal Large Language Models in Ability Lens
Nov 22, 2024As multimodal large language models (MLLMs) advance rapidly, rigorous evaluation has become essential, providing further guidance for their development. In this work, we focus on a unified and robust evaluation of \textbf{vision perception} abilities, the foundational skill of MLLMs. We find that existing perception benchmarks, each focusing on different question types, domains, and evaluation metrics, introduce significant evaluation variance, complicating comprehensive assessments of perception abilities when relying on any single benchmark. To address this, we introduce \textbf{AbilityLens}, a unified benchmark designed to evaluate MLLMs across six key perception abilities, focusing on both accuracy and stability, with each ability encompassing diverse question types, domains, and metrics. With the assistance of AbilityLens, we: (1) identify the strengths and weaknesses of current models, highlighting stability patterns and revealing a notable performance gap between open-source and closed-source models; (2) introduce an online evaluation mode, which uncovers interesting ability conflict and early convergence phenomena during MLLM training; and (3) design a simple ability-specific model merging method that combines the best ability checkpoint from early training stages, effectively mitigating performance decline due to ability conflict. The benchmark and online leaderboard will be released soon.
Frame-Voyager: Learning to Query Frames for Video Large Language Models
Oct 07, 2024Video Large Language Models (Video-LLMs) have made remarkable progress in video understanding tasks. However, they are constrained by the maximum length of input tokens, making it impractical to input entire videos. Existing frame selection approaches, such as uniform frame sampling and text-frame retrieval, fail to account for the information density variations in the videos or the complex instructions in the tasks, leading to sub-optimal performance. In this paper, we propose Frame-Voyager that learns to query informative frame combinations, based on the given textual queries in the task. To train Frame-Voyager, we introduce a new data collection and labeling pipeline, by ranking frame combinations using a pre-trained Video-LLM. Given a video of M frames, we traverse its T-frame combinations, feed them into a Video-LLM, and rank them based on Video-LLM's prediction losses. Using this ranking as supervision, we train Frame-Voyager to query the frame combinations with lower losses. In experiments, we evaluate Frame-Voyager on four Video Question Answering benchmarks by plugging it into two different Video-LLMs. The experimental results demonstrate that Frame-Voyager achieves impressive results in all settings, highlighting its potential as a plug-and-play solution for Video-LLMs.
Effectively Enhancing Vision Language Large Models by Prompt Augmentation and Caption Utilization
Sep 22, 2024Recent studies have shown that Vision Language Large Models (VLLMs) may output content not relevant to the input images. This problem, called the hallucination phenomenon, undoubtedly degrades VLLM performance. Therefore, various anti-hallucination techniques have been proposed to make model output more reasonable and accurate. Despite their successes, from extensive tests we found that augmenting the prompt (e.g. word appending, rewriting, and spell error etc.) may change model output and make the output hallucinate again. To cure this drawback, we propose a new instruct-tuning framework called Prompt Augmentation and Caption Utilization (PACU) to boost VLLM's generation ability under the augmented prompt scenario. Concretely, on the one hand, PACU exploits existing LLMs to augment and evaluate diverse prompts automatically. The resulting high-quality prompts are utilized to enhance VLLM's ability to process different prompts. On the other hand, PACU exploits image captions to jointly work with image features as well as the prompts for response generation. When the visual feature is inaccurate, LLM can capture useful information from the image captions for response generation. Extensive experiments on hallucination evaluation and prompt-augmented datasets demonstrate that our PACU method can work well with existing schemes to effectively boost VLLM model performance. Code is available in https://github.com/zhaominyiz/PACU.
Context-Aware Prompt Tuning for Vision-Language Model with Dual-Alignment
Sep 08, 2023
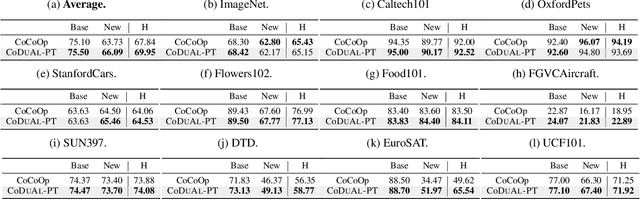
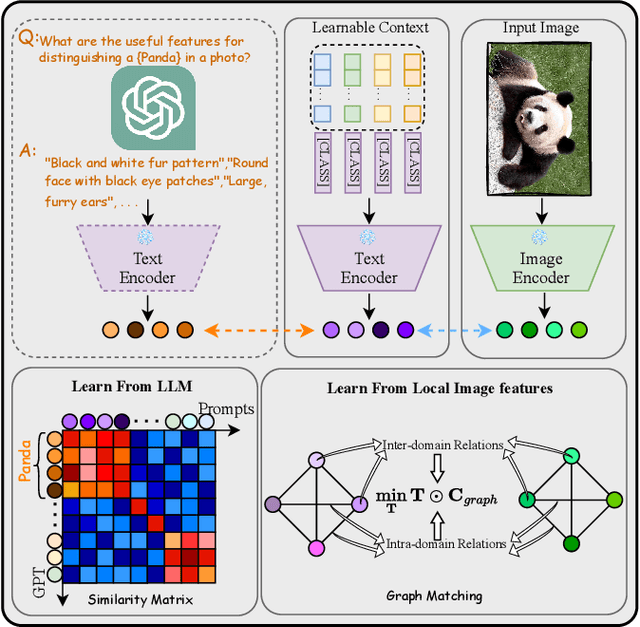
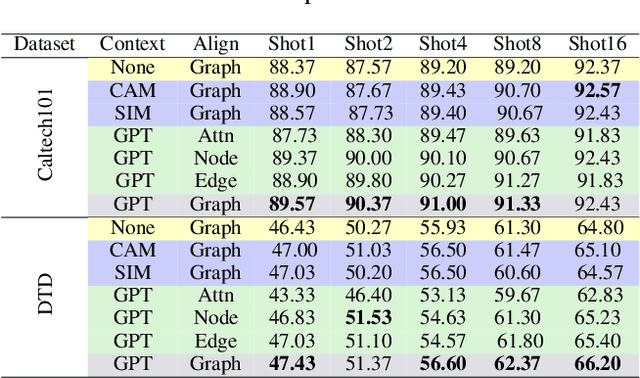
Large-scale vision-language models (VLMs), e.g., CLIP, learn broad visual concepts from tedious training data, showing superb generalization ability. Amount of prompt learning methods have been proposed to efficiently adapt the VLMs to downstream tasks with only a few training samples. We introduce a novel method to improve the prompt learning of vision-language models by incorporating pre-trained large language models (LLMs), called Dual-Aligned Prompt Tuning (DuAl-PT). Learnable prompts, like CoOp, implicitly model the context through end-to-end training, which are difficult to control and interpret. While explicit context descriptions generated by LLMs, like GPT-3, can be directly used for zero-shot classification, such prompts are overly relying on LLMs and still underexplored in few-shot domains. With DuAl-PT, we propose to learn more context-aware prompts, benefiting from both explicit and implicit context modeling. To achieve this, we introduce a pre-trained LLM to generate context descriptions, and we encourage the prompts to learn from the LLM's knowledge by alignment, as well as the alignment between prompts and local image features. Empirically, DuAl-PT achieves superior performance on 11 downstream datasets on few-shot recognition and base-to-new generalization. Hopefully, DuAl-PT can serve as a strong baseline. Code will be available.
CIEM: Contrastive Instruction Evaluation Method for Better Instruction Tuning
Sep 05, 2023



Nowadays, the research on Large Vision-Language Models (LVLMs) has been significantly promoted thanks to the success of Large Language Models (LLM). Nevertheless, these Vision-Language Models (VLMs) are suffering from the drawback of hallucination -- due to insufficient understanding of vision and language modalities, VLMs may generate incorrect perception information when doing downstream applications, for example, captioning a non-existent entity. To address the hallucination phenomenon, on the one hand, we introduce a Contrastive Instruction Evaluation Method (CIEM), which is an automatic pipeline that leverages an annotated image-text dataset coupled with an LLM to generate factual/contrastive question-answer pairs for the evaluation of the hallucination of VLMs. On the other hand, based on CIEM, we further propose a new instruction tuning method called CIT (the abbreviation of Contrastive Instruction Tuning) to alleviate the hallucination of VLMs by automatically producing high-quality factual/contrastive question-answer pairs and corresponding justifications for model tuning. Through extensive experiments on CIEM and CIT, we pinpoint the hallucination issues commonly present in existing VLMs, the disability of the current instruction-tuning dataset to handle the hallucination phenomenon and the superiority of CIT-tuned VLMs over both CIEM and public datasets.
HIRL: A General Framework for Hierarchical Image Representation Learning
May 26, 2022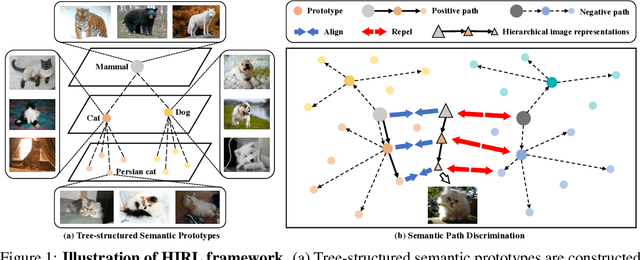
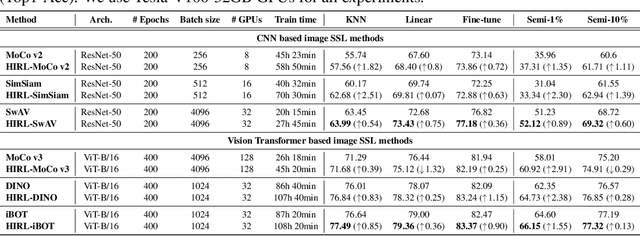


Learning self-supervised image representations has been broadly studied to boost various visual understanding tasks. Existing methods typically learn a single level of image semantics like pairwise semantic similarity or image clustering patterns. However, these methods can hardly capture multiple levels of semantic information that naturally exists in an image dataset, e.g., the semantic hierarchy of "Persian cat to cat to mammal" encoded in an image database for species. It is thus unknown whether an arbitrary image self-supervised learning (SSL) approach can benefit from learning such hierarchical semantics. To answer this question, we propose a general framework for Hierarchical Image Representation Learning (HIRL). This framework aims to learn multiple semantic representations for each image, and these representations are structured to encode image semantics from fine-grained to coarse-grained. Based on a probabilistic factorization, HIRL learns the most fine-grained semantics by an off-the-shelf image SSL approach and learns multiple coarse-grained semantics by a novel semantic path discrimination scheme. We adopt six representative image SSL methods as baselines and study how they perform under HIRL. By rigorous fair comparison, performance gain is observed on all the six methods for diverse downstream tasks, which, for the first time, verifies the general effectiveness of learning hierarchical image semantics. All source code and model weights are available at https://github.com/hirl-team/HIRL