 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqPE: Transformer with Sequential Position Encoding
Jun 16, 2025Since self-attention layers in Transformers are permutation invariant by design, positional encodings must be explicitly incorporated to enable spatial understanding. However, fixed-size lookup tables used in traditional learnable position embeddings (PEs) limit extrapolation capabilities beyond pre-trained sequence lengths. Expert-designed methods such as ALiBi and RoPE, mitigate this limitation but demand extensive modifications for adapting to new modalities, underscoring fundamental challenges in adaptability and scalability. In this work, we present SeqPE, a unified and fully learnable position encoding framework that represents each $n$-dimensional position index as a symbolic sequence and employs a lightweight sequential position encoder to learn their embeddings in an end-to-end manner. To regularize SeqPE's embedding space, we introduce two complementary objectives: a contrastive objective that aligns embedding distances with a predefined position-distance function, and a knowledge distillation loss that anchors out-of-distribution position embeddings to in-distribution teacher representations, further enhancing extrapolation performance. Experiments across language modeling, long-context question answering, and 2D image classification demonstrate that SeqPE not only surpasses strong baselines in perplexity, exact match (EM), and accuracy--particularly under context length extrapolation--but also enables seamless generalization to multi-dimensional inputs without requiring manual architectural redesign. We release our code, data, and checkpoints at https://github.com/ghrua/seqpe.
Learning Hierarchical Interaction for Accurate Molecular Property Prediction
Apr 30, 2025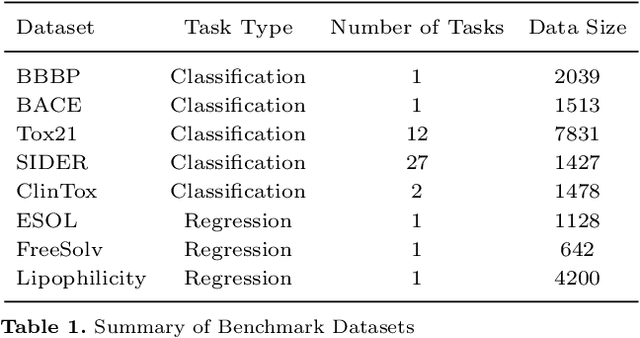
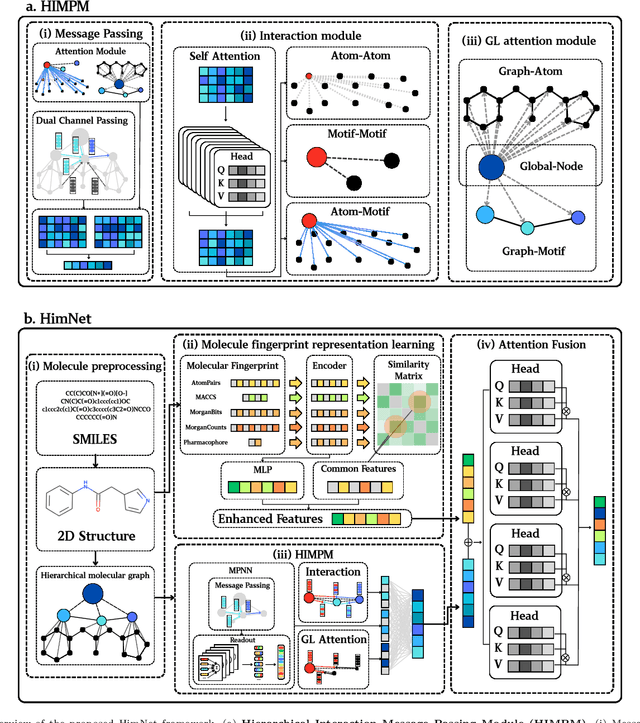
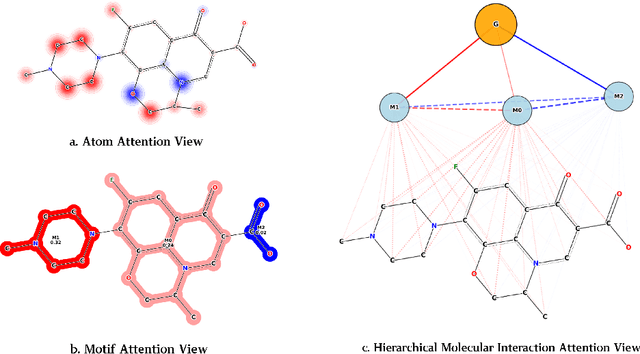
Discovering molecules with desirable molecular properties, including ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) profiles, is of great importance in drug discovery. Existing approaches typically employ deep learning models, such as Graph Neural Networks (GNNs) and Transformers, to predict these molecular properties by learning from diverse chemical information. However, these models often fail to efficiently capture and utilize the hierarchical nature of molecular structures, and lack mechanisms for effective interaction among multi-level features. To address these limitations, we propose a Hierarchical Interaction Message Passing Mechanism, which serves as the foundation of our novel model, HimNet. Our method enables interaction-aware representation learning across atomic, motif, and molecular levels via hierarchical attention-guided message passing. This design allows HimNet to effectively balance global and local information, ensuring rich and task-relevant feature extraction for downstream property prediction tasks, such as Blood-Brain Barrier Permeability (BBBP). Extensive experiments on multiple benchmark datasets demonstrate that HimNet achieves the best or near-best performance in most molecular property prediction tasks. Furthermore, our method exhibits promising hierarchical interpretability, aligning well with chemical intuition on representative molecules. We believe that HimNet offers an accurate and efficient solution for molecular activity and ADMET property prediction, contributing significantly to advanced decision-making in the early stages of drug discovery.
An ACO-MPC Framework for Energy-Efficient and Collision-Free Path Planning in Autonomous Maritime Navigation
Apr 22, 2025Automated driving on ramps presents significant challenges due to the need to balance both safety and efficiency during lane changes. This paper proposes an integrated planner for automated vehicles (AVs) on ramps, utilizing an unsatisfactory level metric for efficiency and arrow-cluster-based sampling for safety. The planner identifies optimal times for the AV to change lanes, taking into account the vehicle's velocity as a key factor in efficiency. Additionally, the integrated planner employs arrow-cluster-based sampling to evaluate collision risks and select an optimal lane-changing curve. Extensive simulations were conducted in a ramp scenario to verify the planner's efficient and safe performance. The results demonstrate that the proposed planner can effectively select an appropriate lane-changing time point and a safe lane-changing curve for AVs, without incurring any collisions during the maneuver.
KSHSeek: Data-Driven Approaches to Mitigating and Detecting Knowledge-Shortcut Hallucinations in Generative Models
Mar 25, 2025The emergence of large language models (LLMs) has significantly advanced the development of natural language processing (NLP), especially in text generation tasks like question answering. However, model hallucinations remain a major challenge in natural language generation (NLG) tasks due to their complex causes. We systematically expand on the causes of factual hallucinations from the perspective of knowledge shortcuts, analyzing hallucinations arising from correct and defect-free data and demonstrating that knowledge-shortcut hallucinations are prevalent in generative models. To mitigate this issue, we propose a high similarity pruning algorithm at the data preprocessing level to reduce spurious correlations in the data. Additionally, we design a specific detection method for knowledge-shortcut hallucinations to evaluate the effectiveness of our mitigation strategy. Experimental results show that our approach effectively reduces knowledge-shortcut hallucinations, particularly in fine-tuning tasks, without negatively impacting model performance in question answering. This work introduces a new paradigm for mitigating specific hallucination issues in generative models, enhancing their robustness and reliability in real-world applications.
Point-Cache: Test-time Dynamic and Hierarchical Cache for Robust and Generalizable Point Cloud Analysis
Mar 15, 2025This paper proposes a general solution to enable point cloud recognition models to handle distribution shifts at test time. Unlike prior methods, which rely heavily on training data-often inaccessible during online inference-and are limited to recognizing a fixed set of point cloud classes predefined during training, we explore a more practical and challenging scenario: adapting the model solely based on online test data to recognize both previously seen classes and novel, unseen classes at test time. To this end, we develop Point-Cache, a hierarchical cache model that captures essential clues of online test samples, particularly focusing on the global structure of point clouds and their local-part details. Point-Cache, which serves as a rich 3D knowledge base, is dynamically managed to prioritize the inclusion of high-quality samples. Designed as a plug-and-play module, our method can be flexibly integrated into large multimodal 3D models to support open-vocabulary point cloud recognition. Notably, our solution operates with efficiency comparable to zero-shot inference, as it is entirely training-free. Point-Cache demonstrates substantial gains across 8 challenging benchmarks and 4 representative large 3D models, highlighting its effectiveness. Code is available at https://github.com/auniquesun/Point-Cache.
FDLLM: A Text Fingerprint Detection Method for LLMs in Multi-Language, Multi-Domain Black-Box Environments
Jan 27, 2025



Using large language models (LLMs) integration platforms without transparency about which LLM is being invoked can lead to potential security risks. Specifically, attackers may exploit this black-box scenario to deploy malicious models and embed viruses in the code provided to users. In this context, it is increasingly urgent for users to clearly identify the LLM they are interacting with, in order to avoid unknowingly becoming victims of malicious models. However, existing studies primarily focus on mixed classification of human and machine-generated text, with limited attention to classifying texts generated solely by different models. Current research also faces dual bottlenecks: poor quality of LLM-generated text (LLMGT) datasets and limited coverage of detectable LLMs, resulting in poor detection performance for various LLMGT in black-box scenarios. We propose the first LLMGT fingerprint detection model, \textbf{FDLLM}, based on Qwen2.5-7B and fine-tuned using LoRA to address these challenges. FDLLM can more efficiently handle detection tasks across multilingual and multi-domain scenarios. Furthermore, we constructed a dataset named \textbf{FD-Datasets}, consisting of 90,000 samples that span multiple languages and domains, covering 20 different LLMs. Experimental results demonstrate that FDLLM achieves a macro F1 score 16.7\% higher than the best baseline method, LM-D.
OMG-HD: A High-Resolution AI Weather Model for End-to-End Forecasts from Observations
Dec 24, 2024



In recent years, Artificial Intelligence Weather Prediction (AIWP) models have achieved performance comparable to, or even surpassing, traditional Numerical Weather Prediction (NWP) models by leveraging reanalysis data. However, a less-explored approach involves training AIWP models directly on observational data, enhancing computational efficiency and improving forecast accuracy by reducing the uncertainties introduced through data assimilation processes. In this study, we propose OMG-HD, a novel AI-based regional high-resolution weather forecasting model designed to make predictions directly from observational data sources, including surface stations, radar, and satellite, thereby removing the need for operational data assimilation. Our evaluation shows that OMG-HD outperforms both the European Centre for Medium-Range Weather Forecasts (ECMWF)'s high-resolution operational forecasting system, IFS-HRES, and the High-Resolution Rapid Refresh (HRRR) model at lead times of up to 12 hours across the contiguous United States (CONUS) region. We achieve up to a 13% improvement on RMSE for 2-meter temperature, 17% on 10-meter wind speed, 48% on 2-meter specific humidity, and 32% on surface pressure compared to HRRR. Our method shows that it is possible to use AI-driven approaches for rapid weather predictions without relying on NWP-derived weather fields as model input. This is a promising step towards using observational data directly to make operational forecasts with AIWP models.
ADAF: An Artificial Intelligence Data Assimilation Framework for Weather Forecasting
Nov 25, 2024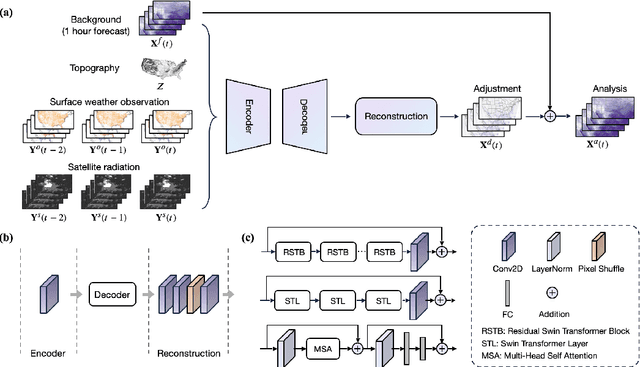



The forecasting skill of numerical weather prediction (NWP) models critically depends on the accurate initial conditions, also known as analysis, provided by data assimilation (DA). Traditional DA methods often face a trade-off between computational cost and accuracy due to complex linear algebra computations and the high dimensionality of the model, especially in nonlinear systems. Moreover, processing massive data in real-time requires substantial computational resources. To address this, we introduce an artificial intelligence-based data assimilation framework (ADAF) to generate high-quality kilometer-scale analysis. This study is the pioneering work using real-world observations from varied locations and multiple sources to verify the AI method's efficacy in DA, including sparse surface weather observations and satellite imagery. We implemented ADAF for four near-surface variables in the Contiguous United States (CONUS). The results indicate that ADAF surpasses the High Resolution Rapid Refresh Data Assimilation System (HRRRDAS) in accuracy by 16% to 33% for near-surface atmospheric conditions, aligning more closely with actual observations, and can effectively reconstruct extreme events, such as tropical cyclone wind fields. Sensitivity experiments reveal that ADAF can generate high-quality analysis even with low-accuracy backgrounds and extremely sparse surface observations. ADAF can assimilate massive observations within a three-hour window at low computational cost, taking about two seconds on an AMD MI200 graphics processing unit (GPU). ADAF has been shown to be efficient and effective in real-world DA, underscoring its potential role in operational weather forecasting.
Point-PRC: A Prompt Learning Based Regulation Framework for Generalizable Point Cloud Analysis
Oct 27, 2024This paper investigates the 3D domain generalization (3DDG) ability of large 3D models based on prevalent prompt learning. Recent works demonstrate the performances of 3D point cloud recognition can be boosted remarkably by parameter-efficient prompt tuning. However, we observe that the improvement on downstream tasks comes at the expense of a severe drop in 3D domain generalization. To resolve this challenge, we present a comprehensive regulation framework that allows the learnable prompts to actively interact with the well-learned general knowledge in large 3D models to maintain good generalization. Specifically, the proposed framework imposes multiple explicit constraints on the prompt learning trajectory by maximizing the mutual agreement between task-specific predictions and task-agnostic knowledge. We design the regulation framework as a plug-and-play module to embed into existing representative large 3D models. Surprisingly, our method not only realizes consistently increasing generalization ability but also enhances task-specific 3D recognition performances across various 3DDG benchmarks by a clear margin. Considering the lack of study and evaluation on 3DDG, we also create three new benchmarks, namely base-to-new, cross-dataset and few-shot generalization benchmarks, to enrich the field and inspire future research. Code and benchmarks are available at \url{https://github.com/auniquesun/Point-PRC}.
Beyond Film Subtitles: Is YouTube the Best Approximation of Spoken Vocabulary?
Oct 04, 2024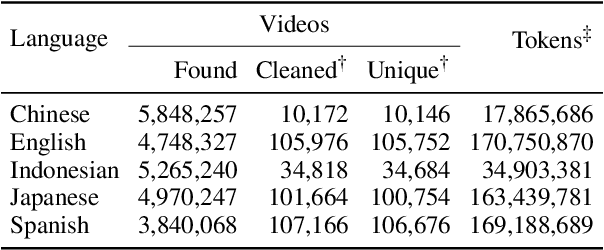
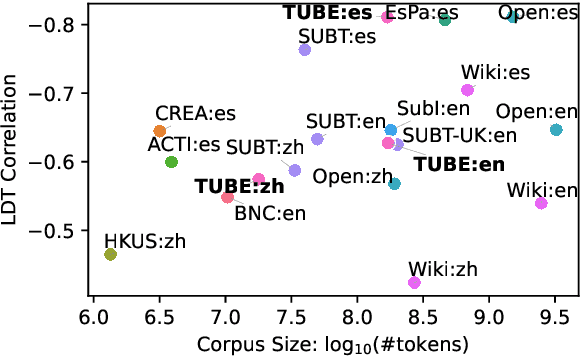
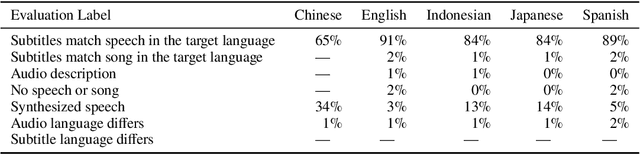
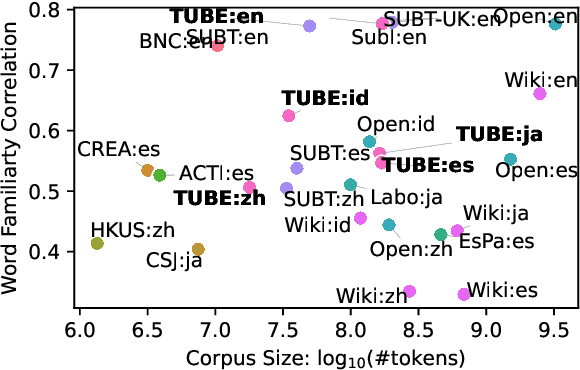
Word frequency is a key variable in psycholinguistics, useful for modeling human familiarity with words even in the era of large language models (LLMs). Frequency in film subtitles has proved to be a particularly good approximation of everyday language exposure. For many languages, however, film subtitles are not easily available, or are overwhelmingly translated from English. We demonstrate that frequencies extracted from carefully processed YouTube subtitles provide an approximation comparable to, and often better than, the best currently available resources. Moreover, they are available for languages for which a high-quality subtitle or speech corpus does not exist. We use YouTube subtitles to construct frequency norms for five diverse languages, Chinese, English, Indonesian, Japanese, and Spanish, and evaluate their correlation with lexical decision time, word familiarity, and lexical complexity. In addition to being strongly correlated with two psycholinguistic variables, a simple linear regression on the new frequencies achieves a new high score on a lexical complexity prediction task in English and Japanese, surpassing both models trained on film subtitle frequencies and the LLM GPT-4. Our code, the frequency lists, fastText word embeddings, and statistical language models are freely available at https://github.com/naist-nlp/tubelex.