 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQTG-VQA: Question-Type-Guided Architectural for VideoQA Systems
Paper and Code
Sep 14, 2024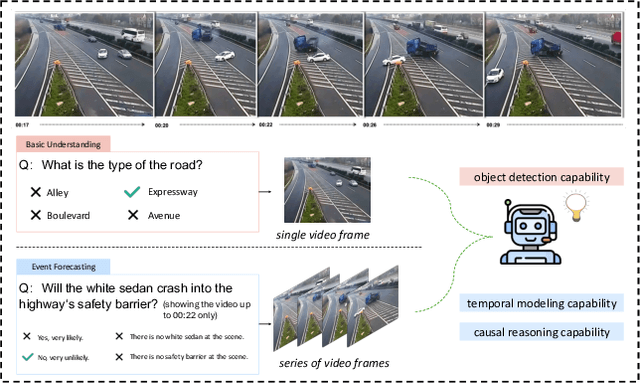
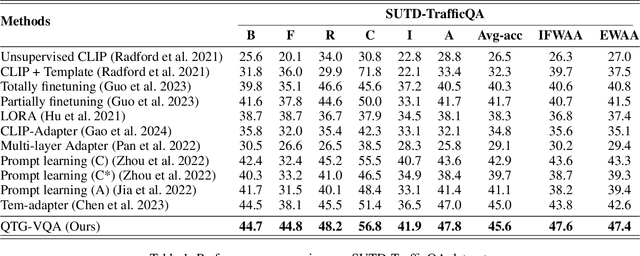
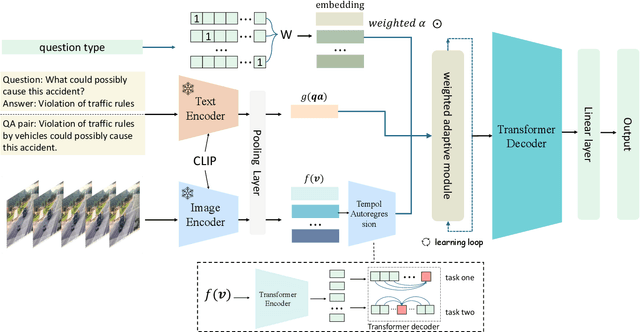
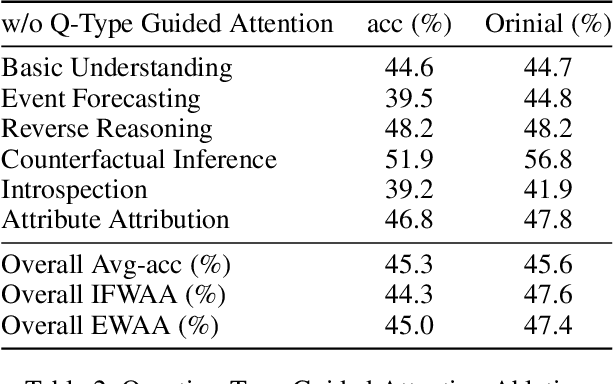
In the domain of video question answering (VideoQA), the impact of question types on VQA systems, despite its critical importance, has been relatively under-explored to date. However, the richness of question types directly determines the range of concepts a model needs to learn, thereby affecting the upper limit of its learning capability. This paper focuses on exploring the significance of different question types for VQA systems and their impact on performance, revealing a series of issues such as insufficient learning and model degradation due to uneven distribution of question types. Particularly, considering the significant variation in dependency on temporal information across different question types, and given that the representation of such information coincidentally represents a principal challenge and difficulty for VideoQA as opposed to ImageQA. To address these challenges, we propose QTG-VQA, a novel architecture that incorporates question-type-guided attention and adaptive learning mechanism. Specifically, as to temporal-type questions, we design Masking Frame Modeling technique to enhance temporal modeling, aimed at encouraging the model to grasp richer visual-language relationships and manage more intricate temporal dependencies. Furthermore, a novel evaluation metric tailored to question types is introduced. Experimental results confirm the effectiveness of our approach.