 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Comics: Enhancing Multimodal Reasoning through Structured Visual Storytelling
Feb 03, 2026Chain-of-Thought reasoning has driven large language models to extend from thinking with text to thinking with images and videos. However, different modalities still have clear limitations: static images struggle to represent temporal structure, while videos introduce substantial redundancy and computational cost. In this work, we propose Thinking with Comics, a visual reasoning paradigm that uses comics as a high information-density medium positioned between images and videos. Comics preserve temporal structure, embedded text, and narrative coherence while requiring significantly lower reasoning cost. We systematically study two reasoning paths based on comics and evaluate them on a range of reasoning tasks and long-context understanding tasks. Experimental results show that Thinking with Comics outperforms Thinking with Images on multi-step temporal and causal reasoning tasks, while remaining substantially more efficient than Thinking with Video. Further analysis indicates that different comic narrative structures and styles consistently affect performance across tasks, suggesting that comics serve as an effective intermediate visual representation for improving multimodal reasoning.
RM-Distiller: Exploiting Generative LLM for Reward Model Distillation
Jan 20, 2026Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human preferences. Due to the difficulty of obtaining high-quality human preference annotations, distilling preferences from generative LLMs has emerged as a standard practice. However, existing approaches predominantly treat teacher models as simple binary annotators, failing to fully exploit the rich knowledge and capabilities for RM distillation. To address this, we propose RM-Distiller, a framework designed to systematically exploit the multifaceted capabilities of teacher LLMs: (1) Refinement capability, which synthesizes highly correlated response pairs to create fine-grained and contrastive signals. (2) Scoring capability, which guides the RM in capturing precise preference strength via a margin-aware optimization objective. (3) Generation capability, which incorporates the teacher's generative distribution to regularize the RM to preserve its fundamental linguistic knowledge. Extensive experiments demonstrate that RM-Distiller significantly outperforms traditional distillation methods both on RM benchmarks and reinforcement learning-based alignment, proving that exploiting multifaceted teacher capabilities is critical for effective reward modeling. To the best of our knowledge, this is the first systematic research on RM distillation from generative LLMs.
DiVA: Fine-grained Factuality Verification with Agentic-Discriminative Verifier
Jan 07, 2026Despite the significant advancements of Large Language Models (LLMs), their factuality remains a critical challenge, fueling growing interest in factuality verification. Existing research on factuality verification primarily conducts binary judgments (e.g., correct or incorrect), which fails to distinguish varying degrees of error severity. This limits its utility for applications such as fine-grained evaluation and preference optimization. To bridge this gap, we propose the Agentic Discriminative Verifier (DiVA), a hybrid framework that synergizes the agentic search capabilities of generative models with the precise scoring aptitude of discriminative models. We also construct a new benchmark, FGVeriBench, as a robust testbed for fine-grained factuality verification. Experimental results on FGVeriBench demonstrate that our DiVA significantly outperforms existing methods on factuality verification for both general and multi-hop questions.
Reasoning Model Is Superior LLM-Judge, Yet Suffers from Biases
Jan 07, 2026This paper presents the first systematic comparison investigating whether Large Reasoning Models (LRMs) are superior judge to non-reasoning LLMs. Our empirical analysis yields four key findings: 1) LRMs outperform non-reasoning LLMs in terms of judgment accuracy, particularly on reasoning-intensive tasks; 2) LRMs demonstrate superior instruction-following capabilities in evaluation contexts; 3) LRMs exhibit enhanced robustness against adversarial attacks targeting judgment tasks; 4) However, LRMs still exhibit strong biases in superficial quality. To improve the robustness against biases, we propose PlanJudge, an evaluation strategy that prompts the model to generate an explicit evaluation plan before execution. Despite its simplicity, our experiments demonstrate that PlanJudge significantly mitigates biases in both LRMs and standard LLMs.
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
May 21, 2025



The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining main-stream prominent LLM benchmarks using results from diverse models. We first propose a new framework for accurate and reliable estimations of item characteristics and model abilities. Specifically, we propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. Based on PSN-IRT, we conduct extensive analysis which reveals significant and varied shortcomings in the measurement quality of current benchmarks. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.
Memory-augmented Query Reconstruction for LLM-based Knowledge Graph Reasoning
Mar 07, 2025



Large language models (LLMs) have achieved remarkable performance on knowledge graph question answering (KGQA) tasks by planning and interacting with knowledge graphs. However, existing methods often confuse tool utilization with knowledge reasoning, harming readability of model outputs and giving rise to hallucinatory tool invocations, which hinder the advancement of KGQA. To address this issue, we propose Memory-augmented Query Reconstruction for LLM-based Knowledge Graph Reasoning (MemQ) to decouple LLM from tool invocation tasks using LLM-built query memory. By establishing a memory module with explicit descriptions of query statements, the proposed MemQ facilitates the KGQA process with natural language reasoning and memory-augmented query reconstruction. Meanwhile, we design an effective and readable reasoning to enhance the LLM's reasoning capability in KGQA. Experimental results that MemQ achieves state-of-the-art performance on widely used benchmarks WebQSP and CWQ.
Evaluating o1-Like LLMs: Unlocking Reasoning for Translation through Comprehensive Analysis
Feb 17, 2025
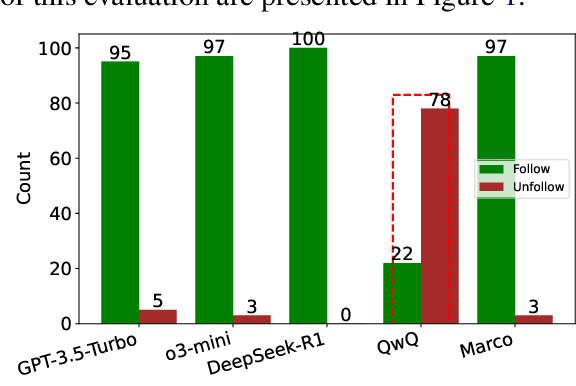


The o1-Like LLMs are transforming AI by simulating human cognitive processes, but their performance in multilingual machine translation (MMT) remains underexplored. This study examines: (1) how o1-Like LLMs perform in MMT tasks and (2) what factors influence their translation quality. We evaluate multiple o1-Like LLMs and compare them with traditional models like ChatGPT and GPT-4o. Results show that o1-Like LLMs establish new multilingual translation benchmarks, with DeepSeek-R1 surpassing GPT-4o in contextless tasks. They demonstrate strengths in historical and cultural translation but exhibit a tendency for rambling issues in Chinese-centric outputs. Further analysis reveals three key insights: (1) High inference costs and slower processing speeds make complex translation tasks more resource-intensive. (2) Translation quality improves with model size, enhancing commonsense reasoning and cultural translation. (3) The temperature parameter significantly impacts output quality-lower temperatures yield more stable and accurate translations, while higher temperatures reduce coherence and precision.
MuSC: Improving Complex Instruction Following with Multi-granularity Self-Contrastive Training
Feb 17, 2025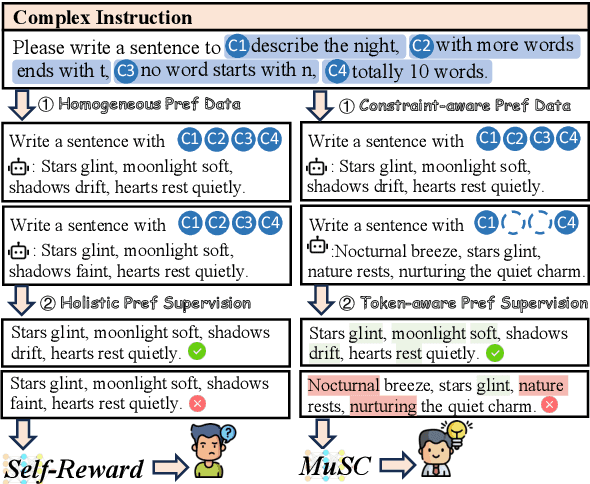



Complex instruction-following with elaborate constraints is imperative for Large Language Models (LLMs). While existing methods have constructed data for complex instruction alignment, they all rely on a more advanced model, especially GPT-4, limiting their application. In this paper, we propose a Multi-granularity Self-Contrastive Training (MuSC) framework, to improve the complex instruction alignment without relying on a stronger model. Our method is conducted on both coarse and fine granularity. On coarse-granularity, we construct constraint-aware preference data based on instruction decomposition and recombination. On fine-granularity, we perform token-aware preference optimization with dynamic token-level supervision. Our method is evaluated on open-sourced models, and experiment results show our method achieves significant improvement on both complex and general instruction-following benchmarks, surpassing previous self-alignment methods.
LLM-based Discriminative Reasoning for Knowledge Graph Question Answering
Dec 17, 2024



Large language models (LLMs) based on generative pre-trained Transformer have achieved remarkable performance on knowledge graph question-answering (KGQA) tasks. However, LLMs often produce ungrounded subgraph planning or reasoning results in KGQA due to the hallucinatory behavior brought by the generative paradigm, which may hinder the advancement of the LLM-based KGQA model. To deal with the issue, we propose a novel LLM-based Discriminative Reasoning (LDR) method to explicitly model the subgraph retrieval and answer inference process. By adopting discriminative strategies, the proposed LDR method not only enhances the capability of LLMs to retrieve question-related subgraphs but also alleviates the issue of ungrounded reasoning brought by the generative paradigm of LLMs. Experimental results show that the proposed approach outperforms multiple strong comparison methods, along with achieving state-of-the-art performance on two widely used WebQSP and CWQ benchmarks.
Make Imagination Clearer! Stable Diffusion-based Visual Imagination for Multimodal Machine Translation
Dec 17, 2024



Visual information has been introduced for enhancing machine translation (MT), and its effectiveness heavily relies on the availability of large amounts of bilingual parallel sentence pairs with manual image annotations. In this paper, we introduce a stable diffusion-based imagination network into a multimodal large language model (MLLM) to explicitly generate an image for each source sentence, thereby advancing the multimodel MT. Particularly, we build heuristic human feedback with reinforcement learning to ensure the consistency of the generated image with the source sentence without the supervision of image annotation, which breaks the bottleneck of using visual information in MT. Furthermore, the proposed method enables imaginative visual information to be integrated into large-scale text-only MT in addition to multimodal MT. Experimental results show that our model significantly outperforms existing multimodal MT and text-only MT, especially achieving an average improvement of more than 14 BLEU points on Multi30K multimodal MT benchmarks.