 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillful high-resolution weather forecasting independent of physical models
May 27, 2026Accurate and timely weather forecasts are critical for high-impact decisions in modern society. Machine-learning-based weather prediction is emerging as an alternative for producing initial conditions, forecasts, and even both in end-to-end systems. These methods deliver predictions faster and often with higher skill than traditional numerical weather prediction (NWP). However, even end-to-end models typically rely on NWP-generated reanalyses for supervision, thereby inheriting the biases and resolution limitations of those NWPs, and limiting adaptation to settings where suitable reanalysis products are unavailable, infrequently updated, or expensive to produce. Here we introduce ObsCast, a regional system that generates both analysis and predictions, without using any NWP-derived data in either training or inference, while still achieving state-of-the-art performance in short-term high-resolution regional modeling. Over the contiguous United States and Europe, ObsCast outperforms operational NWP for near-surface variables through 18 h and produces skillful precipitation forecasts. It provides a simpler and more adaptable route to build and refine regional forecasting services directly from local observations, without the need to develop complex and costly traditional forecasting pipelines.
GroundingAnomaly: Spatially-Grounded Diffusion for Few-Shot Anomaly Synthesis
Apr 09, 2026The performance of visual anomaly inspection in industrial quality control is often constrained by the scarcity of real anomalous samples. Consequently, anomaly synthesis techniques have been developed to enlarge training sets and enhance downstream inspection. However, existing methods either suffer from poor integration caused by inpainting or fail to provide accurate masks. To address these limitations, we propose GroundingAnomaly, a novel few-shot anomaly image generation framework. Our framework introduces a Spatial Conditioning Module that leverages per-pixel semantic maps to enable precise spatial control over the synthesized anomalies. Furthermore, a Gated Self-Attention Module is designed to inject conditioning tokens into a frozen U-Net via gated attention layers. This carefully preserves pretrained priors while ensuring stable few-shot adaptation. Extensive evaluations on the MVTec AD and VisA datasets demonstrate that GroundingAnomaly generates high-quality anomalies and achieves state-of-the-art performance across multiple downstream tasks, including anomaly detection, segmentation, and instance-level detection.
Whisper-MLA: Reducing GPU Memory Consumption of ASR Models based on MHA2MLA Conversion
Feb 28, 2026The Transformer-based Whisper model has achieved state-of-the-art performance in Automatic Speech Recognition (ASR). However, its Multi-Head Attention (MHA) mechanism results in significant GPU memory consumption due to the linearly growing Key-Value (KV) cache usage, which is problematic for many applications especially with long-form audio. To address this, we introduce Whisper-MLA, a novel architecture that incorporates Multi-Head Latent Attention (MLA) into the Whisper model. Specifically, we adapt MLA for Whisper's absolute positional embeddings and systematically investigate its application across encoder self-attention, decoder self-attention, and cross-attention modules. Empirical results indicate that applying MLA exclusively to decoder self-attention yields the desired balance between performance and memory efficiency. Our proposed approach allows conversion of a pretrained Whisper model to Whisper-MLA with minimal fine-tuning. Extensive experiments on the LibriSpeech benchmark validate the effectiveness of this conversion, demonstrating that Whisper-MLA reduces the KV cache size by up to 87.5% while maintaining competitive accuracy.
LD-DETR: Loop Decoder DEtection TRansformer for Video Moment Retrieval and Highlight Detection
Jan 18, 2025Video Moment Retrieval and Highlight Detection aim to find corresponding content in the video based on a text query. Existing models usually first use contrastive learning methods to align video and text features, then fuse and extract multimodal information, and finally use a Transformer Decoder to decode multimodal information. However, existing methods face several issues: (1) Overlapping semantic information between different samples in the dataset hinders the model's multimodal aligning performance; (2) Existing models are not able to efficiently extract local features of the video; (3) The Transformer Decoder used by the existing model cannot adequately decode multimodal features. To address the above issues, we proposed the LD-DETR model for Video Moment Retrieval and Highlight Detection tasks. Specifically, we first distilled the similarity matrix into the identity matrix to mitigate the impact of overlapping semantic information. Then, we designed a method that enables convolutional layers to extract multimodal local features more efficiently. Finally, we fed the output of the Transformer Decoder back into itself to adequately decode multimodal information. We evaluated LD-DETR on four public benchmarks and conducted extensive experiments to demonstrate the superiority and effectiveness of our approach. Our model outperforms the State-Of-The-Art models on QVHighlight, Charades-STA and TACoS datasets. Our code is available at https://github.com/qingchen239/ld-detr.
OMG-HD: A High-Resolution AI Weather Model for End-to-End Forecasts from Observations
Dec 24, 2024



In recent years, Artificial Intelligence Weather Prediction (AIWP) models have achieved performance comparable to, or even surpassing, traditional Numerical Weather Prediction (NWP) models by leveraging reanalysis data. However, a less-explored approach involves training AIWP models directly on observational data, enhancing computational efficiency and improving forecast accuracy by reducing the uncertainties introduced through data assimilation processes. In this study, we propose OMG-HD, a novel AI-based regional high-resolution weather forecasting model designed to make predictions directly from observational data sources, including surface stations, radar, and satellite, thereby removing the need for operational data assimilation. Our evaluation shows that OMG-HD outperforms both the European Centre for Medium-Range Weather Forecasts (ECMWF)'s high-resolution operational forecasting system, IFS-HRES, and the High-Resolution Rapid Refresh (HRRR) model at lead times of up to 12 hours across the contiguous United States (CONUS) region. We achieve up to a 13% improvement on RMSE for 2-meter temperature, 17% on 10-meter wind speed, 48% on 2-meter specific humidity, and 32% on surface pressure compared to HRRR. Our method shows that it is possible to use AI-driven approaches for rapid weather predictions without relying on NWP-derived weather fields as model input. This is a promising step towards using observational data directly to make operational forecasts with AIWP models.
Multimodal Class-aware Semantic Enhancement Network for Audio-Visual Video Parsing
Dec 17, 2024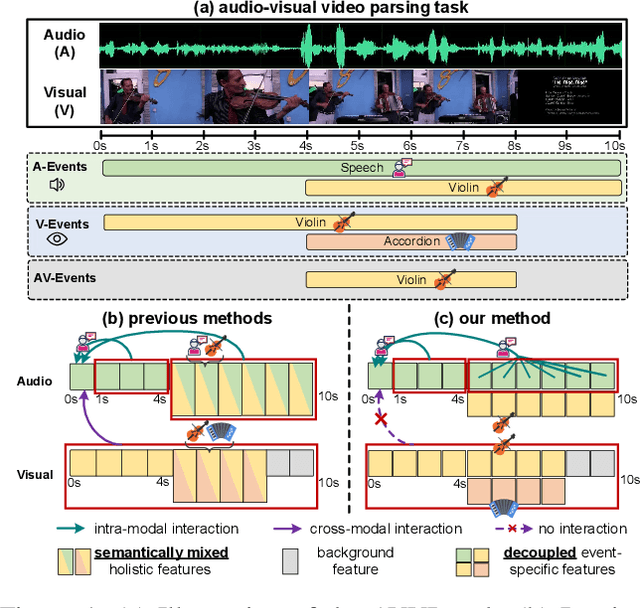
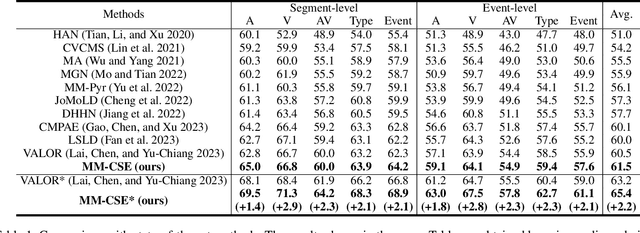
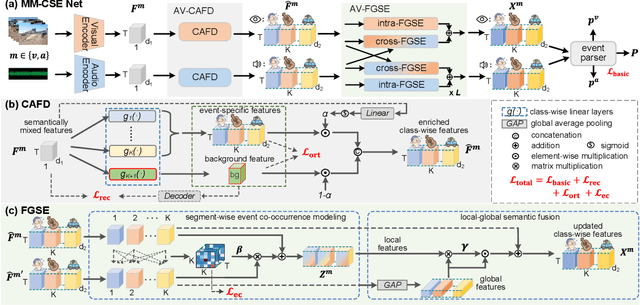
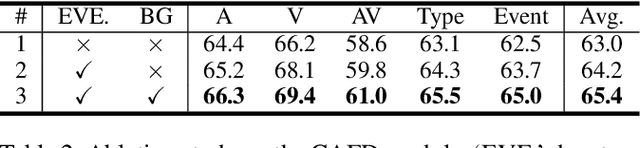
The Audio-Visual Video Parsing task aims to recognize and temporally localize all events occurring in either the audio or visual stream, or both. Capturing accurate event semantics for each audio/visual segment is vital. Prior works directly utilize the extracted holistic audio and visual features for intra- and cross-modal temporal interactions. However, each segment may contain multiple events, resulting in semantically mixed holistic features that can lead to semantic interference during intra- or cross-modal interactions: the event semantics of one segment may incorporate semantics of unrelated events from other segments. To address this issue, our method begins with a Class-Aware Feature Decoupling (CAFD) module, which explicitly decouples the semantically mixed features into distinct class-wise features, including multiple event-specific features and a dedicated background feature. The decoupled class-wise features enable our model to selectively aggregate useful semantics for each segment from clearly matched classes contained in other segments, preventing semantic interference from irrelevant classes. Specifically, we further design a Fine-Grained Semantic Enhancement module for encoding intra- and cross-modal relations. It comprises a Segment-wise Event Co-occurrence Modeling (SECM) block and a Local-Global Semantic Fusion (LGSF) block. The SECM exploits inter-class dependencies of concurrent events within the same timestamp with the aid of a new event co-occurrence loss. The LGSF further enhances the event semantics of each segment by incorporating relevant semantics from more informative global video features. Extensive experiments validate the effectiveness of the proposed modules and loss functions, resulting in a new state-of-the-art parsing performance.
ADAF: An Artificial Intelligence Data Assimilation Framework for Weather Forecasting
Nov 25, 2024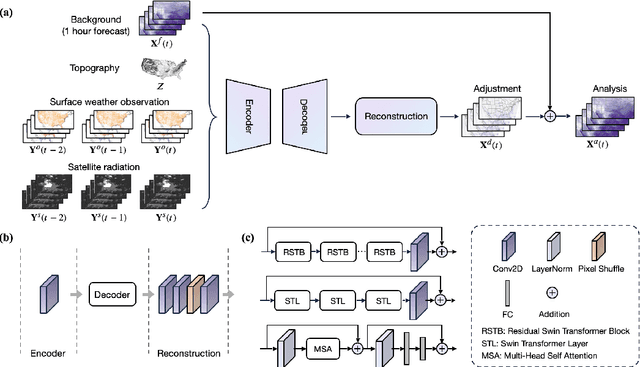



The forecasting skill of numerical weather prediction (NWP) models critically depends on the accurate initial conditions, also known as analysis, provided by data assimilation (DA). Traditional DA methods often face a trade-off between computational cost and accuracy due to complex linear algebra computations and the high dimensionality of the model, especially in nonlinear systems. Moreover, processing massive data in real-time requires substantial computational resources. To address this, we introduce an artificial intelligence-based data assimilation framework (ADAF) to generate high-quality kilometer-scale analysis. This study is the pioneering work using real-world observations from varied locations and multiple sources to verify the AI method's efficacy in DA, including sparse surface weather observations and satellite imagery. We implemented ADAF for four near-surface variables in the Contiguous United States (CONUS). The results indicate that ADAF surpasses the High Resolution Rapid Refresh Data Assimilation System (HRRRDAS) in accuracy by 16% to 33% for near-surface atmospheric conditions, aligning more closely with actual observations, and can effectively reconstruct extreme events, such as tropical cyclone wind fields. Sensitivity experiments reveal that ADAF can generate high-quality analysis even with low-accuracy backgrounds and extremely sparse surface observations. ADAF can assimilate massive observations within a three-hour window at low computational cost, taking about two seconds on an AMD MI200 graphics processing unit (GPU). ADAF has been shown to be efficient and effective in real-world DA, underscoring its potential role in operational weather forecasting.
WeatherReal: A Benchmark Based on In-Situ Observations for Evaluating Weather Models
Sep 14, 2024



In recent years, AI-based weather forecasting models have matched or even outperformed numerical weather prediction systems. However, most of these models have been trained and evaluated on reanalysis datasets like ERA5. These datasets, being products of numerical models, often diverge substantially from actual observations in some crucial variables like near-surface temperature, wind, precipitation and clouds - parameters that hold significant public interest. To address this divergence, we introduce WeatherReal, a novel benchmark dataset for weather forecasting, derived from global near-surface in-situ observations. WeatherReal also features a publicly accessible quality control and evaluation framework. This paper details the sources and processing methodologies underlying the dataset, and further illustrates the advantage of in-situ observations in capturing hyper-local and extreme weather through comparative analyses and case studies. Using WeatherReal, we evaluated several data-driven models and compared them with leading numerical models. Our work aims to advance the AI-based weather forecasting research towards a more application-focused and operation-ready approach.
QTG-VQA: Question-Type-Guided Architectural for VideoQA Systems
Sep 14, 2024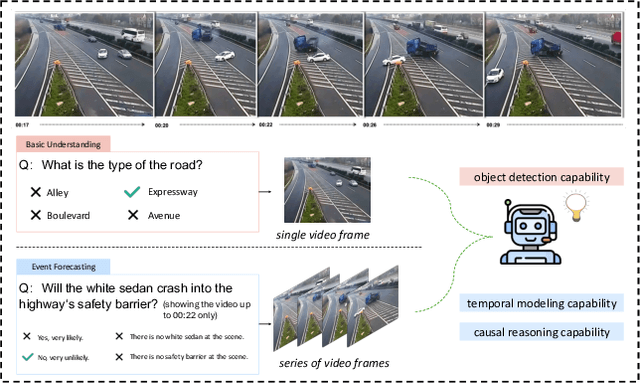
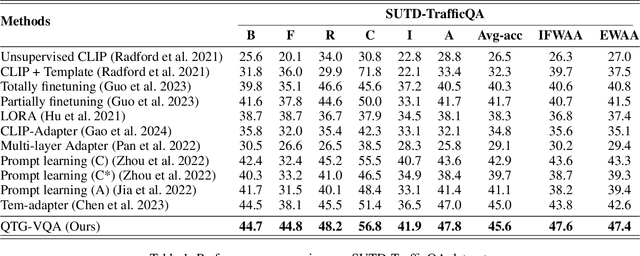
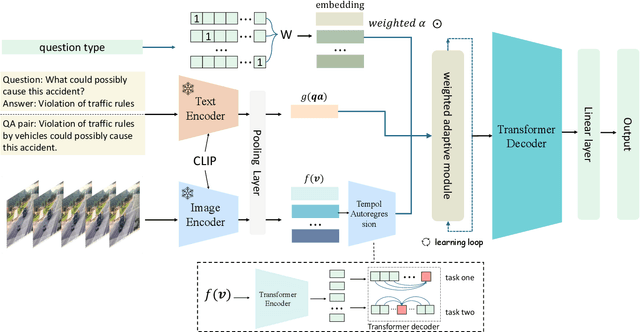
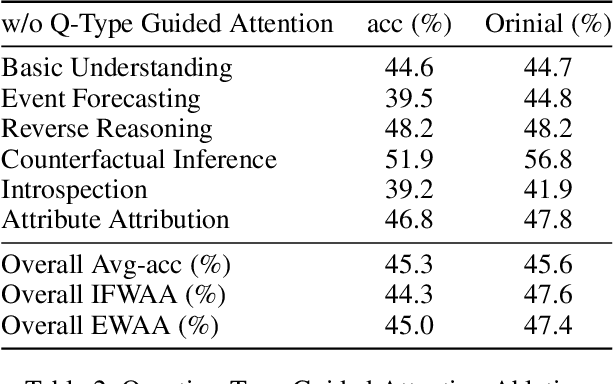
In the domain of video question answering (VideoQA), the impact of question types on VQA systems, despite its critical importance, has been relatively under-explored to date. However, the richness of question types directly determines the range of concepts a model needs to learn, thereby affecting the upper limit of its learning capability. This paper focuses on exploring the significance of different question types for VQA systems and their impact on performance, revealing a series of issues such as insufficient learning and model degradation due to uneven distribution of question types. Particularly, considering the significant variation in dependency on temporal information across different question types, and given that the representation of such information coincidentally represents a principal challenge and difficulty for VideoQA as opposed to ImageQA. To address these challenges, we propose QTG-VQA, a novel architecture that incorporates question-type-guided attention and adaptive learning mechanism. Specifically, as to temporal-type questions, we design Masking Frame Modeling technique to enhance temporal modeling, aimed at encouraging the model to grasp richer visual-language relationships and manage more intricate temporal dependencies. Furthermore, a novel evaluation metric tailored to question types is introduced. Experimental results confirm the effectiveness of our approach.
Audio-Infused Automatic Image Colorization by Exploiting Audio Scene Semantics
Jan 24, 2024



Automatic image colorization is inherently an ill-posed problem with uncertainty, which requires an accurate semantic understanding of scenes to estimate reasonable colors for grayscale images. Although recent interaction-based methods have achieved impressive performance, it is still a very difficult task to infer realistic and accurate colors for automatic colorization. To reduce the difficulty of semantic understanding of grayscale scenes, this paper tries to utilize corresponding audio, which naturally contains extra semantic information about the same scene. Specifically, a novel audio-infused automatic image colorization (AIAIC) network is proposed, which consists of three stages. First, we take color image semantics as a bridge and pretrain a colorization network guided by color image semantics. Second, the natural co-occurrence of audio and video is utilized to learn the color semantic correlations between audio and visual scenes. Third, the implicit audio semantic representation is fed into the pretrained network to finally realize the audio-guided colorization. The whole process is trained in a self-supervised manner without human annotation. In addition, an audiovisual colorization dataset is established for training and testing. Experiments demonstrate that audio guidance can effectively improve the performance of automatic colorization, especially for some scenes that are difficult to understand only from visual modality.