 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLD-DETR: Loop Decoder DEtection TRansformer for Video Moment Retrieval and Highlight Detection
Jan 18, 2025Video Moment Retrieval and Highlight Detection aim to find corresponding content in the video based on a text query. Existing models usually first use contrastive learning methods to align video and text features, then fuse and extract multimodal information, and finally use a Transformer Decoder to decode multimodal information. However, existing methods face several issues: (1) Overlapping semantic information between different samples in the dataset hinders the model's multimodal aligning performance; (2) Existing models are not able to efficiently extract local features of the video; (3) The Transformer Decoder used by the existing model cannot adequately decode multimodal features. To address the above issues, we proposed the LD-DETR model for Video Moment Retrieval and Highlight Detection tasks. Specifically, we first distilled the similarity matrix into the identity matrix to mitigate the impact of overlapping semantic information. Then, we designed a method that enables convolutional layers to extract multimodal local features more efficiently. Finally, we fed the output of the Transformer Decoder back into itself to adequately decode multimodal information. We evaluated LD-DETR on four public benchmarks and conducted extensive experiments to demonstrate the superiority and effectiveness of our approach. Our model outperforms the State-Of-The-Art models on QVHighlight, Charades-STA and TACoS datasets. Our code is available at https://github.com/qingchen239/ld-detr.
QTG-VQA: Question-Type-Guided Architectural for VideoQA Systems
Sep 14, 2024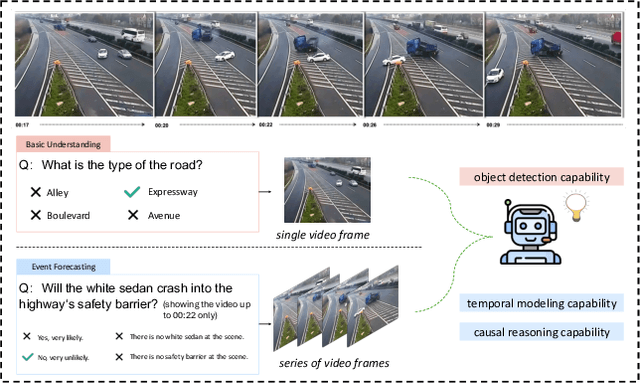
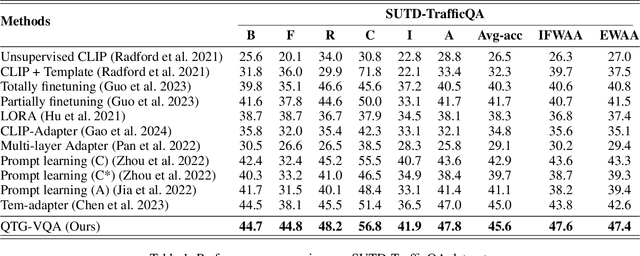
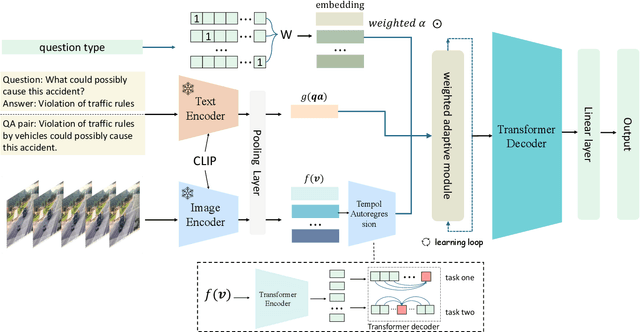
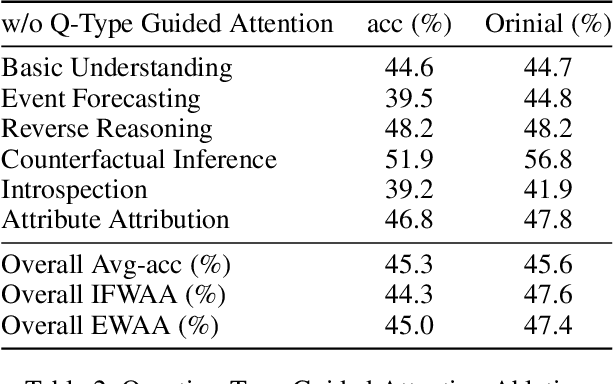
In the domain of video question answering (VideoQA), the impact of question types on VQA systems, despite its critical importance, has been relatively under-explored to date. However, the richness of question types directly determines the range of concepts a model needs to learn, thereby affecting the upper limit of its learning capability. This paper focuses on exploring the significance of different question types for VQA systems and their impact on performance, revealing a series of issues such as insufficient learning and model degradation due to uneven distribution of question types. Particularly, considering the significant variation in dependency on temporal information across different question types, and given that the representation of such information coincidentally represents a principal challenge and difficulty for VideoQA as opposed to ImageQA. To address these challenges, we propose QTG-VQA, a novel architecture that incorporates question-type-guided attention and adaptive learning mechanism. Specifically, as to temporal-type questions, we design Masking Frame Modeling technique to enhance temporal modeling, aimed at encouraging the model to grasp richer visual-language relationships and manage more intricate temporal dependencies. Furthermore, a novel evaluation metric tailored to question types is introduced. Experimental results confirm the effectiveness of our approach.
SFSegNet: Parse Freehand Sketches using Deep Fully Convolutional Networks
Aug 15, 2019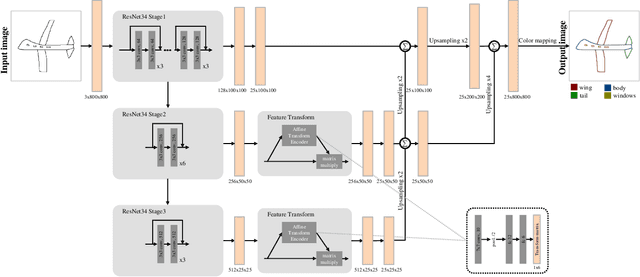
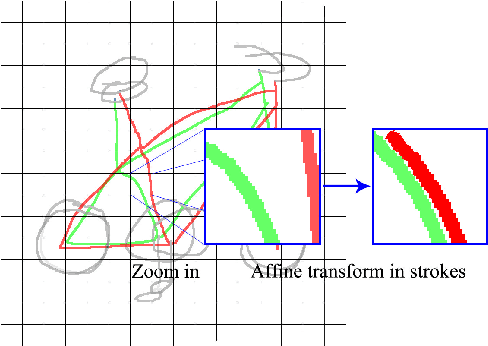
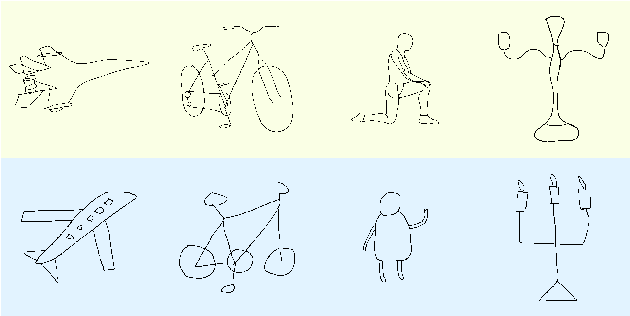
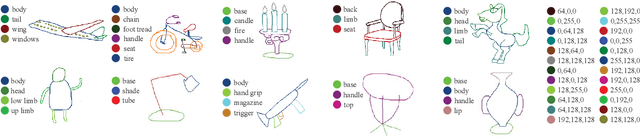
Parsing sketches via semantic segmentation is attractive but challenging, because (i) free-hand drawings are abstract with large variances in depicting objects due to different drawing styles and skills; (ii) distorting lines drawn on the touchpad make sketches more difficult to be recognized; (iii) the high-performance image segmentation via deep learning technologies needs enormous annotated sketch datasets during the training stage. In this paper, we propose a Sketch-target deep FCN Segmentation Network(SFSegNet) for automatic free-hand sketch segmentation, labeling each sketch in a single object with multiple parts. SFSegNet has an end-to-end network process between the input sketches and the segmentation results, composed of 2 parts: (i) a modified deep Fully Convolutional Network(FCN) using a reweighting strategy to ignore background pixels and classify which part each pixel belongs to; (ii) affine transform encoders that attempt to canonicalize the shaking strokes. We train our network with the dataset that consists of 10,000 annotated sketches, to find an extensively applicable model to segment stokes semantically in one ground truth. Extensive experiments are carried out and segmentation results show that our method outperforms other state-of-the-art networks.