 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Aware Active Knowledge Acquisition for Emotional Support Dialogue
May 28, 2026Emotional support plays an important role in dialogue systems, and its success depends on adapting to a user's evolving and implicit needs across multi-turn interactions while leveraging the strong reasoning capacity of large language models. However, since signals about user needs are often weak, indirect, and can only be disambiguated through multi-turn interaction, existing emotional support methods often struggle to acquire and generalize relevant conversational knowledge efficiently. To bridge this gap, we introduce User-Aware Active Knowledge Acquisition (UKA), a gradient-free active dialogue learning framework that explicitly represents uncertainty about user needs and incorporates active learning into both knowledge acquisition and response selection.We propose a Theory-of-Mind uncertainty estimation mechanism that allows the model to prioritize responses, thereby eliciting more informative user feedback. UKA is capable of efficiently exploring user-aligned conversational knowledge during training while maintaining robustness at test time. Experiments across multiple dialogue benchmarks and model architectures demonstrate that our approach consistently outperforms strong baselines in dialogue quality and user alignment.
Beyond Token-Level Policy Gradients for Complex Reasoning with Large Language Models
Feb 16, 2026Existing policy-gradient methods for auto-regressive language models typically select subsequent tokens one at a time as actions in the policy. While effective for many generation tasks, such an approach may not fully capture the structure of complex reasoning tasks, where a single semantic decision is often realized across multiple tokens--for example, when defining variables or composing equations. This introduces a potential mismatch between token-level optimization and the inherently block-level nature of reasoning in these settings. To bridge this gap, we propose Multi-token Policy Gradient Optimization (MPO), a framework that treats sequences of K consecutive tokens as unified semantic actions. This block-level perspective enables our method to capture the compositional structure of reasoning trajectories and supports optimization over coherent, higher-level objectives. Experiments on mathematical reasoning and coding benchmarks show that MPO outperforms standard token-level policy gradient baselines, highlight the limitations of token-level policy gradients for complex reasoning, motivating future research to look beyond token-level granularity for reasoning-intensive language tasks.
Instruction Anchors: Dissecting the Causal Dynamics of Modality Arbitration
Feb 03, 2026Modality following serves as the capacity of multimodal large language models (MLLMs) to selectively utilize multimodal contexts based on user instructions. It is fundamental to ensuring safety and reliability in real-world deployments. However, the underlying mechanisms governing this decision-making process remain poorly understood. In this paper, we investigate its working mechanism through an information flow lens. Our findings reveal that instruction tokens function as structural anchors for modality arbitration: Shallow attention layers perform non-selective information transfer, routing multimodal cues to these anchors as a latent buffer; Modality competition is resolved within deep attention layers guided by the instruction intent, while MLP layers exhibit semantic inertia, acting as an adversarial force. Furthermore, we identify a sparse set of specialized attention heads that drive this arbitration. Causal interventions demonstrate that manipulating a mere $5\%$ of these critical heads can decrease the modality-following ratio by $60\%$ through blocking, or increase it by $60\%$ through targeted amplification of failed samples. Our work provides a substantial step toward model transparency and offers a principled framework for the orchestration of multimodal information in MLLMs.
Memory-augmented Query Reconstruction for LLM-based Knowledge Graph Reasoning
Mar 07, 2025



Large language models (LLMs) have achieved remarkable performance on knowledge graph question answering (KGQA) tasks by planning and interacting with knowledge graphs. However, existing methods often confuse tool utilization with knowledge reasoning, harming readability of model outputs and giving rise to hallucinatory tool invocations, which hinder the advancement of KGQA. To address this issue, we propose Memory-augmented Query Reconstruction for LLM-based Knowledge Graph Reasoning (MemQ) to decouple LLM from tool invocation tasks using LLM-built query memory. By establishing a memory module with explicit descriptions of query statements, the proposed MemQ facilitates the KGQA process with natural language reasoning and memory-augmented query reconstruction. Meanwhile, we design an effective and readable reasoning to enhance the LLM's reasoning capability in KGQA. Experimental results that MemQ achieves state-of-the-art performance on widely used benchmarks WebQSP and CWQ.
LLM-based Discriminative Reasoning for Knowledge Graph Question Answering
Dec 17, 2024



Large language models (LLMs) based on generative pre-trained Transformer have achieved remarkable performance on knowledge graph question-answering (KGQA) tasks. However, LLMs often produce ungrounded subgraph planning or reasoning results in KGQA due to the hallucinatory behavior brought by the generative paradigm, which may hinder the advancement of the LLM-based KGQA model. To deal with the issue, we propose a novel LLM-based Discriminative Reasoning (LDR) method to explicitly model the subgraph retrieval and answer inference process. By adopting discriminative strategies, the proposed LDR method not only enhances the capability of LLMs to retrieve question-related subgraphs but also alleviates the issue of ungrounded reasoning brought by the generative paradigm of LLMs. Experimental results show that the proposed approach outperforms multiple strong comparison methods, along with achieving state-of-the-art performance on two widely used WebQSP and CWQ benchmarks.
Impact-Oriented Contextual Scholar Profiling using Self-Citation Graphs
Apr 24, 2023
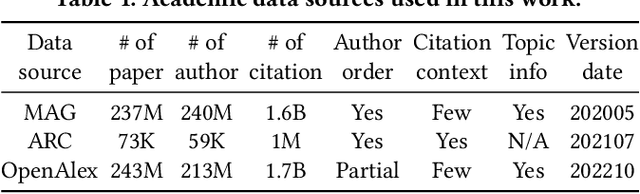
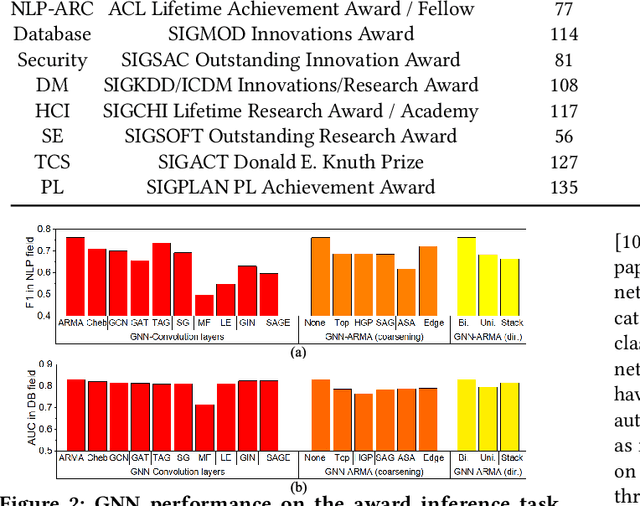
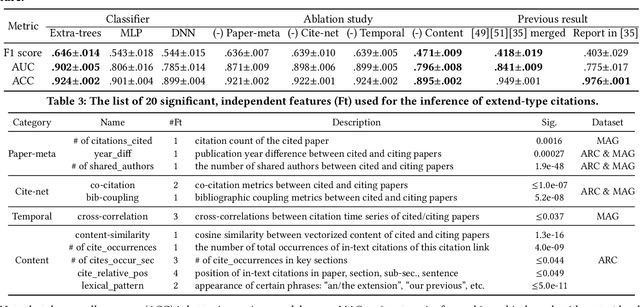
Quantitatively profiling a scholar's scientific impact is important to modern research society. Current practices with bibliometric indicators (e.g., h-index), lists, and networks perform well at scholar ranking, but do not provide structured context for scholar-centric, analytical tasks such as profile reasoning and understanding. This work presents GeneticFlow (GF), a suite of novel graph-based scholar profiles that fulfill three essential requirements: structured-context, scholar-centric, and evolution-rich. We propose a framework to compute GF over large-scale academic data sources with millions of scholars. The framework encompasses a new unsupervised advisor-advisee detection algorithm, a well-engineered citation type classifier using interpretable features, and a fine-tuned graph neural network (GNN) model. Evaluations are conducted on the real-world task of scientific award inference. Experiment outcomes show that the F1 score of best GF profile significantly outperforms alternative methods of impact indicators and bibliometric networks in all the 6 computer science fields considered. Moreover, the core GF profiles, with 63.6%-66.5% nodes and 12.5%-29.9% edges of the full profile, still significantly outrun existing methods in 5 out of 6 fields studied. Visualization of GF profiling result also reveals human explainable patterns for high-impact scholars.
Inference with Hybrid Bio-hardware Neural Networks
May 28, 2019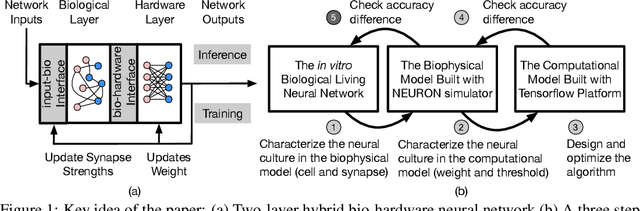
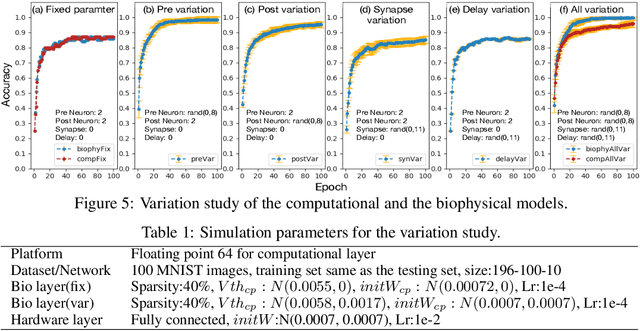

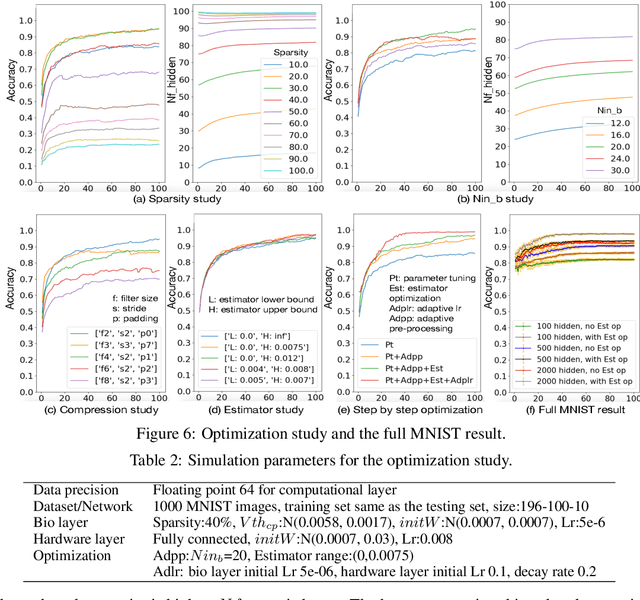
To understand the learning process in brains, biologically plausible algorithms have been explored by modeling the detailed neuron properties and dynamics. On the other hand, simplified multi-layer models of neural networks have shown great success on computational tasks such as image classification and speech recognition. However, the computational models that can achieve good accuracy for these learning applications are very different from the bio-plausible models. This paper studies whether a bio-plausible model of a in vitro living neural network can be used to perform machine learning tasks and achieve good inference accuracy. A novel two-layer bio-hardware hybrid neural network is proposed. The biological layer faithfully models variations of synapses, neurons, and network sparsity in in vitro living neural networks. The hardware layer is a computational fully-connected layer that tunes parameters to optimize for accuracy. Several techniques are proposed to improve the inference accuracy of the proposed hybrid neural network. For instance, an adaptive pre-processing technique helps the proposed neural network to achieve good learning accuracy for different living neural network sparsity. The proposed hybrid neural network with realistic neuron parameters and variations achieves a 98.3% testing accuracy for the handwritten digit recognition task on the full MNIST dataset.