 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeinversedMixup: Data Augmentation via Inverting Mixed Embeddings
Jan 29, 2026Mixup generates augmented samples by linearly interpolating inputs and labels with a controllable ratio. However, since it operates in the latent embedding level, the resulting samples are not human-interpretable. In contrast, LLM-based augmentation methods produce sentences via prompts at the token level, yielding readable outputs but offering limited control over the generation process. Inspired by recent advances in LLM inversion, which reconstructs natural language from embeddings and helps bridge the gap between latent embedding space and discrete token space, we propose inversedMixup, a unified framework that combines the controllability of Mixup with the interpretability of LLM-based generation. Specifically, inversedMixup adopts a three-stage training procedure to align the output embedding space of a task-specific model with the input embedding space of an LLM. Upon successful alignment, inversedMixup can reconstruct mixed embeddings with a controllable mixing ratio into human-interpretable augmented sentences, thereby improving the augmentation performance. Additionally, inversedMixup provides the first empirical evidence of the manifold intrusion phenomenon in text Mixup and introduces a simple yet effective strategy to mitigate it. Extensive experiments demonstrate the effectiveness and generalizability of our approach in both few-shot and fully supervised scenarios.
Mitigating Message Imbalance in Fraud Detection with Dual-View Graph Representation Learning
Jul 09, 2025Graph representation learning has become a mainstream method for fraud detection due to its strong expressive power, which focuses on enhancing node representations through improved neighborhood knowledge capture. However, the focus on local interactions leads to imbalanced transmission of global topological information and increased risk of node-specific information being overwhelmed during aggregation due to the imbalance between fraud and benign nodes. In this paper, we first summarize the impact of topology and class imbalance on downstream tasks in GNN-based fraud detection, as the problem of imbalanced supervisory messages is caused by fraudsters' topological behavior obfuscation and identity feature concealment. Based on statistical validation, we propose a novel dual-view graph representation learning method to mitigate Message imbalance in Fraud Detection(MimbFD). Specifically, we design a topological message reachability module for high-quality node representation learning to penetrate fraudsters' camouflage and alleviate insufficient propagation. Then, we introduce a local confounding debiasing module to adjust node representations, enhancing the stable association between node representations and labels to balance the influence of different classes. Finally, we conducted experiments on three public fraud datasets, and the results demonstrate that MimbFD exhibits outstanding performance in fraud detection.
Implicit Word Reordering with Knowledge Distillation for Cross-Lingual Dependency Parsing
Feb 24, 2025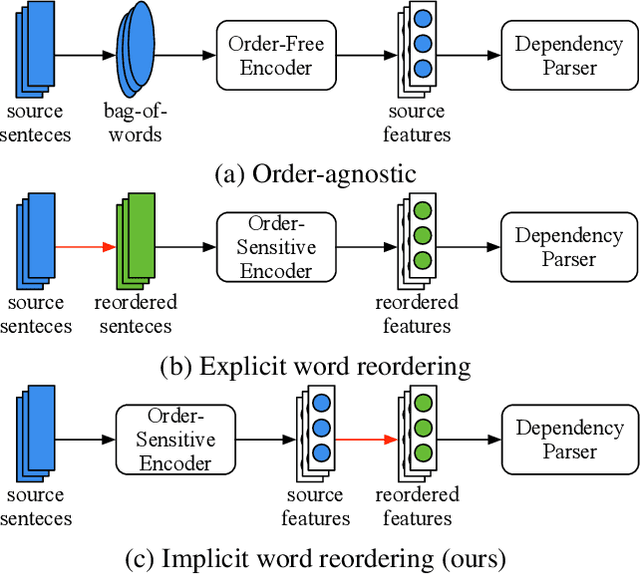

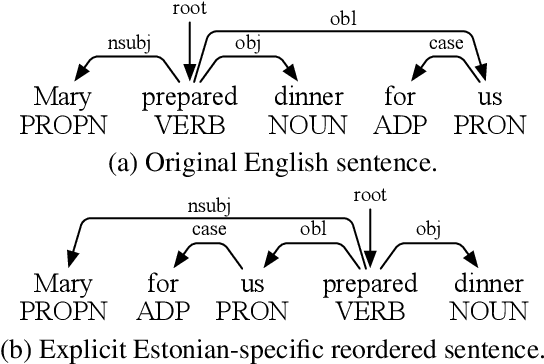

Word order difference between source and target languages is a major obstacle to cross-lingual transfer, especially in the dependency parsing task. Current works are mostly based on order-agnostic models or word reordering to mitigate this problem. However, such methods either do not leverage grammatical information naturally contained in word order or are computationally expensive as the permutation space grows exponentially with the sentence length. Moreover, the reordered source sentence with an unnatural word order may be a form of noising that harms the model learning. To this end, we propose an Implicit Word Reordering framework with Knowledge Distillation (IWR-KD). This framework is inspired by that deep networks are good at learning feature linearization corresponding to meaningful data transformation, e.g. word reordering. To realize this idea, we introduce a knowledge distillation framework composed of a word-reordering teacher model and a dependency parsing student model. We verify our proposed method on Universal Dependency Treebanks across 31 different languages and show it outperforms a series of competitors, together with experimental analysis to illustrate how our method works towards training a robust parser.
Prompt-based Unifying Inference Attack on Graph Neural Networks
Dec 20, 2024Graph neural networks (GNNs) provide important prospective insights in applications such as social behavior analysis and financial risk analysis based on their powerful learning capabilities on graph data. Nevertheless, GNNs' predictive performance relies on the quality of task-specific node labels, so it is common practice to improve the model's generalization ability in the downstream execution of decision-making tasks through pre-training. Graph prompting is a prudent choice but risky without taking measures to prevent data leakage. In other words, in high-risk decision scenarios, prompt learning can infer private information by accessing model parameters trained on private data (publishing model parameters in pre-training, i.e., without directly leaking the raw data, is a tacitly accepted trend). However, myriad graph inference attacks necessitate tailored module design and processing to enhance inference capabilities due to variations in supervision signals. In this paper, we propose a novel Prompt-based unifying Inference Attack framework on GNNs, named ProIA. Specifically, ProIA retains the crucial topological information of the graph during pre-training, enhancing the background knowledge of the inference attack model. It then utilizes a unified prompt and introduces additional disentanglement factors in downstream attacks to adapt to task-relevant knowledge. Finally, extensive experiments show that ProIA enhances attack capabilities and demonstrates remarkable adaptability to various inference attacks.
HGNAS: Hardware-Aware Graph Neural Architecture Search for Edge Devices
Aug 23, 2024



Graph Neural Networks (GNNs) are becoming increasingly popular for graph-based learning tasks such as point cloud processing due to their state-of-the-art (SOTA) performance. Nevertheless, the research community has primarily focused on improving model expressiveness, lacking consideration of how to design efficient GNN models for edge scenarios with real-time requirements and limited resources. Examining existing GNN models reveals varied execution across platforms and frequent Out-Of-Memory (OOM) problems, highlighting the need for hardware-aware GNN design. To address this challenge, this work proposes a novel hardware-aware graph neural architecture search framework tailored for resource constraint edge devices, namely HGNAS. To achieve hardware awareness, HGNAS integrates an efficient GNN hardware performance predictor that evaluates the latency and peak memory usage of GNNs in milliseconds. Meanwhile, we study GNN memory usage during inference and offer a peak memory estimation method, enhancing the robustness of architecture evaluations when combined with predictor outcomes. Furthermore, HGNAS constructs a fine-grained design space to enable the exploration of extreme performance architectures by decoupling the GNN paradigm. In addition, the multi-stage hierarchical search strategy is leveraged to facilitate the navigation of huge candidates, which can reduce the single search time to a few GPU hours. To the best of our knowledge, HGNAS is the first automated GNN design framework for edge devices, and also the first work to achieve hardware awareness of GNNs across different platforms. Extensive experiments across various applications and edge devices have proven the superiority of HGNAS. It can achieve up to a 10.6x speedup and an 82.5% peak memory reduction with negligible accuracy loss compared to DGCNN on ModelNet40.
Adaptive Differentially Private Structural Entropy Minimization for Unsupervised Social Event Detection
Jul 23, 2024
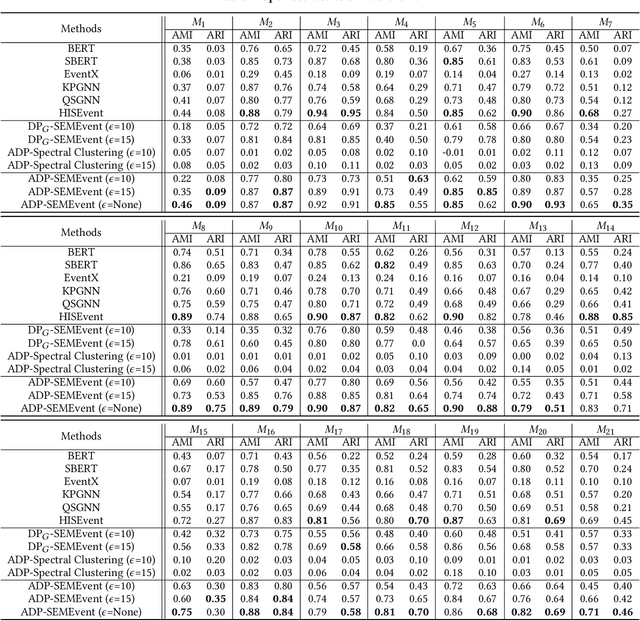
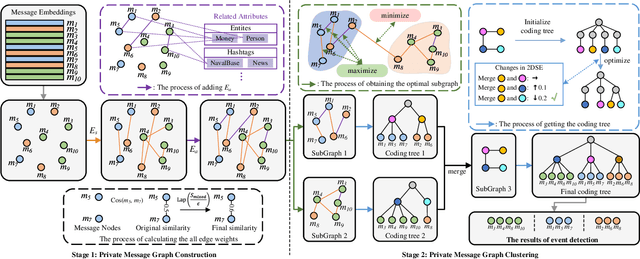
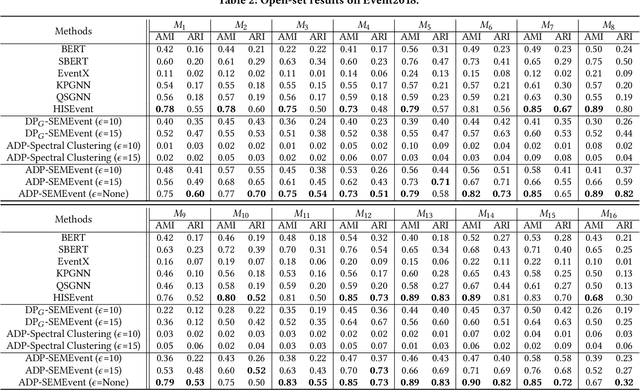
Social event detection refers to extracting relevant message clusters from social media data streams to represent specific events in the real world. Social event detection is important in numerous areas, such as opinion analysis, social safety, and decision-making. Most current methods are supervised and require access to large amounts of data. These methods need prior knowledge of the events and carry a high risk of leaking sensitive information in the messages, making them less applicable in open-world settings. Therefore, conducting unsupervised detection while fully utilizing the rich information in the messages and protecting data privacy remains a significant challenge. To this end, we propose a novel social event detection framework, ADP-SEMEvent, an unsupervised social event detection method that prioritizes privacy. Specifically, ADP-SEMEvent is divided into two stages, i.e., the construction stage of the private message graph and the clustering stage of the private message graph. In the first stage, an adaptive differential privacy approach is used to construct a private message graph. In this process, our method can adaptively apply differential privacy based on the events occurring each day in an open environment to maximize the use of the privacy budget. In the second stage, to address the reduction in data utility caused by noise, a novel 2-dimensional structural entropy minimization algorithm based on optimal subgraphs is used to detect events in the message graph. The highlight of this process is unsupervised and does not compromise differential privacy. Extensive experiments on two public datasets demonstrate that ADP-SEMEvent can achieve detection performance comparable to state-of-the-art methods while maintaining reasonable privacy budget parameters.
GNNavigator: Towards Adaptive Training of Graph Neural Networks via Automatic Guideline Exploration
Apr 15, 2024Graph Neural Networks (GNNs) succeed significantly in many applications recently. However, balancing GNNs training runtime cost, memory consumption, and attainable accuracy for various applications is non-trivial. Previous training methodologies suffer from inferior adaptability and lack a unified training optimization solution. To address the problem, this work proposes GNNavigator, an adaptive GNN training configuration optimization framework. GNNavigator meets diverse GNN application requirements due to our unified software-hardware co-abstraction, proposed GNNs training performance model, and practical design space exploration solution. Experimental results show that GNNavigator can achieve up to 3.1x speedup and 44.9% peak memory reduction with comparable accuracy to state-of-the-art approaches.
Graph Neural Networks Automated Design and Deployment on Device-Edge Co-Inference Systems
Apr 08, 2024



The key to device-edge co-inference paradigm is to partition models into computation-friendly and computation-intensive parts across the device and the edge, respectively. However, for Graph Neural Networks (GNNs), we find that simply partitioning without altering their structures can hardly achieve the full potential of the co-inference paradigm due to various computational-communication overheads of GNN operations over heterogeneous devices. We present GCoDE, the first automatic framework for GNN that innovatively Co-designs the architecture search and the mapping of each operation on Device-Edge hierarchies. GCoDE abstracts the device communication process into an explicit operation and fuses the search of architecture and the operations mapping in a unified space for joint-optimization. Also, the performance-awareness approach, utilized in the constraint-based search process of GCoDE, enables effective evaluation of architecture efficiency in diverse heterogeneous systems. We implement the co-inference engine and runtime dispatcher in GCoDE to enhance the deployment efficiency. Experimental results show that GCoDE can achieve up to $44.9\times$ speedup and $98.2\%$ energy reduction compared to existing approaches across various applications and system configurations.
DA-Net: A Disentangled and Adaptive Network for Multi-Source Cross-Lingual Transfer Learning
Mar 07, 2024Multi-Source cross-lingual transfer learning deals with the transfer of task knowledge from multiple labelled source languages to an unlabeled target language under the language shift. Existing methods typically focus on weighting the predictions produced by language-specific classifiers of different sources that follow a shared encoder. However, all source languages share the same encoder, which is updated by all these languages. The extracted representations inevitably contain different source languages' information, which may disturb the learning of the language-specific classifiers. Additionally, due to the language gap, language-specific classifiers trained with source labels are unable to make accurate predictions for the target language. Both facts impair the model's performance. To address these challenges, we propose a Disentangled and Adaptive Network (DA-Net). Firstly, we devise a feedback-guided collaborative disentanglement method that seeks to purify input representations of classifiers, thereby mitigating mutual interference from multiple sources. Secondly, we propose a class-aware parallel adaptation method that aligns class-level distributions for each source-target language pair, thereby alleviating the language pairs' language gap. Experimental results on three different tasks involving 38 languages validate the effectiveness of our approach.
Poincaré Differential Privacy for Hierarchy-Aware Graph Embedding
Dec 20, 2023Hierarchy is an important and commonly observed topological property in real-world graphs that indicate the relationships between supervisors and subordinates or the organizational behavior of human groups. As hierarchy is introduced as a new inductive bias into the Graph Neural Networks (GNNs) in various tasks, it implies latent topological relations for attackers to improve their inference attack performance, leading to serious privacy leakage issues. In addition, existing privacy-preserving frameworks suffer from reduced protection ability in hierarchical propagation due to the deficiency of adaptive upper-bound estimation of the hierarchical perturbation boundary. It is of great urgency to effectively leverage the hierarchical property of data while satisfying privacy guarantees. To solve the problem, we propose the Poincar\'e Differential Privacy framework, named PoinDP, to protect the hierarchy-aware graph embedding based on hyperbolic geometry. Specifically, PoinDP first learns the hierarchy weights for each entity based on the Poincar\'e model in hyperbolic space. Then, the Personalized Hierarchy-aware Sensitivity is designed to measure the sensitivity of the hierarchical structure and adaptively allocate the privacy protection strength. Besides, the Hyperbolic Gaussian Mechanism (HGM) is proposed to extend the Gaussian mechanism in Euclidean space to hyperbolic space to realize random perturbations that satisfy differential privacy under the hyperbolic space metric. Extensive experiment results on five real-world datasets demonstrate the proposed PoinDP's advantages of effective privacy protection while maintaining good performance on the node classification task.