 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Role of Explicit Temporal Modeling in Multimodal Large Language Models for Video Understanding
Jan 28, 2025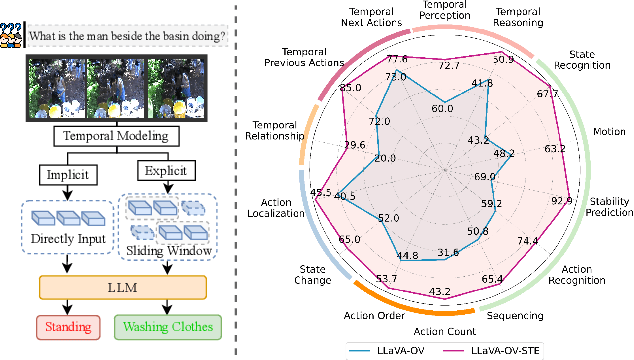
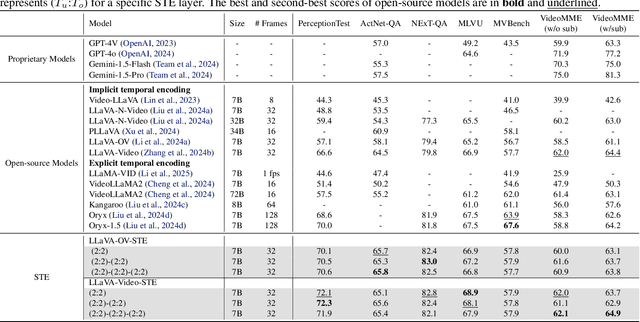
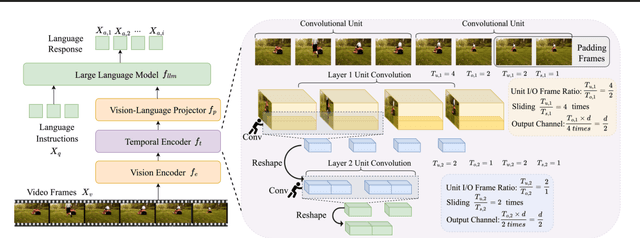
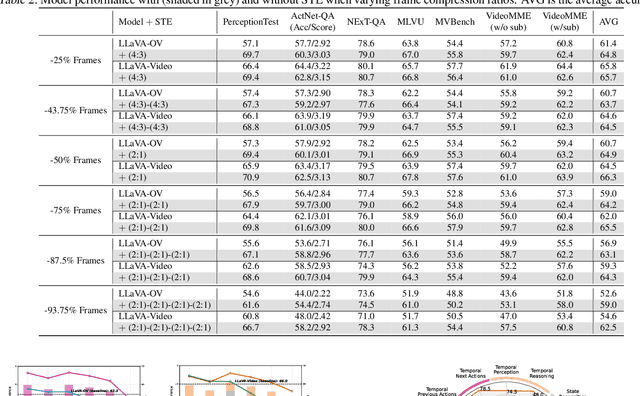
Applying Multimodal Large Language Models (MLLMs) to video understanding presents significant challenges due to the need to model temporal relations across frames. Existing approaches adopt either implicit temporal modeling, relying solely on the LLM decoder, or explicit temporal modeling, employing auxiliary temporal encoders. To investigate this debate between the two paradigms, we propose the Stackable Temporal Encoder (STE). STE enables flexible explicit temporal modeling with adjustable temporal receptive fields and token compression ratios. Using STE, we systematically compare implicit and explicit temporal modeling across dimensions such as overall performance, token compression effectiveness, and temporal-specific understanding. We also explore STE's design considerations and broader impacts as a plug-in module and in image modalities. Our findings emphasize the critical role of explicit temporal modeling, providing actionable insights to advance video MLLMs.
A First Running Time Analysis of the Strength Pareto Evolutionary Algorithm 2 (SPEA2)
Jun 23, 2024Evolutionary algorithms (EAs) have emerged as a predominant approach for addressing multi-objective optimization problems. However, the theoretical foundation of multi-objective EAs (MOEAs), particularly the fundamental aspects like running time analysis, remains largely underexplored. Existing theoretical studies mainly focus on basic MOEAs, with little attention given to practical MOEAs. In this paper, we present a running time analysis of strength Pareto evolutionary algorithm 2 (SPEA2) for the first time. Specifically, we prove that the expected running time of SPEA2 for solving three commonly used multi-objective problems, i.e., $m$OneMinMax, $m$LeadingOnesTrailingZeroes, and $m$-OneJumpZeroJump, is $O(\mu n\cdot \min\{m\log n, n\})$, $O(\mu n^2)$, and $O(\mu n^k \cdot \min\{mn, 3^{m/2}\})$, respectively. Here $m$ denotes the number of objectives, and the population size $\mu$ is required to be at least $(2n/m+1)^{m/2}$, $(2n/m+1)^{m-1}$ and $(2n/m-2k+3)^{m/2}$, respectively. The proofs are accomplished through general theorems which are also applicable for analyzing the expected running time of other MOEAs on these problems, and thus can be helpful for future theoretical analysis of MOEAs.
Maintaining Diversity Provably Helps in Evolutionary Multimodal Optimization
Jun 04, 2024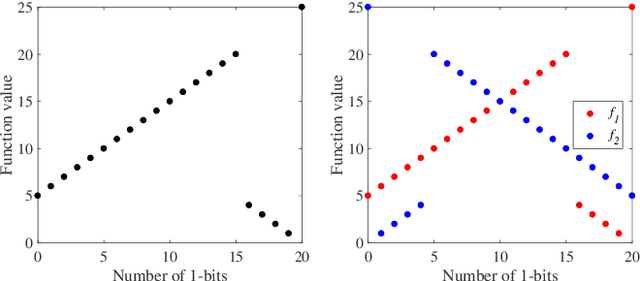
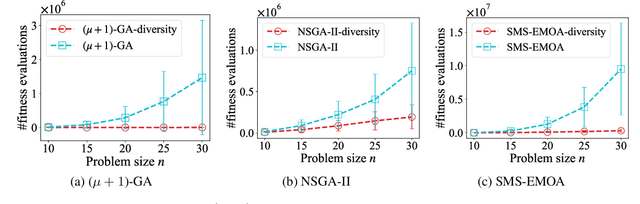
In the real world, there exist a class of optimization problems that multiple (local) optimal solutions in the solution space correspond to a single point in the objective space. In this paper, we theoretically show that for such multimodal problems, a simple method that considers the diversity of solutions in the solution space can benefit the search in evolutionary algorithms (EAs). Specifically, we prove that the proposed method, working with crossover, can help enhance the exploration, leading to polynomial or even exponential acceleration on the expected running time. This result is derived by rigorous running time analysis in both single-objective and multi-objective scenarios, including $(\mu+1)$-GA solving the widely studied single-objective problem, Jump, and NSGA-II and SMS-EMOA (two well-established multi-objective EAs) solving the widely studied bi-objective problem, OneJumpZeroJump. Experiments are also conducted to validate the theoretical results. We hope that our results may encourage the exploration of diversity maintenance in the solution space for multi-objective optimization, where existing EAs usually only consider the diversity in the objective space and can easily be trapped in local optima.
An Archive Can Bring Provable Speed-ups in Multi-Objective Evolutionary Algorithms
Jun 04, 2024In the area of multi-objective evolutionary algorithms (MOEAs), there is a trend of using an archive to store non-dominated solutions generated during the search. This is because 1) MOEAs may easily end up with the final population containing inferior solutions that are dominated by other solutions discarded during the search process and 2) the population that has a commensurable size of the problem's Pareto front is often not practical. In this paper, we theoretically show, for the first time, that using an archive can guarantee speed-ups for MOEAs. Specifically, we prove that for two well-established MOEAs (NSGA-II and SMS-EMOA) on two commonly studied problems (OneMinMax and LeadingOnesTrailingZeroes), using an archive brings a polynomial acceleration on the expected running time. The reason is that with an archive, the size of the population can reduce to a small constant; there is no need for the population to keep all the Pareto optimal solutions found. This contrasts existing theoretical studies for MOEAs where a population with a commensurable size of the problem's Pareto front is needed. The findings in this paper not only provide a theoretical confirmation for an increasingly popular practice in the design of MOEAs, but can also be beneficial to the theory community towards studying more practical MOEAs.
DEPN: Detecting and Editing Privacy Neurons in Pretrained Language Models
Oct 31, 2023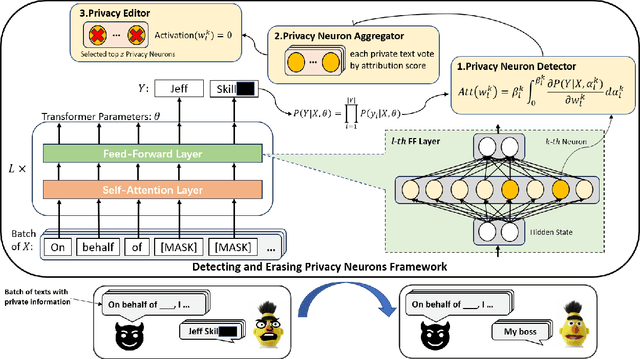

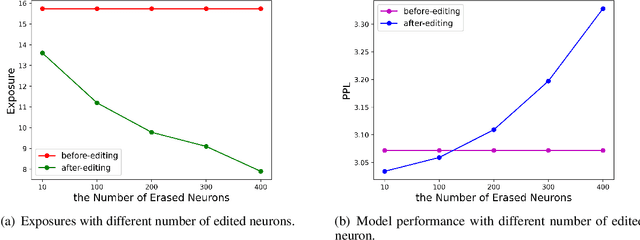

Large language models pretrained on a huge amount of data capture rich knowledge and information in the training data. The ability of data memorization and regurgitation in pretrained language models, revealed in previous studies, brings the risk of data leakage. In order to effectively reduce these risks, we propose a framework DEPN to Detect and Edit Privacy Neurons in pretrained language models, partially inspired by knowledge neurons and model editing. In DEPN, we introduce a novel method, termed as privacy neuron detector, to locate neurons associated with private information, and then edit these detected privacy neurons by setting their activations to zero. Furthermore, we propose a privacy neuron aggregator dememorize private information in a batch processing manner. Experimental results show that our method can significantly and efficiently reduce the exposure of private data leakage without deteriorating the performance of the model. Additionally, we empirically demonstrate the relationship between model memorization and privacy neurons, from multiple perspectives, including model size, training time, prompts, privacy neuron distribution, illustrating the robustness of our approach.
Towards Running Time Analysis of Interactive Multi-objective Evolutionary Algorithms
Oct 15, 2023Evolutionary algorithms (EAs) are widely used for multi-objective optimization due to their population-based nature. Traditional multi-objective EAs (MOEAs) generate a large set of solutions to approximate the Pareto front, leaving a decision maker (DM) with the task of selecting a preferred solution. However, this process can be inefficient and time-consuming, especially when there are many objectives or the subjective preferences of DM is known. To address this issue, interactive MOEAs (iMOEAs) combine decision making into the optimization process, i.e., update the population with the help of the DM. In contrast to their wide applications, there has existed only two pieces of theoretical works on iMOEAs, which only considered interactive variants of the two simple single-objective algorithms, RLS and (1+1)-EA. This paper provides the first running time analysis (the essential theoretical aspect of EAs) for practical iMOEAs. Specifically, we prove that the expected running time of the well-developed interactive NSGA-II (called R-NSGA-II) for solving the OneMinMax and OneJumpZeroJump problems is $O(n \log n)$ and $O(n^k)$, respectively, which are all asymptotically faster than the traditional NSGA-II. Meanwhile, we present a variant of OneMinMax, and prove that R-NSGA-II can be exponentially slower than NSGA-II. These results provide theoretical justification for the effectiveness of iMOEAs while identifying situations where they may fail. Experiments are also conducted to validate the theoretical results.
Submodular Maximization under the Intersection of Matroid and Knapsack Constraints
Jul 18, 2023
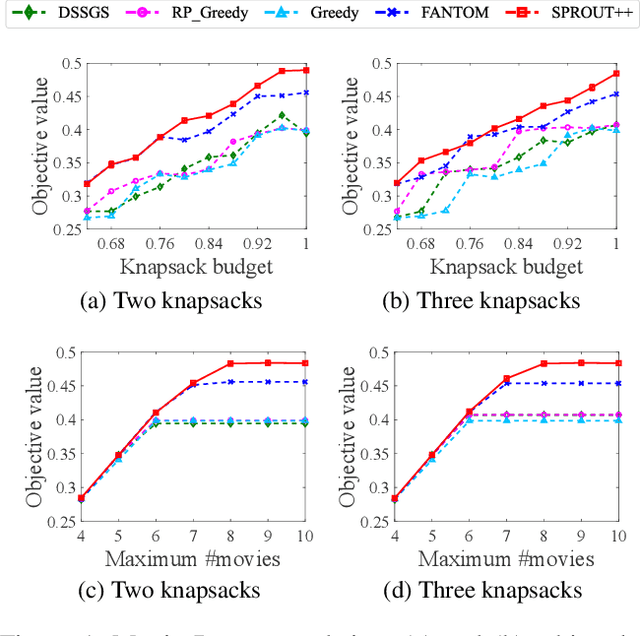
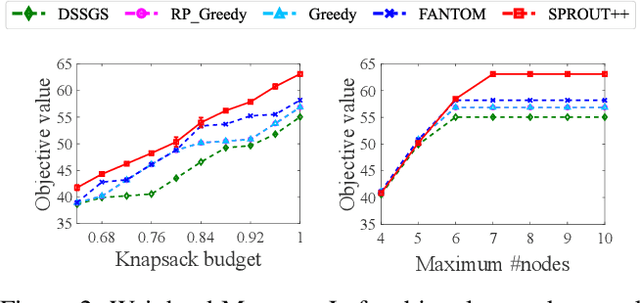
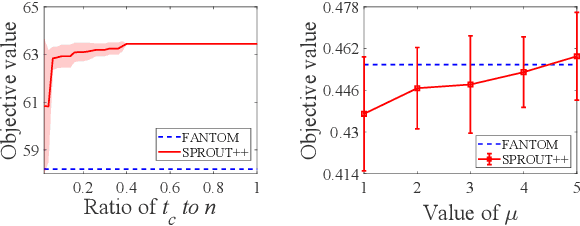
Submodular maximization arises in many applications, and has attracted a lot of research attentions from various areas such as artificial intelligence, finance and operations research. Previous studies mainly consider only one kind of constraint, while many real-world problems often involve several constraints. In this paper, we consider the problem of submodular maximization under the intersection of two commonly used constraints, i.e., $k$-matroid constraint and $m$-knapsack constraint, and propose a new algorithm SPROUT by incorporating partial enumeration into the simultaneous greedy framework. We prove that SPROUT can achieve a polynomial-time approximation guarantee better than the state-of-the-art algorithms. Then, we introduce the random enumeration and smooth techniques into SPROUT to improve its efficiency, resulting in the SPROUT++ algorithm, which can keep a similar approximation guarantee. Experiments on the applications of movie recommendation and weighted max-cut demonstrate the superiority of SPROUT++ in practice.
Stochastic Population Update Can Provably Be Helpful in Multi-Objective Evolutionary Algorithms
Jun 05, 2023Evolutionary algorithms (EAs) have been widely and successfully applied to solve multi-objective optimization problems, due to their nature of population-based search. Population update is a key component in multi-objective EAs (MOEAs), and it is performed in a greedy, deterministic manner. That is, the next-generation population is formed by selecting the first population-size ranked solutions (based on some selection criteria, e.g., non-dominated sorting, crowdedness and indicators) from the collections of the current population and newly-generated solutions. In this paper, we question this practice. We analytically present that introducing randomness into the population update procedure in MOEAs can be beneficial for the search. More specifically, we prove that the expected running time of a well-established MOEA (SMS-EMOA) for solving a commonly studied bi-objective problem, OneJumpZeroJump, can be exponentially decreased if replacing its deterministic population update mechanism by a stochastic one. Empirical studies also verify the effectiveness of the proposed stochastic population update method. This work is an attempt to challenge a common practice for the population update in MOEAs. Its positive results, which might hold more generally, should encourage the exploration of developing new MOEAs in the area.
Retrieval-Augmented Classification with Decoupled Representation
Mar 23, 2023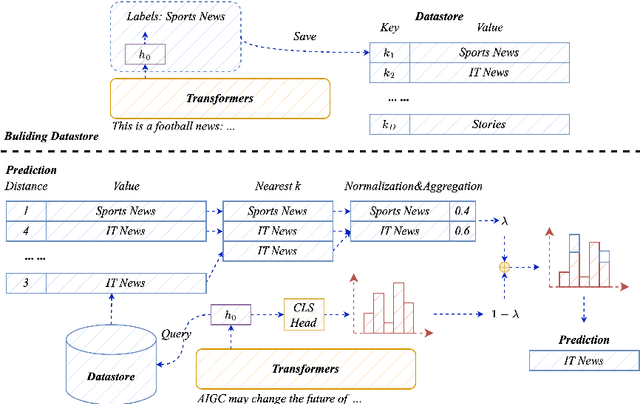

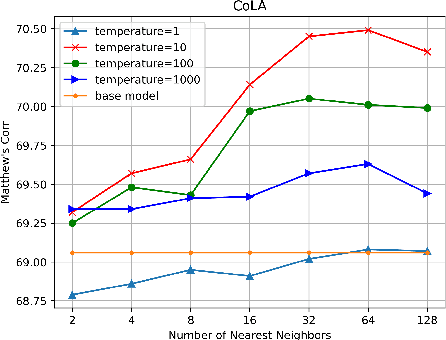

Pretrained language models (PLMs) have shown marvelous improvements across various NLP tasks. Most Chinese PLMs simply treat an input text as a sequence of characters, and completely ignore word information. Although Whole Word Masking can alleviate this, the semantics in words is still not well represented. In this paper, we revisit the segmentation granularity of Chinese PLMs. We propose a mixed-granularity Chinese BERT (MigBERT) by considering both characters and words. To achieve this, we design objective functions for learning both character and word-level representations. We conduct extensive experiments on various Chinese NLP tasks to evaluate existing PLMs as well as the proposed MigBERT. Experimental results show that MigBERT achieves new SOTA performance on all these tasks. Further analysis demonstrates that words are semantically richer than characters. More interestingly, we show that MigBERT also works with Japanese. Our code has been released here~\footnote{\url{https://github.com/xnliang98/MigBERT}} and you can download our model here~\footnote{\url{https://huggingface.co/xnliang/MigBERT-large/}}.
Character, Word, or Both? Revisiting the Segmentation Granularity for Chinese Pre-trained Language Models
Mar 22, 2023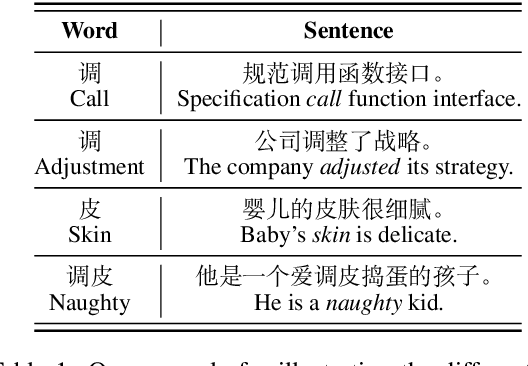
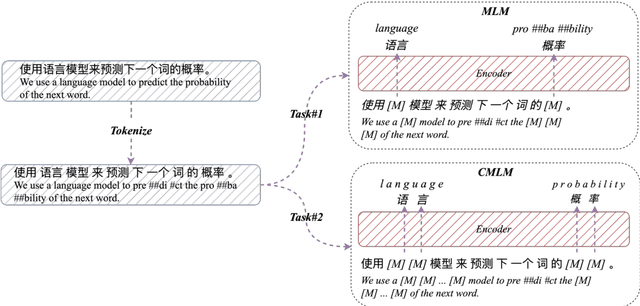

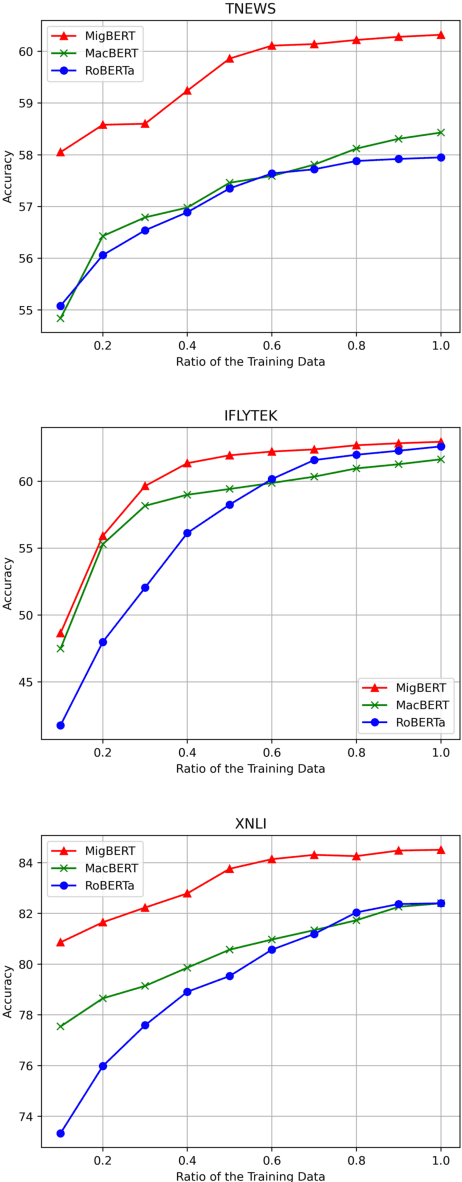
Pretrained language models (PLMs) have shown marvelous improvements across various NLP tasks. Most Chinese PLMs simply treat an input text as a sequence of characters, and completely ignore word information. Although Whole Word Masking can alleviate this, the semantics in words is still not well represented. In this paper, we revisit the segmentation granularity of Chinese PLMs. We propose a mixed-granularity Chinese BERT (MigBERT) by considering both characters and words. To achieve this, we design objective functions for learning both character and word-level representations. We conduct extensive experiments on various Chinese NLP tasks to evaluate existing PLMs as well as the proposed MigBERT. Experimental results show that MigBERT achieves new SOTA performance on all these tasks. Further analysis demonstrates that words are semantically richer than characters. More interestingly, we show that MigBERT also works with Japanese. Our code and model have been released here~\footnote{https://github.com/xnliang98/MigBERT}.