 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Label Consistency of In-Context Learning: An Implicit Transductive Label Propagation Perspective
Dec 13, 2025Large language models (LLMs) perform in-context learning (ICL) with minimal supervised examples, which benefits various natural language processing (NLP) tasks. One of the critical research focus is the selection of prompt demonstrations. Current approaches typically employ retrieval models to select the top-K most semantically similar examples as demonstrations. However, we argue that existing methods are limited since the label consistency is not guaranteed during demonstration selection. Our cognition derives from the Bayesian view of ICL and our rethinking of ICL from the transductive label propagation perspective. We treat ICL as a transductive learning method and incorporate latent concepts from Bayesian view and deduce that similar demonstrations guide the concepts of query, with consistent labels serving as estimates. Based on this understanding, we establish a label propagation framework to link label consistency with propagation error bounds. To model label consistency, we propose a data synthesis method, leveraging both semantic and label information, and use TopK sampling with Synthetic Data (TopK-SD) to acquire demonstrations with consistent labels. TopK-SD outperforms original TopK sampling on multiple benchmarks. Our work provides a new perspective for understanding the working mechanisms within ICL.
A Graph-based Verification Framework for Fact-Checking
Mar 10, 2025Fact-checking plays a crucial role in combating misinformation. Existing methods using large language models (LLMs) for claim decomposition face two key limitations: (1) insufficient decomposition, introducing unnecessary complexity to the verification process, and (2) ambiguity of mentions, leading to incorrect verification results. To address these challenges, we suggest introducing a claim graph consisting of triplets to address the insufficient decomposition problem and reduce mention ambiguity through graph structure. Based on this core idea, we propose a graph-based framework, GraphFC, for fact-checking. The framework features three key components: graph construction, which builds both claim and evidence graphs; graph-guided planning, which prioritizes the triplet verification order; and graph-guided checking, which verifies the triples one by one between claim and evidence graphs. Extensive experiments show that GraphFC enables fine-grained decomposition while resolving referential ambiguities through relational constraints, achieving state-of-the-art performance across three datasets.
Implicit Word Reordering with Knowledge Distillation for Cross-Lingual Dependency Parsing
Feb 24, 2025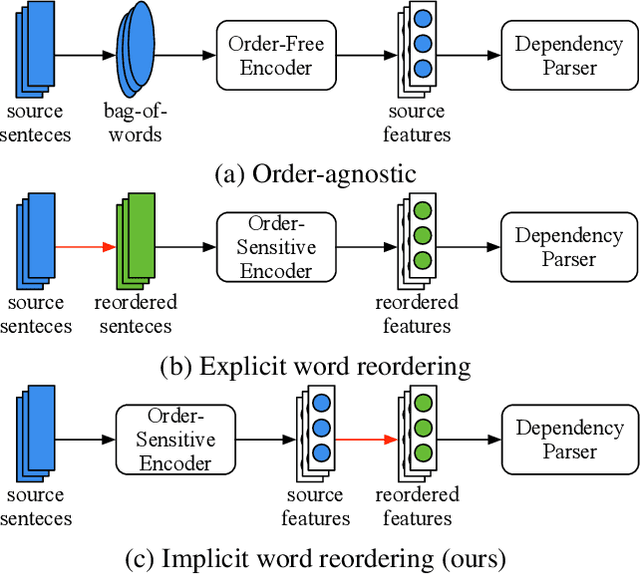

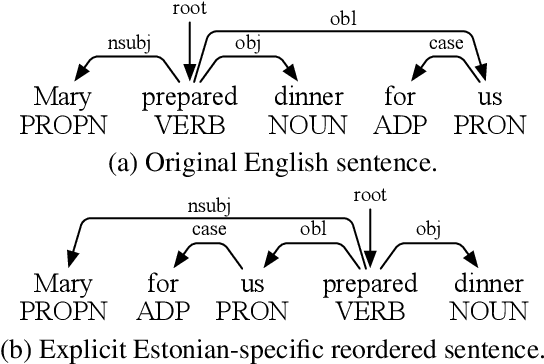

Word order difference between source and target languages is a major obstacle to cross-lingual transfer, especially in the dependency parsing task. Current works are mostly based on order-agnostic models or word reordering to mitigate this problem. However, such methods either do not leverage grammatical information naturally contained in word order or are computationally expensive as the permutation space grows exponentially with the sentence length. Moreover, the reordered source sentence with an unnatural word order may be a form of noising that harms the model learning. To this end, we propose an Implicit Word Reordering framework with Knowledge Distillation (IWR-KD). This framework is inspired by that deep networks are good at learning feature linearization corresponding to meaningful data transformation, e.g. word reordering. To realize this idea, we introduce a knowledge distillation framework composed of a word-reordering teacher model and a dependency parsing student model. We verify our proposed method on Universal Dependency Treebanks across 31 different languages and show it outperforms a series of competitors, together with experimental analysis to illustrate how our method works towards training a robust parser.
FDLLM: A Text Fingerprint Detection Method for LLMs in Multi-Language, Multi-Domain Black-Box Environments
Jan 27, 2025



Using large language models (LLMs) integration platforms without transparency about which LLM is being invoked can lead to potential security risks. Specifically, attackers may exploit this black-box scenario to deploy malicious models and embed viruses in the code provided to users. In this context, it is increasingly urgent for users to clearly identify the LLM they are interacting with, in order to avoid unknowingly becoming victims of malicious models. However, existing studies primarily focus on mixed classification of human and machine-generated text, with limited attention to classifying texts generated solely by different models. Current research also faces dual bottlenecks: poor quality of LLM-generated text (LLMGT) datasets and limited coverage of detectable LLMs, resulting in poor detection performance for various LLMGT in black-box scenarios. We propose the first LLMGT fingerprint detection model, \textbf{FDLLM}, based on Qwen2.5-7B and fine-tuned using LoRA to address these challenges. FDLLM can more efficiently handle detection tasks across multilingual and multi-domain scenarios. Furthermore, we constructed a dataset named \textbf{FD-Datasets}, consisting of 90,000 samples that span multiple languages and domains, covering 20 different LLMs. Experimental results demonstrate that FDLLM achieves a macro F1 score 16.7\% higher than the best baseline method, LM-D.
HOLA-Drone: Hypergraphic Open-ended Learning for Zero-Shot Multi-Drone Cooperative Pursuit
Sep 13, 2024Zero-shot coordination (ZSC) is a significant challenge in multi-agent collaboration, aiming to develop agents that can coordinate with unseen partners they have not encountered before. Recent cutting-edge ZSC methods have primarily focused on two-player video games such as OverCooked!2 and Hanabi. In this paper, we extend the scope of ZSC research to the multi-drone cooperative pursuit scenario, exploring how to construct a drone agent capable of coordinating with multiple unseen partners to capture multiple evaders. We propose a novel Hypergraphic Open-ended Learning Algorithm (HOLA-Drone) that continuously adapts the learning objective based on our hypergraphic-form game modeling, aiming to improve cooperative abilities with multiple unknown drone teammates. To empirically verify the effectiveness of HOLA-Drone, we build two different unseen drone teammate pools to evaluate their performance in coordination with various unseen partners. The experimental results demonstrate that HOLA-Drone outperforms the baseline methods in coordination with unseen drone teammates. Furthermore, real-world experiments validate the feasibility of HOLA-Drone in physical systems. Videos can be found on the project homepage~\url{https://sites.google.com/view/hola-drone}.
Progressively Modality Freezing for Multi-Modal Entity Alignment
Jul 23, 2024



Multi-Modal Entity Alignment aims to discover identical entities across heterogeneous knowledge graphs. While recent studies have delved into fusion paradigms to represent entities holistically, the elimination of features irrelevant to alignment and modal inconsistencies is overlooked, which are caused by inherent differences in multi-modal features. To address these challenges, we propose a novel strategy of progressive modality freezing, called PMF, that focuses on alignmentrelevant features and enhances multi-modal feature fusion. Notably, our approach introduces a pioneering cross-modal association loss to foster modal consistency. Empirical evaluations across nine datasets confirm PMF's superiority, demonstrating stateof-the-art performance and the rationale for freezing modalities. Our code is available at https://github.com/ninibymilk/PMF-MMEA.
AdversarialWord Dilution as Text Data Augmentation in Low-Resource Regime
May 16, 2023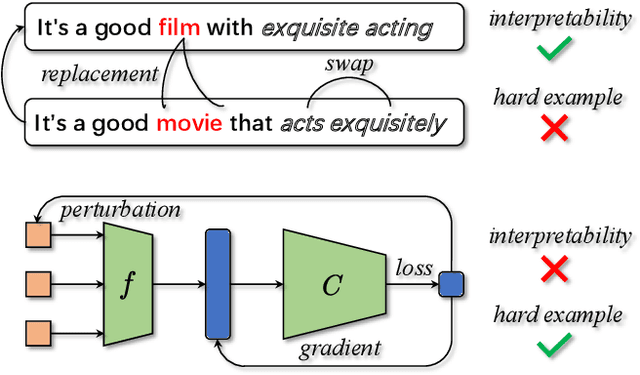
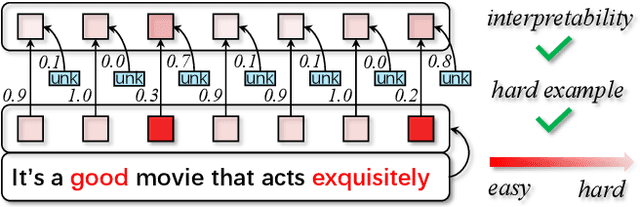
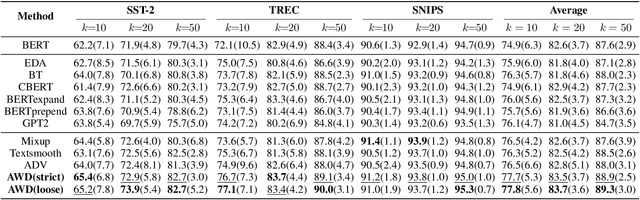
Data augmentation is widely used in text classification, especially in the low-resource regime where a few examples for each class are available during training. Despite the success, generating data augmentations as hard positive examples that may increase their effectiveness is under-explored. This paper proposes an Adversarial Word Dilution (AWD) method that can generate hard positive examples as text data augmentations to train the low-resource text classification model efficiently. Our idea of augmenting the text data is to dilute the embedding of strong positive words by weighted mixing with unknown-word embedding, making the augmented inputs hard to be recognized as positive by the classification model. We adversarially learn the dilution weights through a constrained min-max optimization process with the guidance of the labels. Empirical studies on three benchmark datasets show that AWD can generate more effective data augmentations and outperform the state-of-the-art text data augmentation methods. The additional analysis demonstrates that the data augmentations generated by AWD are interpretable and can flexibly extend to new examples without further training.
ContrastNet: A Contrastive Learning Framework for Few-Shot Text Classification
May 16, 2023



Few-shot text classification has recently been promoted by the meta-learning paradigm which aims to identify target classes with knowledge transferred from source classes with sets of small tasks named episodes. Despite their success, existing works building their meta-learner based on Prototypical Networks are unsatisfactory in learning discriminative text representations between similar classes, which may lead to contradictions during label prediction. In addition, the tasklevel and instance-level overfitting problems in few-shot text classification caused by a few training examples are not sufficiently tackled. In this work, we propose a contrastive learning framework named ContrastNet to tackle both discriminative representation and overfitting problems in few-shot text classification. ContrastNet learns to pull closer text representations belonging to the same class and push away text representations belonging to different classes, while simultaneously introducing unsupervised contrastive regularization at both task-level and instance-level to prevent overfitting. Experiments on 8 few-shot text classification datasets show that ContrastNet outperforms the current state-of-the-art models.
A Hierarchical N-Gram Framework for Zero-Shot Link Prediction
Apr 16, 2022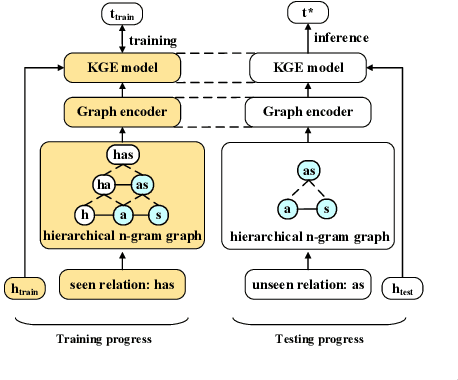
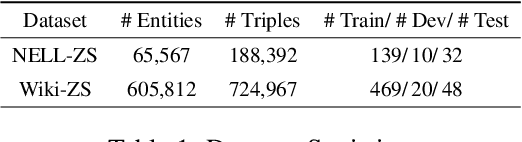
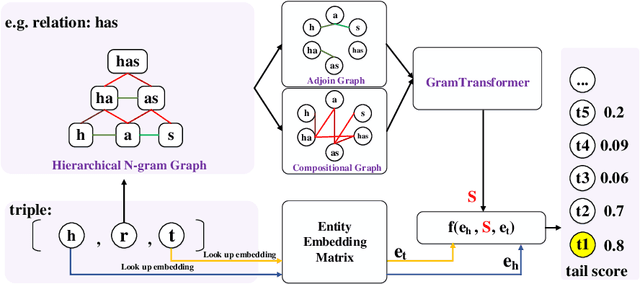
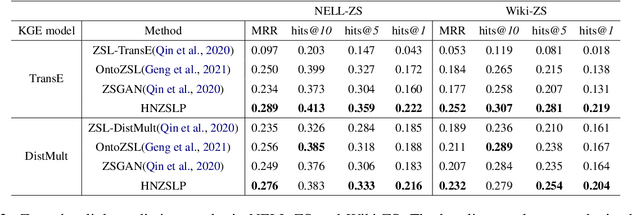
Due to the incompleteness of knowledge graphs (KGs), zero-shot link prediction (ZSLP) which aims to predict unobserved relations in KGs has attracted recent interest from researchers. A common solution is to use textual features of relations (e.g., surface name or textual descriptions) as auxiliary information to bridge the gap between seen and unseen relations. Current approaches learn an embedding for each word token in the text. These methods lack robustness as they suffer from the out-of-vocabulary (OOV) problem. Meanwhile, models built on character n-grams have the capability of generating expressive representations for OOV words. Thus, in this paper, we propose a Hierarchical N-Gram framework for Zero-Shot Link Prediction (HNZSLP), which considers the dependencies among character n-grams of the relation surface name for ZSLP. Our approach works by first constructing a hierarchical n-gram graph on the surface name to model the organizational structure of n-grams that leads to the surface name. A GramTransformer, based on the Transformer is then presented to model the hierarchical n-gram graph to construct the relation embedding for ZSLP. Experimental results show the proposed HNZSLP achieved state-of-the-art performance on two ZSLP datasets.
Neural Dialogue State Tracking with Temporally Expressive Networks
Oct 03, 2020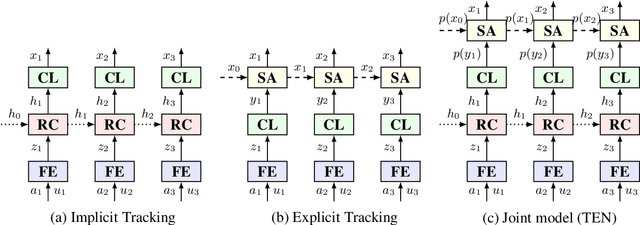
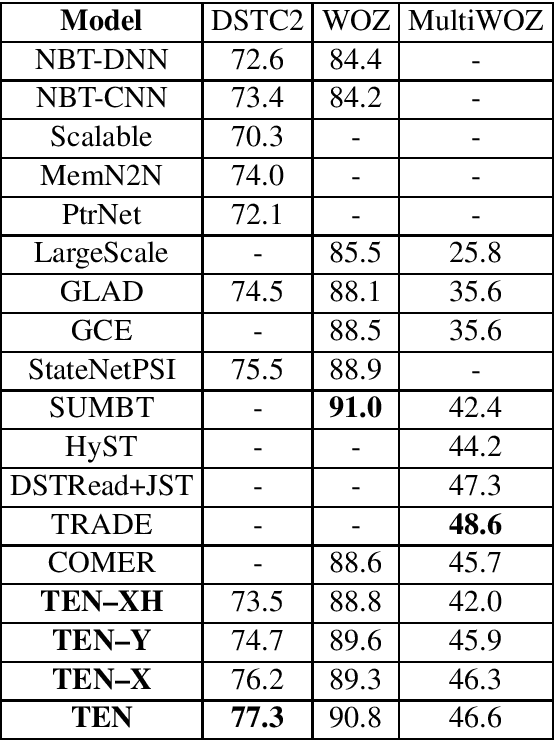
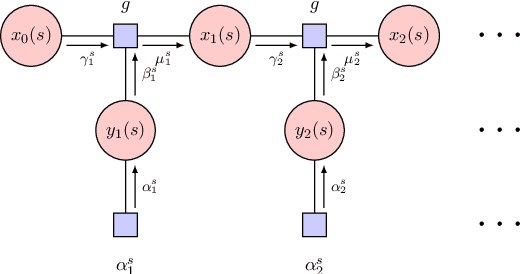
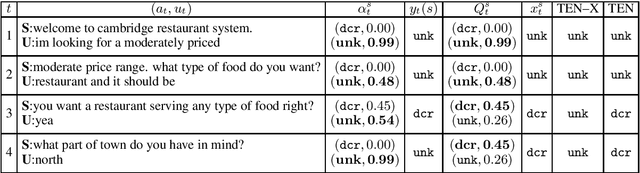
Dialogue state tracking (DST) is an important part of a spoken dialogue system. Existing DST models either ignore temporal feature dependencies across dialogue turns or fail to explicitly model temporal state dependencies in a dialogue. In this work, we propose Temporally Expressive Networks (TEN) to jointly model the two types of temporal dependencies in DST. The TEN model utilizes the power of recurrent networks and probabilistic graphical models. Evaluating on standard datasets, TEN is demonstrated to be effective in improving the accuracy of turn-level-state prediction and the state aggregation.