 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
ICE-Bench: A Unified and Comprehensive Benchmark for Image Creating and Editing
Mar 18, 2025Image generation has witnessed significant advancements in the past few years. However, evaluating the performance of image generation models remains a formidable challenge. In this paper, we propose ICE-Bench, a unified and comprehensive benchmark designed to rigorously assess image generation models. Its comprehensiveness could be summarized in the following key features: (1) Coarse-to-Fine Tasks: We systematically deconstruct image generation into four task categories: No-ref/Ref Image Creating/Editing, based on the presence or absence of source images and reference images. And further decompose them into 31 fine-grained tasks covering a broad spectrum of image generation requirements, culminating in a comprehensive benchmark. (2) Multi-dimensional Metrics: The evaluation framework assesses image generation capabilities across 6 dimensions: aesthetic quality, imaging quality, prompt following, source consistency, reference consistency, and controllability. 11 metrics are introduced to support the multi-dimensional evaluation. Notably, we introduce VLLM-QA, an innovative metric designed to assess the success of image editing by leveraging large models. (3) Hybrid Data: The data comes from real scenes and virtual generation, which effectively improves data diversity and alleviates the bias problem in model evaluation. Through ICE-Bench, we conduct a thorough analysis of existing generation models, revealing both the challenging nature of our benchmark and the gap between current model capabilities and real-world generation requirements. To foster further advancements in the field, we will open-source ICE-Bench, including its dataset, evaluation code, and models, thereby providing a valuable resource for the research community.
VACE: All-in-One Video Creation and Editing
Mar 11, 2025Diffusion Transformer has demonstrated powerful capability and scalability in generating high-quality images and videos. Further pursuing the unification of generation and editing tasks has yielded significant progress in the domain of image content creation. However, due to the intrinsic demands for consistency across both temporal and spatial dynamics, achieving a unified approach for video synthesis remains challenging. We introduce VACE, which enables users to perform Video tasks within an All-in-one framework for Creation and Editing. These tasks include reference-to-video generation, video-to-video editing, and masked video-to-video editing. Specifically, we effectively integrate the requirements of various tasks by organizing video task inputs, such as editing, reference, and masking, into a unified interface referred to as the Video Condition Unit (VCU). Furthermore, by utilizing a Context Adapter structure, we inject different task concepts into the model using formalized representations of temporal and spatial dimensions, allowing it to handle arbitrary video synthesis tasks flexibly. Extensive experiments demonstrate that the unified model of VACE achieves performance on par with task-specific models across various subtasks. Simultaneously, it enables diverse applications through versatile task combinations. Project page: https://ali-vilab.github.io/VACE-Page/.
ACE++: Instruction-Based Image Creation and Editing via Context-Aware Content Filling
Jan 07, 2025



We report ACE++, an instruction-based diffusion framework that tackles various image generation and editing tasks. Inspired by the input format for the inpainting task proposed by FLUX.1-Fill-dev, we improve the Long-context Condition Unit (LCU) introduced in ACE and extend this input paradigm to any editing and generation tasks. To take full advantage of image generative priors, we develop a two-stage training scheme to minimize the efforts of finetuning powerful text-to-image diffusion models like FLUX.1-dev. In the first stage, we pre-train the model using task data with the 0-ref tasks from the text-to-image model. There are many models in the community based on the post-training of text-to-image foundational models that meet this training paradigm of the first stage. For example, FLUX.1-Fill-dev deals primarily with painting tasks and can be used as an initialization to accelerate the training process. In the second stage, we finetune the above model to support the general instructions using all tasks defined in ACE. To promote the widespread application of ACE++ in different scenarios, we provide a comprehensive set of models that cover both full finetuning and lightweight finetuning, while considering general applicability and applicability in vertical scenarios. The qualitative analysis showcases the superiority of ACE++ in terms of generating image quality and prompt following ability. Code and models will be available on the project page: https://ali-vilab. github.io/ACE_plus_page/.
StyleBooth: Image Style Editing with Multimodal Instruction
Apr 18, 2024

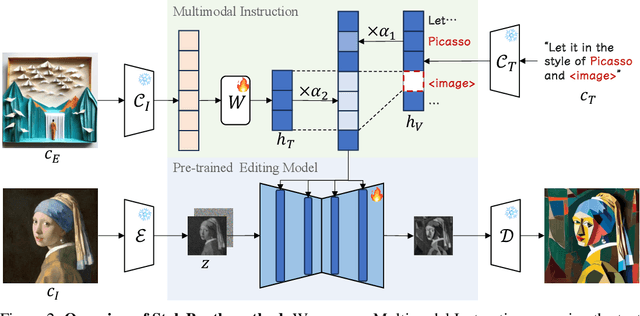

Given an original image, image editing aims to generate an image that align with the provided instruction. The challenges are to accept multimodal inputs as instructions and a scarcity of high-quality training data, including crucial triplets of source/target image pairs and multimodal (text and image) instructions. In this paper, we focus on image style editing and present StyleBooth, a method that proposes a comprehensive framework for image editing and a feasible strategy for building a high-quality style editing dataset. We integrate encoded textual instruction and image exemplar as a unified condition for diffusion model, enabling the editing of original image following multimodal instructions. Furthermore, by iterative style-destyle tuning and editing and usability filtering, the StyleBooth dataset provides content-consistent stylized/plain image pairs in various categories of styles. To show the flexibility of StyleBooth, we conduct experiments on diverse tasks, such as text-based style editing, exemplar-based style editing and compositional style editing. The results demonstrate that the quality and variety of training data significantly enhance the ability to preserve content and improve the overall quality of generated images in editing tasks. Project page can be found at https://ali-vilab.github.io/stylebooth-page/.
Locate, Assign, Refine: Taming Customized Image Inpainting with Text-Subject Guidance
Mar 28, 2024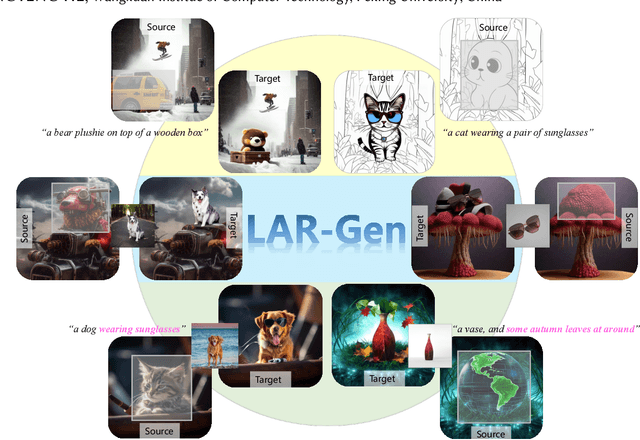
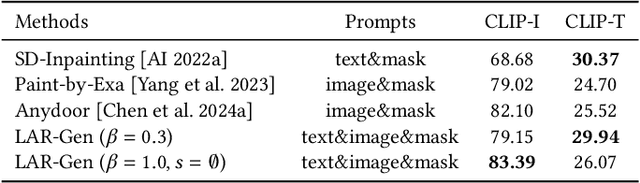
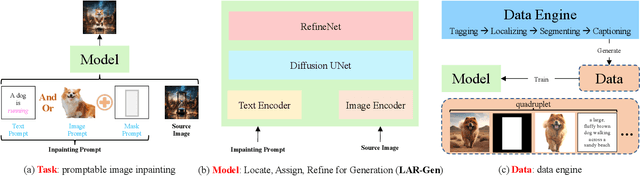
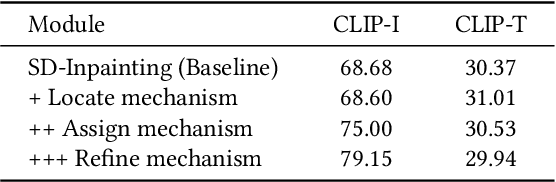
Prior studies have made significant progress in image inpainting guided by either text or subject image. However, the research on editing with their combined guidance is still in the early stages. To tackle this challenge, we present LAR-Gen, a novel approach for image inpainting that enables seamless inpainting of masked scene images, incorporating both the textual prompts and specified subjects. Our approach adopts a coarse-to-fine manner to ensure subject identity preservation and local semantic coherence. The process involves (i) Locate: concatenating the noise with masked scene image to achieve precise regional editing, (ii) Assign: employing decoupled cross-attention mechanism to accommodate multi-modal guidance, and (iii) Refine: using a novel RefineNet to supplement subject details. Additionally, to address the issue of scarce training data, we introduce a novel data construction pipeline. This pipeline extracts substantial pairs of data consisting of local text prompts and corresponding visual instances from a vast image dataset, leveraging publicly available large models. Extensive experiments and varied application scenarios demonstrate the superiority of LAR-Gen in terms of both identity preservation and text semantic consistency. Project page can be found at \url{https://ali-vilab.github.io/largen-page/}.
SCEdit: Efficient and Controllable Image Diffusion Generation via Skip Connection Editing
Dec 18, 2023Image diffusion models have been utilized in various tasks, such as text-to-image generation and controllable image synthesis. Recent research has introduced tuning methods that make subtle adjustments to the original models, yielding promising results in specific adaptations of foundational generative diffusion models. Rather than modifying the main backbone of the diffusion model, we delve into the role of skip connection in U-Net and reveal that hierarchical features aggregating long-distance information across encoder and decoder make a significant impact on the content and quality of image generation. Based on the observation, we propose an efficient generative tuning framework, dubbed SCEdit, which integrates and edits Skip Connection using a lightweight tuning module named SC-Tuner. Furthermore, the proposed framework allows for straightforward extension to controllable image synthesis by injecting different conditions with Controllable SC-Tuner, simplifying and unifying the network design for multi-condition inputs. Our SCEdit substantially reduces training parameters, memory usage, and computational expense due to its lightweight tuners, with backward propagation only passing to the decoder blocks. Extensive experiments conducted on text-to-image generation and controllable image synthesis tasks demonstrate the superiority of our method in terms of efficiency and performance. Project page: \url{https://scedit.github.io/}
A generalized likelihood-weighted optimal sampling algorithm for rare-event probability quantification
Oct 22, 2023In this work, we introduce a new acquisition function for sequential sampling to efficiently quantify rare-event statistics of an input-to-response (ItR) system with given input probability and expensive function evaluations. Our acquisition is a generalization of the likelihood-weighted (LW) acquisition that was initially designed for the same purpose and then extended to many other applications. The improvement in our acquisition comes from the generalized form with two additional parameters, by varying which one can target and address two weaknesses of the original LW acquisition: (1) that the input space associated with rare-event responses is not sufficiently stressed in sampling; (2) that the surrogate model (generated from samples) may have significant deviation from the true ItR function, especially for cases with complex ItR function and limited number of samples. In addition, we develop a critical procedure in Monte-Carlo discrete optimization of the acquisition function, which achieves orders of magnitude acceleration compared to existing approaches for such type of problems. The superior performance of our new acquisition to the original LW acquisition is demonstrated in a number of test cases, including some cases that were designed to show the effectiveness of the original LW acquisition. We finally apply our method to an engineering example to quantify the rare-event roll-motion statistics of a ship in a random sea.
Scanning Only Once: An End-to-end Framework for Fast Temporal Grounding in Long Videos
Mar 22, 2023



Video temporal grounding aims to pinpoint a video segment that matches the query description. Despite the recent advance in short-form videos (\textit{e.g.}, in minutes), temporal grounding in long videos (\textit{e.g.}, in hours) is still at its early stage. To address this challenge, a common practice is to employ a sliding window, yet can be inefficient and inflexible due to the limited number of frames within the window. In this work, we propose an end-to-end framework for fast temporal grounding, which is able to model an hours-long video with \textbf{one-time} network execution. Our pipeline is formulated in a coarse-to-fine manner, where we first extract context knowledge from non-overlapped video clips (\textit{i.e.}, anchors), and then supplement the anchors that highly response to the query with detailed content knowledge. Besides the remarkably high pipeline efficiency, another advantage of our approach is the capability of capturing long-range temporal correlation, thanks to modeling the entire video as a whole, and hence facilitates more accurate grounding. Experimental results suggest that, on the long-form video datasets MAD and Ego4d, our method significantly outperforms state-of-the-arts, and achieves \textbf{14.6$\times$} / \textbf{102.8$\times$} higher efficiency respectively. Project can be found at \url{https://github.com/afcedf/SOONet.git}.
Enhancing Unsupervised Audio Representation Learning via Adversarial Sample Generation
Mar 15, 2023Existing audio analysis methods generally first transform the audio stream to spectrogram, and then feed it into CNN for further analysis. A standard CNN recognizes specific visual patterns over feature map, then pools for high-level representation, which overlooks the positional information of recognized patterns. However, unlike natural image, the semantic of an audio spectrogram is sensitive to positional change, as its vertical and horizontal axes indicate the frequency and temporal information of the audio, instead of naive rectangular coordinates. Thus, the insensitivity of CNN to positional change plays a negative role on audio spectrogram encoding. To address this issue, this paper proposes a new self-supervised learning mechanism, which enhances the audio representation by first generating adversarial samples (\textit{i.e.}, negative samples), then driving CNN to distinguish the embeddings of negative pairs in the latent space. Extensive experiments show that the proposed approach achieves best or competitive results on 9 downstream datasets compared with previous methods, which verifies its effectiveness on audio representation learning.