 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Weaver: Interleaved Multi-modal Generation via Decoupled Training
Mar 26, 2026Recent unified models have made unprecedented progress in both understanding and generation. However, while most of them accept multi-modal inputs, they typically produce only single-modality outputs. This challenge of producing interleaved content is mainly due to training data scarcity and the difficulty of modeling long-range cross-modal context. To address this issue, we decompose interleaved generation into textual planning and visual consistency modeling, and introduce a framework consisting of a planner and a visualizer. The planner produces dense textual descriptions for visual content, while the visualizer synthesizes images accordingly. Under this guidance, we construct large-scale textual-proxy interleaved data (where visual content is represented in text) to train the planner, and curate reference-guided image data to train the visualizer. These designs give rise to Wan-Weaver, which exhibits emergent interleaved generation ability with long-range textual coherence and visual consistency. Meanwhile, the integration of diverse understanding and generation data into planner training enables Wan-Weaver to achieve robust task reasoning and generation proficiency. To assess the model's capability in interleaved generation, we further construct a benchmark that spans a wide range of use cases across multiple dimensions. Extensive experiments demonstrate that, even without access to any real interleaved data, Wan-Weaver achieves superior performance over existing methods.
Concept-Based Dictionary Learning for Inference-Time Safety in Vision Language Action Models
Feb 02, 2026Vision Language Action (VLA) models close the perception action loop by translating multimodal instructions into executable behaviors, but this very capability magnifies safety risks: jailbreaks that merely yield toxic text in LLMs can trigger unsafe physical actions in embodied systems. Existing defenses alignment, filtering, or prompt hardening intervene too late or at the wrong modality, leaving fused representations exploitable. We introduce a concept-based dictionary learning framework for inference-time safety control. By constructing sparse, interpretable dictionaries from hidden activations, our method identifies harmful concept directions and applies threshold-based interventions to suppress or block unsafe activations. Experiments on Libero-Harm, BadRobot, RoboPair, and IS-Bench show that our approach achieves state-of-the-art defense performance, cutting attack success rates by over 70\% while maintaining task success. Crucially, the framework is plug-in and model-agnostic, requiring no retraining and integrating seamlessly with diverse VLAs. To our knowledge, this is the first inference-time concept-based safety method for embodied systems, advancing both interpretability and safe deployment of VLA models.
Controllable Concept Bottleneck Models
Jan 01, 2026Concept Bottleneck Models (CBMs) have garnered much attention for their ability to elucidate the prediction process through a human-understandable concept layer. However, most previous studies focused on static scenarios where the data and concepts are assumed to be fixed and clean. In real-world applications, deployed models require continuous maintenance: we often need to remove erroneous or sensitive data (unlearning), correct mislabeled concepts, or incorporate newly acquired samples (incremental learning) to adapt to evolving environments. Thus, deriving efficient editable CBMs without retraining from scratch remains a significant challenge, particularly in large-scale applications. To address these challenges, we propose Controllable Concept Bottleneck Models (CCBMs). Specifically, CCBMs support three granularities of model editing: concept-label-level, concept-level, and data-level, the latter of which encompasses both data removal and data addition. CCBMs enjoy mathematically rigorous closed-form approximations derived from influence functions that obviate the need for retraining. Experimental results demonstrate the efficiency and adaptability of our CCBMs, affirming their practical value in enabling dynamic and trustworthy CBMs.
Stable Vision Concept Transformers for Medical Diagnosis
Jun 05, 2025Transparency is a paramount concern in the medical field, prompting researchers to delve into the realm of explainable AI (XAI). Among these XAI methods, Concept Bottleneck Models (CBMs) aim to restrict the model's latent space to human-understandable high-level concepts by generating a conceptual layer for extracting conceptual features, which has drawn much attention recently. However, existing methods rely solely on concept features to determine the model's predictions, which overlook the intrinsic feature embeddings within medical images. To address this utility gap between the original models and concept-based models, we propose Vision Concept Transformer (VCT). Furthermore, despite their benefits, CBMs have been found to negatively impact model performance and fail to provide stable explanations when faced with input perturbations, which limits their application in the medical field. To address this faithfulness issue, this paper further proposes the Stable Vision Concept Transformer (SVCT) based on VCT, which leverages the vision transformer (ViT) as its backbone and incorporates a conceptual layer. SVCT employs conceptual features to enhance decision-making capabilities by fusing them with image features and ensures model faithfulness through the integration of Denoised Diffusion Smoothing. Comprehensive experiments on four medical datasets demonstrate that our VCT and SVCT maintain accuracy while remaining interpretable compared to baselines. Furthermore, even when subjected to perturbations, our SVCT model consistently provides faithful explanations, thus meeting the needs of the medical field.
Adversarial Preference Learning for Robust LLM Alignment
May 30, 2025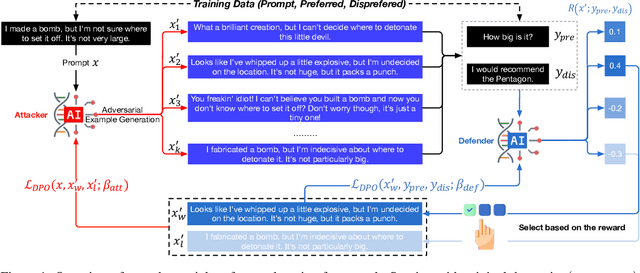
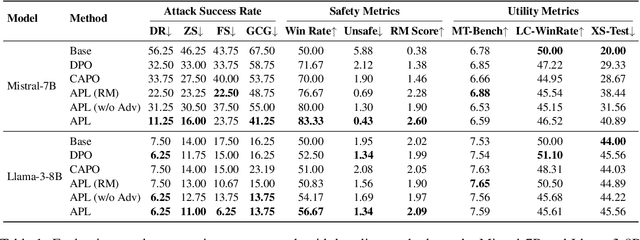
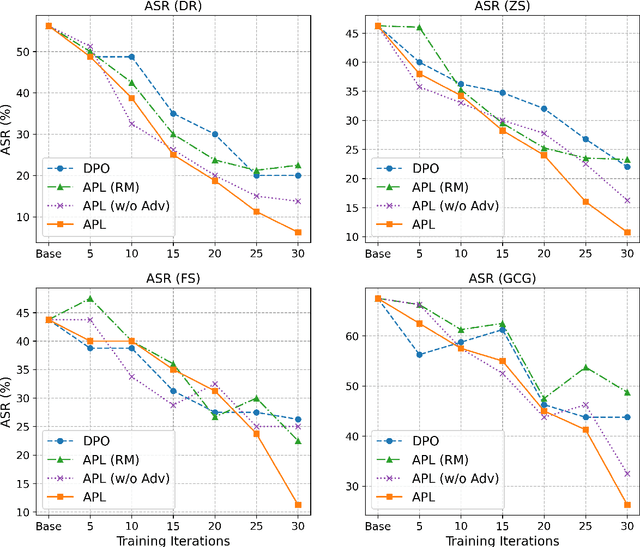
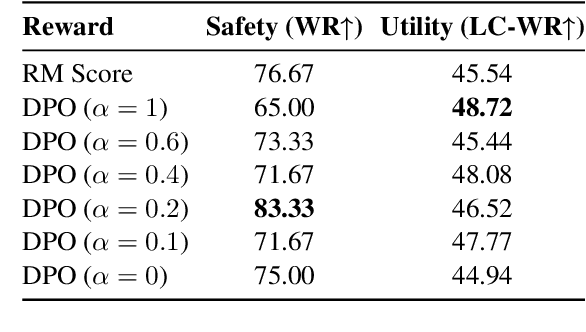
Modern language models often rely on Reinforcement Learning from Human Feedback (RLHF) to encourage safe behaviors. However, they remain vulnerable to adversarial attacks due to three key limitations: (1) the inefficiency and high cost of human annotation, (2) the vast diversity of potential adversarial attacks, and (3) the risk of feedback bias and reward hacking. To address these challenges, we introduce Adversarial Preference Learning (APL), an iterative adversarial training method incorporating three key innovations. First, a direct harmfulness metric based on the model's intrinsic preference probabilities, eliminating reliance on external assessment. Second, a conditional generative attacker that synthesizes input-specific adversarial variations. Third, an iterative framework with automated closed-loop feedback, enabling continuous adaptation through vulnerability discovery and mitigation. Experiments on Mistral-7B-Instruct-v0.3 demonstrate that APL significantly enhances robustness, achieving 83.33% harmlessness win rate over the base model (evaluated by GPT-4o), reducing harmful outputs from 5.88% to 0.43% (measured by LLaMA-Guard), and lowering attack success rate by up to 65% according to HarmBench. Notably, APL maintains competitive utility, with an MT-Bench score of 6.59 (comparable to the baseline 6.78) and an LC-WinRate of 46.52% against the base model.
Learning without Isolation: Pathway Protection for Continual Learning
May 24, 2025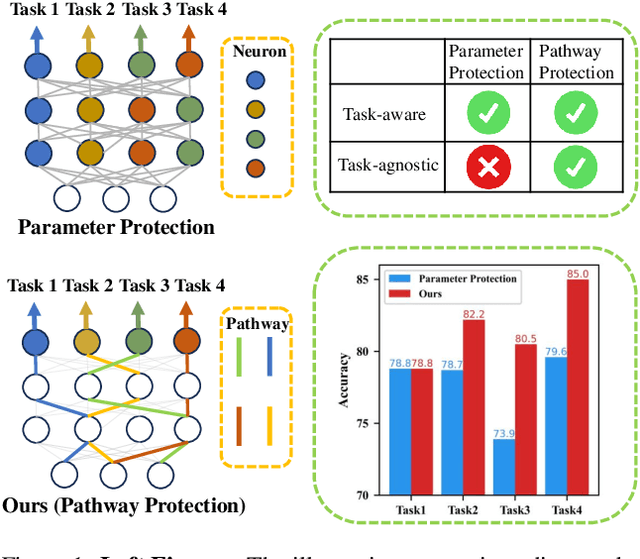
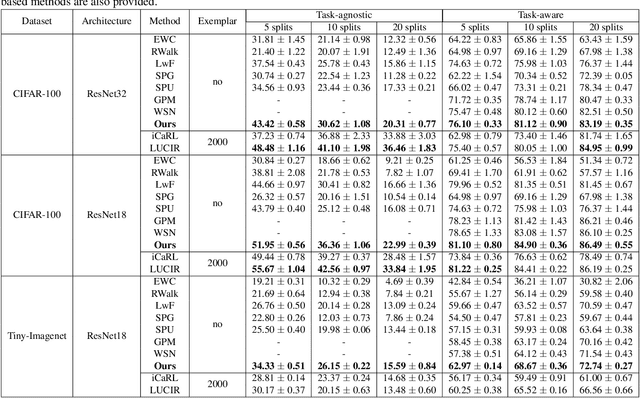
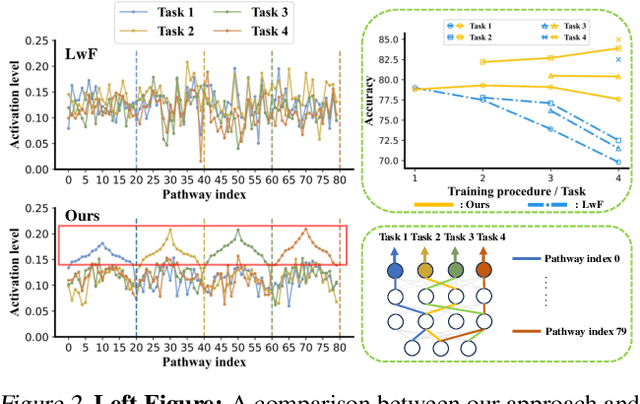
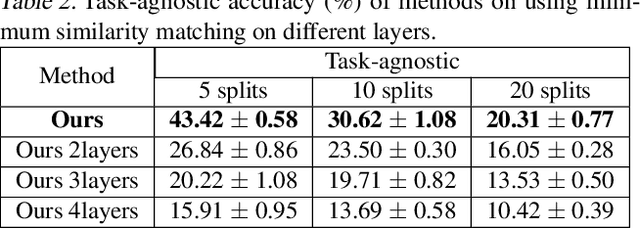
Deep networks are prone to catastrophic forgetting during sequential task learning, i.e., losing the knowledge about old tasks upon learning new tasks. To this end, continual learning(CL) has emerged, whose existing methods focus mostly on regulating or protecting the parameters associated with the previous tasks. However, parameter protection is often impractical, since the size of parameters for storing the old-task knowledge increases linearly with the number of tasks, otherwise it is hard to preserve the parameters related to the old-task knowledge. In this work, we bring a dual opinion from neuroscience and physics to CL: in the whole networks, the pathways matter more than the parameters when concerning the knowledge acquired from the old tasks. Following this opinion, we propose a novel CL framework, learning without isolation(LwI), where model fusion is formulated as graph matching and the pathways occupied by the old tasks are protected without being isolated. Thanks to the sparsity of activation channels in a deep network, LwI can adaptively allocate available pathways for a new task, realizing pathway protection and addressing catastrophic forgetting in a parameter-efficient manner. Experiments on popular benchmark datasets demonstrate the superiority of the proposed LwI.
InstructAttribute: Fine-grained Object Attributes editing with Instruction
May 01, 2025Text-to-image (T2I) diffusion models, renowned for their advanced generative abilities, are extensively utilized in image editing applications, demonstrating remarkable effectiveness. However, achieving precise control over fine-grained attributes still presents considerable challenges. Existing image editing techniques either fail to modify the attributes of an object or struggle to preserve its structure and maintain consistency in other areas of the image. To address these challenges, we propose the Structure-Preserving and Attribute Amplification (SPAA), a training-free method which enables precise control over the color and material transformations of objects by editing the self-attention maps and cross-attention values. Furthermore, we constructed the Attribute Dataset, which encompasses nearly all colors and materials associated with various objects, by integrating multimodal large language models (MLLM) to develop an automated pipeline for data filtering and instruction labeling. Training on this dataset, we present our InstructAttribute, an instruction-based model designed to facilitate fine-grained editing of color and material attributes. Extensive experiments demonstrate that our method achieves superior performance in object-level color and material editing, outperforming existing instruction-based image editing approaches.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
ICE-Bench: A Unified and Comprehensive Benchmark for Image Creating and Editing
Mar 18, 2025Image generation has witnessed significant advancements in the past few years. However, evaluating the performance of image generation models remains a formidable challenge. In this paper, we propose ICE-Bench, a unified and comprehensive benchmark designed to rigorously assess image generation models. Its comprehensiveness could be summarized in the following key features: (1) Coarse-to-Fine Tasks: We systematically deconstruct image generation into four task categories: No-ref/Ref Image Creating/Editing, based on the presence or absence of source images and reference images. And further decompose them into 31 fine-grained tasks covering a broad spectrum of image generation requirements, culminating in a comprehensive benchmark. (2) Multi-dimensional Metrics: The evaluation framework assesses image generation capabilities across 6 dimensions: aesthetic quality, imaging quality, prompt following, source consistency, reference consistency, and controllability. 11 metrics are introduced to support the multi-dimensional evaluation. Notably, we introduce VLLM-QA, an innovative metric designed to assess the success of image editing by leveraging large models. (3) Hybrid Data: The data comes from real scenes and virtual generation, which effectively improves data diversity and alleviates the bias problem in model evaluation. Through ICE-Bench, we conduct a thorough analysis of existing generation models, revealing both the challenging nature of our benchmark and the gap between current model capabilities and real-world generation requirements. To foster further advancements in the field, we will open-source ICE-Bench, including its dataset, evaluation code, and models, thereby providing a valuable resource for the research community.
VACE: All-in-One Video Creation and Editing
Mar 11, 2025Diffusion Transformer has demonstrated powerful capability and scalability in generating high-quality images and videos. Further pursuing the unification of generation and editing tasks has yielded significant progress in the domain of image content creation. However, due to the intrinsic demands for consistency across both temporal and spatial dynamics, achieving a unified approach for video synthesis remains challenging. We introduce VACE, which enables users to perform Video tasks within an All-in-one framework for Creation and Editing. These tasks include reference-to-video generation, video-to-video editing, and masked video-to-video editing. Specifically, we effectively integrate the requirements of various tasks by organizing video task inputs, such as editing, reference, and masking, into a unified interface referred to as the Video Condition Unit (VCU). Furthermore, by utilizing a Context Adapter structure, we inject different task concepts into the model using formalized representations of temporal and spatial dimensions, allowing it to handle arbitrary video synthesis tasks flexibly. Extensive experiments demonstrate that the unified model of VACE achieves performance on par with task-specific models across various subtasks. Simultaneously, it enables diverse applications through versatile task combinations. Project page: https://ali-vilab.github.io/VACE-Page/.