 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLD-DETR: Loop Decoder DEtection TRansformer for Video Moment Retrieval and Highlight Detection
Jan 18, 2025Video Moment Retrieval and Highlight Detection aim to find corresponding content in the video based on a text query. Existing models usually first use contrastive learning methods to align video and text features, then fuse and extract multimodal information, and finally use a Transformer Decoder to decode multimodal information. However, existing methods face several issues: (1) Overlapping semantic information between different samples in the dataset hinders the model's multimodal aligning performance; (2) Existing models are not able to efficiently extract local features of the video; (3) The Transformer Decoder used by the existing model cannot adequately decode multimodal features. To address the above issues, we proposed the LD-DETR model for Video Moment Retrieval and Highlight Detection tasks. Specifically, we first distilled the similarity matrix into the identity matrix to mitigate the impact of overlapping semantic information. Then, we designed a method that enables convolutional layers to extract multimodal local features more efficiently. Finally, we fed the output of the Transformer Decoder back into itself to adequately decode multimodal information. We evaluated LD-DETR on four public benchmarks and conducted extensive experiments to demonstrate the superiority and effectiveness of our approach. Our model outperforms the State-Of-The-Art models on QVHighlight, Charades-STA and TACoS datasets. Our code is available at https://github.com/qingchen239/ld-detr.
QTG-VQA: Question-Type-Guided Architectural for VideoQA Systems
Sep 14, 2024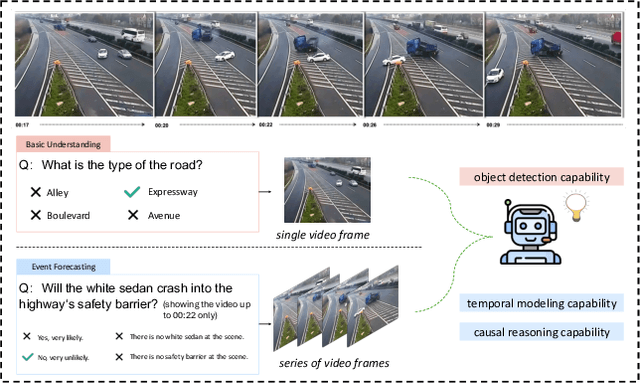
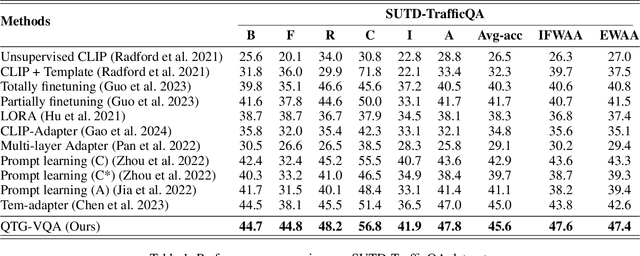
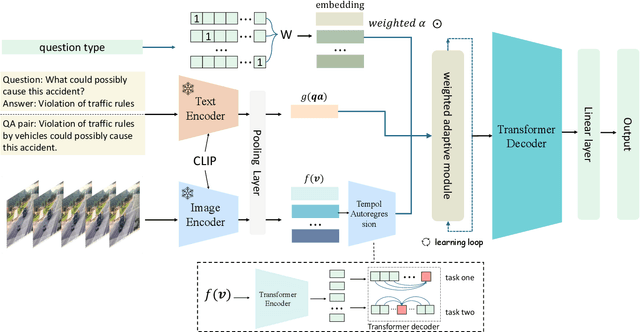
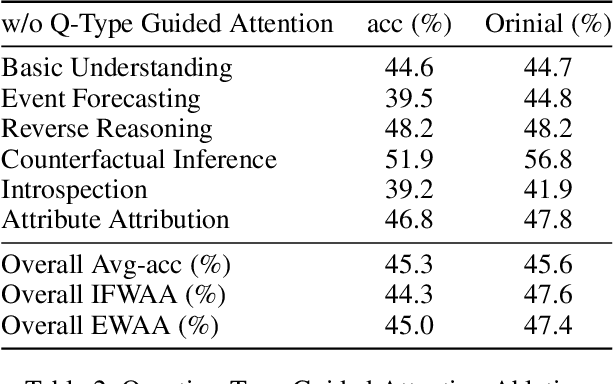
In the domain of video question answering (VideoQA), the impact of question types on VQA systems, despite its critical importance, has been relatively under-explored to date. However, the richness of question types directly determines the range of concepts a model needs to learn, thereby affecting the upper limit of its learning capability. This paper focuses on exploring the significance of different question types for VQA systems and their impact on performance, revealing a series of issues such as insufficient learning and model degradation due to uneven distribution of question types. Particularly, considering the significant variation in dependency on temporal information across different question types, and given that the representation of such information coincidentally represents a principal challenge and difficulty for VideoQA as opposed to ImageQA. To address these challenges, we propose QTG-VQA, a novel architecture that incorporates question-type-guided attention and adaptive learning mechanism. Specifically, as to temporal-type questions, we design Masking Frame Modeling technique to enhance temporal modeling, aimed at encouraging the model to grasp richer visual-language relationships and manage more intricate temporal dependencies. Furthermore, a novel evaluation metric tailored to question types is introduced. Experimental results confirm the effectiveness of our approach.
Text Guided Image Editing with Automatic Concept Locating and Forgetting
May 30, 2024
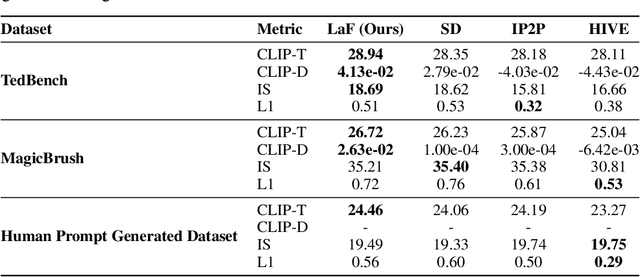

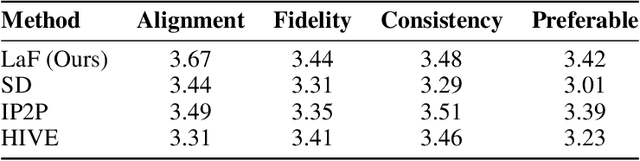
With the advancement of image-to-image diffusion models guided by text, significant progress has been made in image editing. However, a persistent challenge remains in seamlessly incorporating objects into images based on textual instructions, without relying on extra user-provided guidance. Text and images are inherently distinct modalities, bringing out difficulties in fully capturing the semantic intent conveyed through language and accurately translating that into the desired visual modifications. Therefore, text-guided image editing models often produce generations with residual object attributes that do not fully align with human expectations. To address this challenge, the models should comprehend the image content effectively away from a disconnect between the provided textual editing prompts and the actual modifications made to the image. In our paper, we propose a novel method called Locate and Forget (LaF), which effectively locates potential target concepts in the image for modification by comparing the syntactic trees of the target prompt and scene descriptions in the input image, intending to forget their existence clues in the generated image. Compared to the baselines, our method demonstrates its superiority in text-guided image editing tasks both qualitatively and quantitatively.