 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIRL: A General Framework for Hierarchical Image Representation Learning
May 26, 2022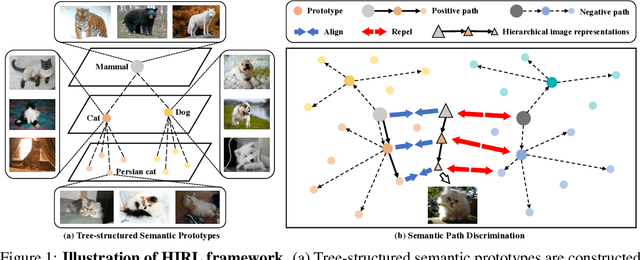
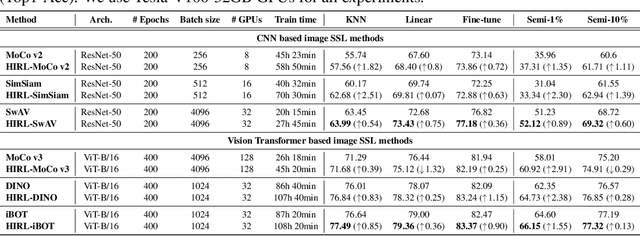


Learning self-supervised image representations has been broadly studied to boost various visual understanding tasks. Existing methods typically learn a single level of image semantics like pairwise semantic similarity or image clustering patterns. However, these methods can hardly capture multiple levels of semantic information that naturally exists in an image dataset, e.g., the semantic hierarchy of "Persian cat to cat to mammal" encoded in an image database for species. It is thus unknown whether an arbitrary image self-supervised learning (SSL) approach can benefit from learning such hierarchical semantics. To answer this question, we propose a general framework for Hierarchical Image Representation Learning (HIRL). This framework aims to learn multiple semantic representations for each image, and these representations are structured to encode image semantics from fine-grained to coarse-grained. Based on a probabilistic factorization, HIRL learns the most fine-grained semantics by an off-the-shelf image SSL approach and learns multiple coarse-grained semantics by a novel semantic path discrimination scheme. We adopt six representative image SSL methods as baselines and study how they perform under HIRL. By rigorous fair comparison, performance gain is observed on all the six methods for diverse downstream tasks, which, for the first time, verifies the general effectiveness of learning hierarchical image semantics. All source code and model weights are available at https://github.com/hirl-team/HIRL
BFRnet: A deep learning-based MR background field removal method for QSM of the brain containing significant pathological susceptibility sources
Apr 06, 2022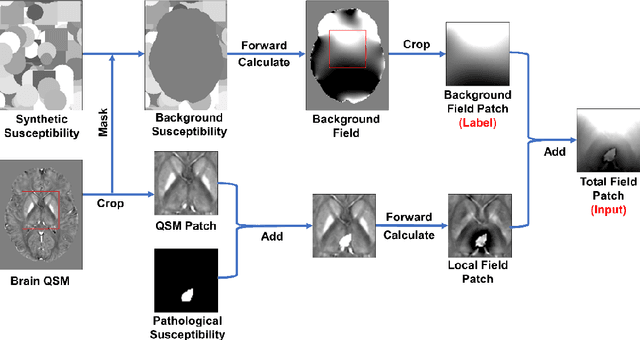

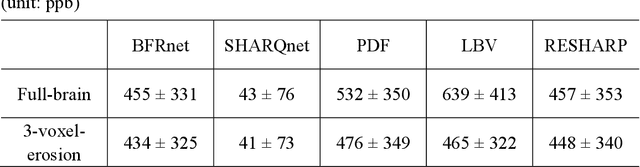
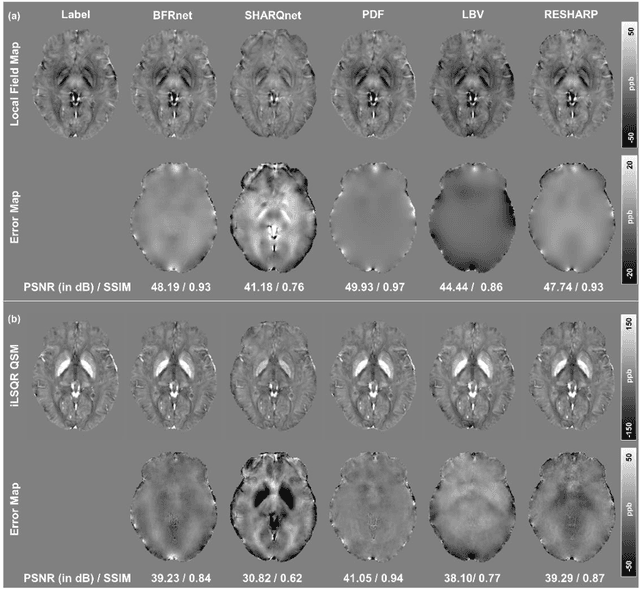
Introduction: Background field removal (BFR) is a critical step required for successful quantitative susceptibility mapping (QSM). However, eliminating the background field in brains containing significant susceptibility sources, such as intracranial hemorrhages, is challenging due to the relatively large scale of the field induced by these pathological susceptibility sources. Method: This study proposes a new deep learning-based method, BFRnet, to remove background field in healthy and hemorrhagic subjects. The network is built with the dual-frequency octave convolutions on the U-net architecture, trained with synthetic field maps containing significant susceptibility sources. The BFRnet method is compared with three conventional BFR methods and one previous deep learning method using simulated and in vivo brains from 4 healthy and 2 hemorrhagic subjects. Robustness against acquisition field-of-view (FOV) orientation and brain masking are also investigated. Results: For both simulation and in vivo experiments, BFRnet led to the best visually appealing results in the local field and QSM results with the minimum contrast loss and the most accurate hemorrhage susceptibility measurements among all five methods. In addition, BFRnet produced the most consistent local field and susceptibility maps between different sizes of brain masks, while conventional methods depend drastically on precise brain extraction and further brain edge erosions. It is also observed that BFRnet performed the best among all BFR methods for acquisition FOVs oblique to the main magnetic field. Conclusion: The proposed BFRnet improved the accuracy of local field reconstruction in the hemorrhagic subjects compared with conventional BFR algorithms. The BFRnet method was effective for acquisitions of titled orientations and retained whole brains without edge erosion as often required by traditional BFR methods.
HCSC: Hierarchical Contrastive Selective Coding
Feb 01, 2022
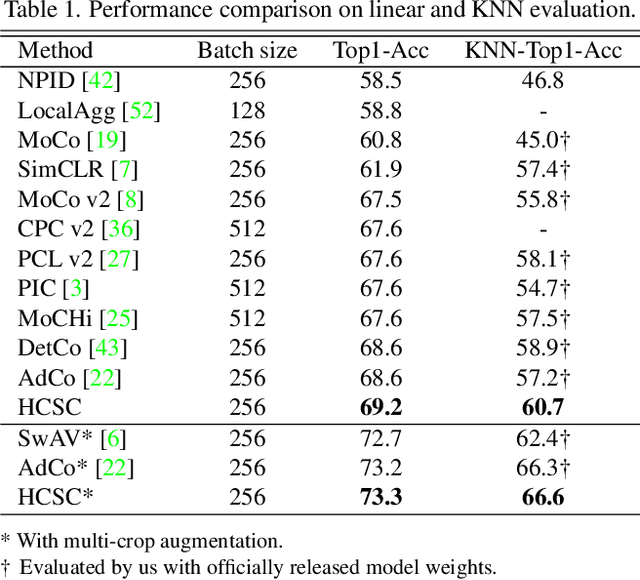

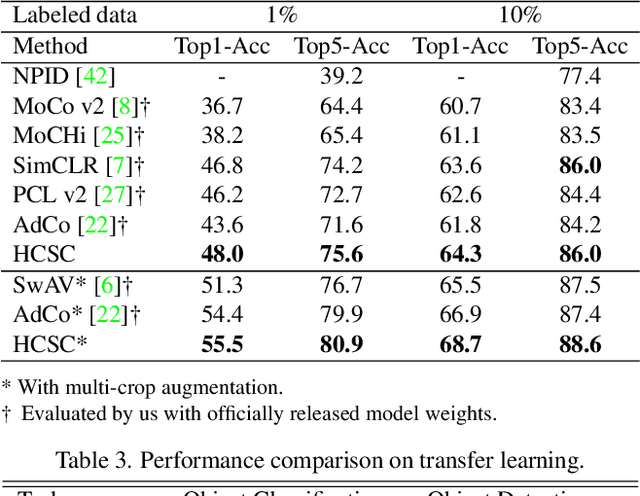
Hierarchical semantic structures naturally exist in an image dataset, in which several semantically relevant image clusters can be further integrated into a larger cluster with coarser-grained semantics. Capturing such structures with image representations can greatly benefit the semantic understanding on various downstream tasks. Existing contrastive representation learning methods lack such an important model capability. In addition, the negative pairs used in these methods are not guaranteed to be semantically distinct, which could further hamper the structural correctness of learned image representations. To tackle these limitations, we propose a novel contrastive learning framework called Hierarchical Contrastive Selective Coding (HCSC). In this framework, a set of hierarchical prototypes are constructed and also dynamically updated to represent the hierarchical semantic structures underlying the data in the latent space. To make image representations better fit such semantic structures, we employ and further improve conventional instance-wise and prototypical contrastive learning via an elaborate pair selection scheme. This scheme seeks to select more diverse positive pairs with similar semantics and more precise negative pairs with truly distinct semantics. On extensive downstream tasks, we verify the superior performance of HCSC over state-of-the-art contrastive methods, and the effectiveness of major model components is proved by plentiful analytical studies. Our source code and model weights are available at https://github.com/gyfastas/HCSC
Quaternion Convolutional Neural Networks
Mar 02, 2019

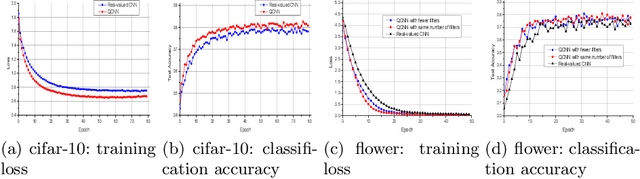

Neural networks in the real domain have been studied for a long time and achieved promising results in many vision tasks for recent years. However, the extensions of the neural network models in other number fields and their potential applications are not fully-investigated yet. Focusing on color images, which can be naturally represented as quaternion matrices, we propose a quaternion convolutional neural network (QCNN) model to obtain more representative features. In particular, we redesign the basic modules like convolution layer and fully-connected layer in the quaternion domain, which can be used to establish fully-quaternion convolutional neural networks. Moreover, these modules are compatible with almost all deep learning techniques and can be plugged into traditional CNNs easily. We test our QCNN models in both color image classification and denoising tasks. Experimental results show that they outperform the real-valued CNNs with same structures.