 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRes-Tuning: A Flexible and Efficient Tuning Paradigm via Unbinding Tuner from Backbone
Oct 30, 2023Parameter-efficient tuning has become a trend in transferring large-scale foundation models to downstream applications. Existing methods typically embed some light-weight tuners into the backbone, where both the design and the learning of the tuners are highly dependent on the base model. This work offers a new tuning paradigm, dubbed Res-Tuning, which intentionally unbinds tuners from the backbone. With both theoretical and empirical evidence, we show that popular tuning approaches have their equivalent counterparts under our unbinding formulation, and hence can be integrated into our framework effortlessly. Thanks to the structural disentanglement, we manage to free the design of tuners from the network architecture, facilitating flexible combination of various tuning strategies. We further propose a memory-efficient variant of Res-Tuning, where the bypass i.e., formed by a sequence of tuners) is effectively detached from the main branch, such that the gradients are back-propagated only to the tuners but not to the backbone. Such a detachment also allows one-time backbone forward for multi-task inference. Extensive experiments on both discriminative and generative tasks demonstrate the superiority of our method over existing alternatives from the perspectives of efficacy and efficiency. Project page: $\href{https://res-tuning.github.io/}{\textit{https://res-tuning.github.io/}}$.
Logic Diffusion for Knowledge Graph Reasoning
Jun 06, 2023
Most recent works focus on answering first order logical queries to explore the knowledge graph reasoning via multi-hop logic predictions. However, existing reasoning models are limited by the circumscribed logical paradigms of training samples, which leads to a weak generalization of unseen logic. To address these issues, we propose a plug-in module called Logic Diffusion (LoD) to discover unseen queries from surroundings and achieves dynamical equilibrium between different kinds of patterns. The basic idea of LoD is relation diffusion and sampling sub-logic by random walking as well as a special training mechanism called gradient adaption. Besides, LoD is accompanied by a novel loss function to further achieve the robust logical diffusion when facing noisy data in training or testing sets. Extensive experiments on four public datasets demonstrate the superiority of mainstream knowledge graph reasoning models with LoD over state-of-the-art. Moreover, our ablation study proves the general effectiveness of LoD on the noise-rich knowledge graph.
Troika: Multi-Path Cross-Modal Traction for Compositional Zero-Shot Learning
Mar 27, 2023Recent compositional zero-shot learning (CZSL) methods adapt pre-trained vision-language models (VLMs) by constructing trainable prompts only for composed state-object pairs. Relying on learning the joint representation of seen compositions, these methods ignore the explicit modeling of the state and object, thus limiting the exploitation of pre-trained knowledge and generalization to unseen compositions. With a particular focus on the universality of the solution, in this work, we propose a novel paradigm for CZSL models that establishes three identification branches (i.e., Multi-Path) to jointly model the state, object, and composition. The presented Troika is our implementation that aligns the branch-specific prompt representations with decomposed visual features. To calibrate the bias between semantically similar multi-modal representations, we further devise a Cross-Modal Traction module into Troika that shifts the prompt representation towards the current visual content. We conduct extensive experiments on three popular benchmarks, where our method significantly outperforms existing methods in both closed-world and open-world settings.
Scanning Only Once: An End-to-end Framework for Fast Temporal Grounding in Long Videos
Mar 22, 2023



Video temporal grounding aims to pinpoint a video segment that matches the query description. Despite the recent advance in short-form videos (\textit{e.g.}, in minutes), temporal grounding in long videos (\textit{e.g.}, in hours) is still at its early stage. To address this challenge, a common practice is to employ a sliding window, yet can be inefficient and inflexible due to the limited number of frames within the window. In this work, we propose an end-to-end framework for fast temporal grounding, which is able to model an hours-long video with \textbf{one-time} network execution. Our pipeline is formulated in a coarse-to-fine manner, where we first extract context knowledge from non-overlapped video clips (\textit{i.e.}, anchors), and then supplement the anchors that highly response to the query with detailed content knowledge. Besides the remarkably high pipeline efficiency, another advantage of our approach is the capability of capturing long-range temporal correlation, thanks to modeling the entire video as a whole, and hence facilitates more accurate grounding. Experimental results suggest that, on the long-form video datasets MAD and Ego4d, our method significantly outperforms state-of-the-arts, and achieves \textbf{14.6$\times$} / \textbf{102.8$\times$} higher efficiency respectively. Project can be found at \url{https://github.com/afcedf/SOONet.git}.
Enhancing Unsupervised Audio Representation Learning via Adversarial Sample Generation
Mar 15, 2023Existing audio analysis methods generally first transform the audio stream to spectrogram, and then feed it into CNN for further analysis. A standard CNN recognizes specific visual patterns over feature map, then pools for high-level representation, which overlooks the positional information of recognized patterns. However, unlike natural image, the semantic of an audio spectrogram is sensitive to positional change, as its vertical and horizontal axes indicate the frequency and temporal information of the audio, instead of naive rectangular coordinates. Thus, the insensitivity of CNN to positional change plays a negative role on audio spectrogram encoding. To address this issue, this paper proposes a new self-supervised learning mechanism, which enhances the audio representation by first generating adversarial samples (\textit{i.e.}, negative samples), then driving CNN to distinguish the embeddings of negative pairs in the latent space. Extensive experiments show that the proposed approach achieves best or competitive results on 9 downstream datasets compared with previous methods, which verifies its effectiveness on audio representation learning.
ViM: Vision Middleware for Unified Downstream Transferring
Mar 13, 2023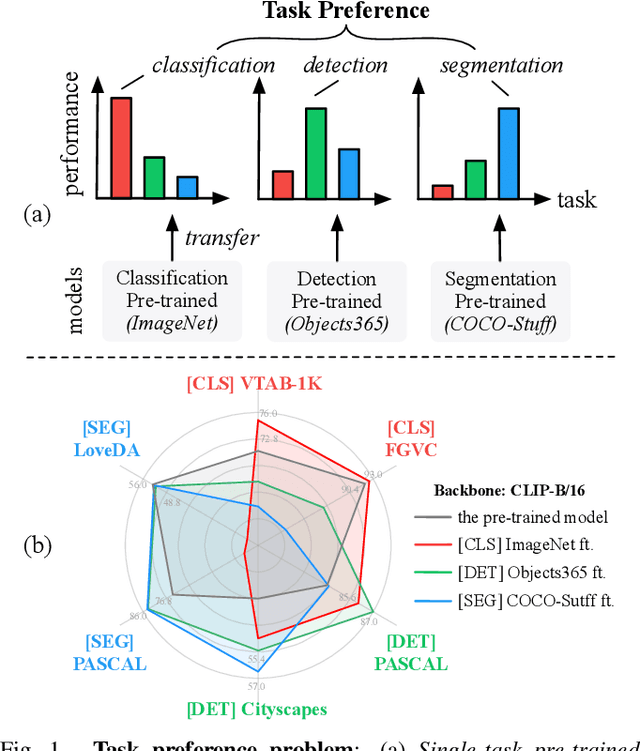
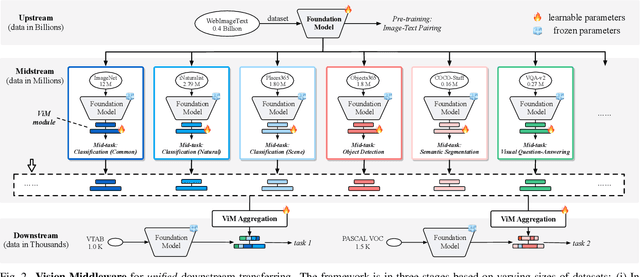
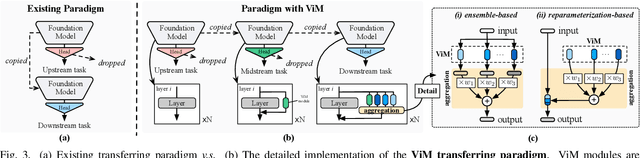
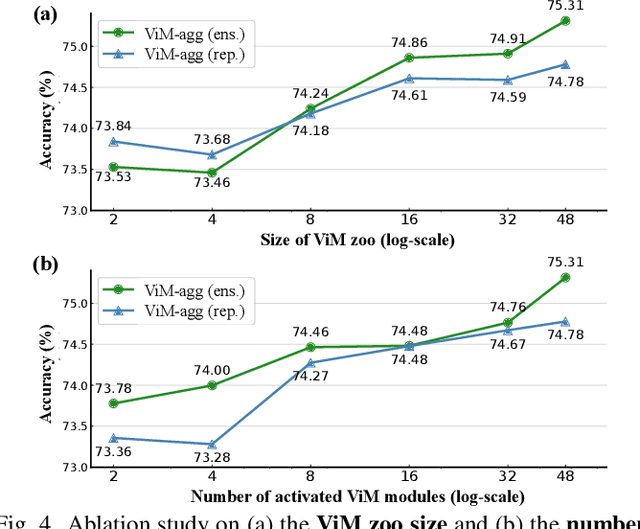
Foundation models are pre-trained on massive data and transferred to downstream tasks via fine-tuning. This work presents Vision Middleware (ViM), a new learning paradigm that targets unified transferring from a single foundation model to a variety of downstream tasks. ViM consists of a zoo of lightweight plug-in modules, each of which is independently learned on a midstream dataset with a shared frozen backbone. Downstream tasks can then benefit from an adequate aggregation of the module zoo thanks to the rich knowledge inherited from midstream tasks. There are three major advantages of such a design. From the efficiency aspect, the upstream backbone can be trained only once and reused for all downstream tasks without tuning. From the scalability aspect, we can easily append additional modules to ViM with no influence on existing modules. From the performance aspect, ViM can include as many midstream tasks as possible, narrowing the task gap between upstream and downstream. Considering these benefits, we believe that ViM, which the community could maintain and develop together, would serve as a powerful tool to assist foundation models.
Rethinking Efficient Tuning Methods from a Unified Perspective
Mar 01, 2023Parameter-efficient transfer learning (PETL) based on large-scale pre-trained foundation models has achieved great success in various downstream applications. Existing tuning methods, such as prompt, prefix, and adapter, perform task-specific lightweight adjustments to different parts of the original architecture. However, they take effect on only some parts of the pre-trained models, i.e., only the feed-forward layers or the self-attention layers, which leaves the remaining frozen structures unable to adapt to the data distributions of downstream tasks. Further, the existing structures are strongly coupled with the Transformers, hindering parameter-efficient deployment as well as the design flexibility for new approaches. In this paper, we revisit the design paradigm of PETL and derive a unified framework U-Tuning for parameter-efficient transfer learning, which is composed of an operation with frozen parameters and a unified tuner that adapts the operation for downstream applications. The U-Tuning framework can simultaneously encompass existing methods and derive new approaches for parameter-efficient transfer learning, which prove to achieve on-par or better performances on CIFAR-100 and FGVC datasets when compared with existing PETL methods.
UKnow: A Unified Knowledge Protocol for Common-Sense Reasoning and Vision-Language Pre-training
Feb 14, 2023



This work presents a unified knowledge protocol, called UKnow, which facilitates knowledge-based studies from the perspective of data. Particularly focusing on visual and linguistic modalities, we categorize data knowledge into five unit types, namely, in-image, in-text, cross-image, cross-text, and image-text. Following this protocol, we collect, from public international news, a large-scale multimodal knowledge graph dataset that consists of 1,388,568 nodes (with 571,791 vision-related ones) and 3,673,817 triplets. The dataset is also annotated with rich event tags, including 96 coarse labels and 9,185 fine labels, expanding its potential usage. To further verify that UKnow can serve as a standard protocol, we set up an efficient pipeline to help reorganize existing datasets under UKnow format. Finally, we benchmark the performance of some widely-used baselines on the tasks of common-sense reasoning and vision-language pre-training. Results on both our new dataset and the reformatted public datasets demonstrate the effectiveness of UKnow in knowledge organization and method evaluation. Code, dataset, conversion tool, and baseline models will be made public.
VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval
Nov 23, 2022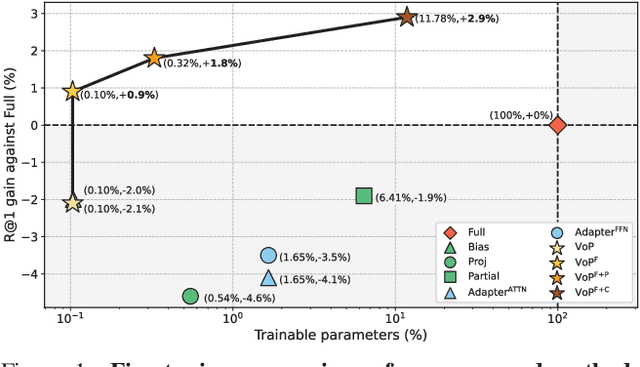
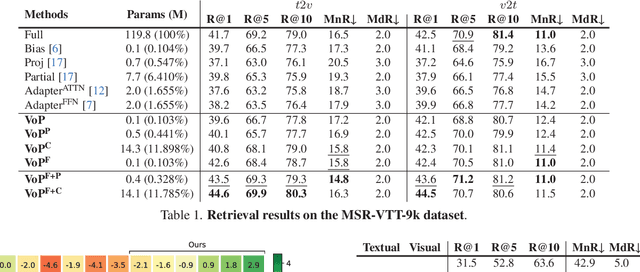
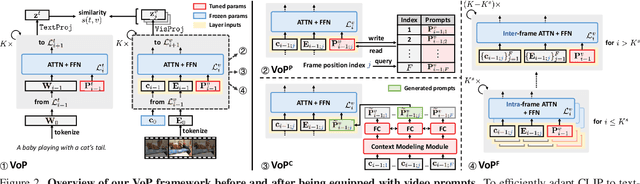
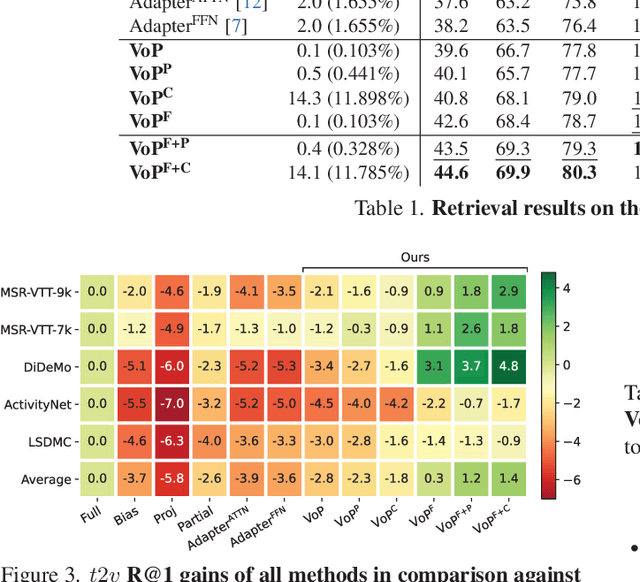
Many recent studies leverage the pre-trained CLIP for text-video cross-modal retrieval by tuning the backbone with additional heavy modules, which not only brings huge computational burdens with much more parameters, but also leads to the knowledge forgetting from upstream models.In this work, we propose the VoP: Text-Video Co-operative Prompt Tuning for efficient tuning on the text-video retrieval task. The proposed VoP is an end-to-end framework with both video & text prompts introducing, which can be regarded as a powerful baseline with only 0.1% trainable parameters. Further, based on the spatio-temporal characteristics of videos, we develop three novel video prompt mechanisms to improve the performance with different scales of trainable parameters. The basic idea of the VoP enhancement is to model the frame position, frame context, and layer function with specific trainable prompts, respectively. Extensive experiments show that compared to full fine-tuning, the enhanced VoP achieves a 1.4% average R@1 gain across five text-video retrieval benchmarks with 6x less parameter overhead. The code will be available at https://github.com/bighuang624/VoP.
MAR: Masked Autoencoders for Efficient Action Recognition
Jul 24, 2022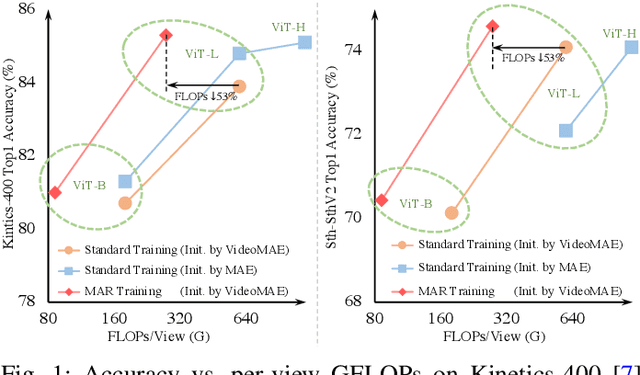
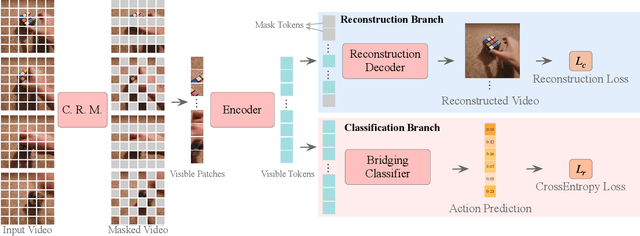
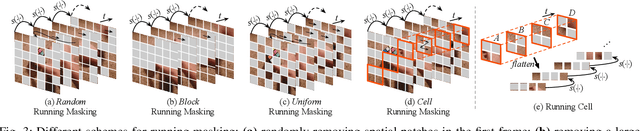
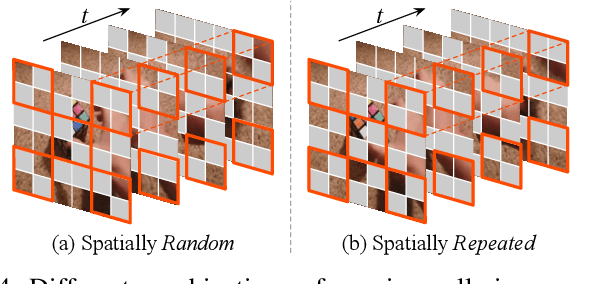
Standard approaches for video recognition usually operate on the full input videos, which is inefficient due to the widely present spatio-temporal redundancy in videos. Recent progress in masked video modelling, i.e., VideoMAE, has shown the ability of vanilla Vision Transformers (ViT) to complement spatio-temporal contexts given only limited visual contents. Inspired by this, we propose propose Masked Action Recognition (MAR), which reduces the redundant computation by discarding a proportion of patches and operating only on a part of the videos. MAR contains the following two indispensable components: cell running masking and bridging classifier. Specifically, to enable the ViT to perceive the details beyond the visible patches easily, cell running masking is presented to preserve the spatio-temporal correlations in videos, which ensures the patches at the same spatial location can be observed in turn for easy reconstructions. Additionally, we notice that, although the partially observed features can reconstruct semantically explicit invisible patches, they fail to achieve accurate classification. To address this, a bridging classifier is proposed to bridge the semantic gap between the ViT encoded features for reconstruction and the features specialized for classification. Our proposed MAR reduces the computational cost of ViT by 53% and extensive experiments show that MAR consistently outperforms existing ViT models with a notable margin. Especially, we found a ViT-Large trained by MAR outperforms the ViT-Huge trained by a standard training scheme by convincing margins on both Kinetics-400 and Something-Something v2 datasets, while our computation overhead of ViT-Large is only 14.5% of ViT-Huge.